



こんにちは。MA部MA施策推進ブロックの吉川です。
2025年4月9日〜11日に開催されたGoogle Cloud Next 2025へ参加してきました。去年に続きアメリカ・ラスベガスで開催され、弊社からはMA部の齋藤・吉川・富永の3名が参加しました。なお、去年参加した様子は以下のテックブログで紹介しています。
今年は生成AI、データ、セキュリティの最新情報を紹介したセッションが多かった印象でした。本記事では、現地での様子と特に興味深かったセッションをピックアップして紹介します。
また、今回のテックブログで紹介できなかった内容などを含め、Recapのオンラインイベントを2025/5/12に開催予定です。このイベントでは、Google Cloud Japanのエンジニアにもご登壇いただき、今回のGoogle Cloud Next 2025について詳しくお話いただきます。ぜひご参加ください。
現地の様子

去年に引き続きラスベガスのマンダレイ・ベイホテル コンベンションセンターで開催されました。世界中から多くのエンジニアやビジネスリーダーが集まり、会場は今年も未来を探る熱気に包まれました。

今年の基調講演では、特に進化が目覚ましい生成AIに関する新たな発表が相次ぎ、ビジネスへの具体的な活用事例とともに大きな注目を集めました。データとAIの統合をさらに推し進める新サービスに関するアップデートも紹介され、Google Cloudの進化を強く印象づけました。

各ブレイクアウトセッションやハンズオンラボも活況で、参加者は最新技術の習得や自社の課題解決のヒントを得ようと真剣に取り組んでいました。

企業ブースでは、Google Cloud自身のソリューションはもちろん、多くのパートナー企業によるデモンストレーションや事例紹介が行われ、活発なネットワーキング構築の様子があちこちで見られました。
数日間にわたるイベントを通して、参加者は最新情報をインプットするだけでなく、業界の専門家や他の参加者と直接交流することで、新たな知見やインスピレーションを得る貴重な機会となったようです。
以降では、現地に参加したメンバーが気になったセッションを紹介します。
セッション紹介
Accelerate creative media content with gen AI
MA部MA基盤ブロックの齋藤(@kyoppii13)です。
このセッションでは、生成AIを活用したメディアコンテンツの制作について紹介されました。最初にモデルを使った生成における指標についての紹介がありました。品質と安全性の2つです。
まずは品質です。品質とは、プロンプトで指示した通りの適切なスタイルでユーザーにとって魅力的な成果物が生成されることです。品質が悪いと、何度も指示する必要があり、それに伴い時間や金額的なコストが増加してしまいます。
次に安全性についてです。ここでは著作権の免責と電子透かし、安全フィルターについて述べられていました。著作権の免責はモデルの学習に著作権へ反したデータを使用しないことで実現しています。電子透かしは、Google DeepMindの技術であるSynthIDで実現していると述べられていました。モデルで生成されたコンテンツにこの透かしを入れることで、所有権や著作権を明確にするそうです。安全フィルターは有害なコンテンツを生成しないように、ユーザーが調整できるパラメータで安心してモデルを利用できます。ビジネスで使用する場合、著作権の対応は重要であるため、プラットフォームとして担保されていることは良いポイントだと思います。
次にクリエイティブのユースケースに使用できる生成モデルであるVeo 2、Imagen 3、Lyria、Chirp 3の4つのモデルについて紹介されました。まずはVeo 2です。これは動画生成のモデルで、与えられたテキストや画像から動画を生成できます。以下の機能について紹介されていました。
- Image to Video:与えられた画像からプロンプトの指示に従い動画を生成。
- Interpolation: 動画の最初と最後のフレームを与えるとその間を補完した動画を生成。
- Camera Movement Presets: 単一画像から指定したカメラアングルやショットの映像を生成。
- Inpainting & Outpainting: 元の動画を崩さずに動画内のオブジェクトの追加・削除を実現。Outpaintingのユースケースとしては、アスペクト比を変更し、複数のデバイスサイズに対応させるなど。

次にImagen 3です。これはテキストから画像を生成するモデルです。チャット形式でプロンプトを与えることで、画像に対してオブジェクトを追加・削除できます。

次にLyriaです。これはテキストから楽曲を生成するモデルです。最大30秒の楽曲を生成できます。

最後にChirp 3です。これは音声生成と文字起こしのモデルです。以下の機能について紹介されていました。
- HD Voices:入力されたテキストから相槌などを入れた自然な音声を作成。
- Instant Custom Voice:入力された音声からのカスタム音声の作成。
- Transcription with Diarization:複数人が話している音声から個人を識別し記録できる。ユースケースとして会議や通話の文字起こしがあげられていました。

ここで紹介した4つのモデルは、初日のキーノートでも大々的に発表されており、これらのモデルを組み合わせてステージ上で実際にコンテンツを作成していたのでとても印象に残っています。なかでもVeo2で作成された動画は今回多くの場面で見る機会があり印象的でした。キーノート会場での待ち時間や開始のカウントダウンでも投影されていました。
生成モデル紹介の次はユースケースについての紹介です。画像編集アプリ、マーケティング&広告、動画ストーリーテリングの3つの分野に分けて紹介されていました。紹介された3つの分野の中から、MAのユースケースに最も近いマーケティング&広告についてのみ紹介します。
これまで広告のマーケターは自分のイメージに近い画像をたくさんの画像の中から選ぶ必要がありましたが、画像生成モデルであるImagenを使うことで、理想の画像を1から作成できます。製品の撮影においても背景だけを変えることが出来るため様々な場所に自由に配置ができます。画像だけではなく、動画生成や音楽生成モデルを使うことで動画の広告も作成出来ると述べられていました。複数のシーンをそれぞれ作成しつなぎ合わせることで長い動画広告も作成できるそうです。

次にクラフト・ハインツ社のマーケティング事例についての紹介です。これまでどのように生成AIをマーケティングに利用してきたかと生成プロセスについて述べられていました。こちらの会社では自社のクリエイティブ作成に特化したクリエイティブ作成ツールを活用しているとのことでした。このツールの中でGoogleの生成AIを活用しているとのことです。このツールの開発に当たり、まずは以下のようなステップを実施したとのことです。
- Geminiによってマーケティングに必要なドキュメント(ブリーフ)を作成
- Imagenによるコンセプト画像の作成
- 1と2を組み合わせたクリエイティブ画像の作成
- Geminiによるクリエイティブの評価
- ImagenやVeoを用いた最終的なクリエイティブの作成
次に自社ブランドに関わる情報をどのようにツールに組み込むかという話がありました。RAG(Retrieval Augmented Generation)を使って優れたキャンペーンやスタイルガイド、消費者データなどを取り込んだとのことでした。RAGを使った理由は、時間と費用が削減出来るからだそうです。モデルのトレーニングが不要で、必要なデータを必要なタイミングで取り込めると述べられていました。
このツールを導入した結果、クリエイティブの作成フローが8週間から8時間になり、技術に詳しくないユーザーでも40倍の価値が生み出せると発表されていました。

Imagenは私たちMAの運用でも活用できると感じました。MA部では現在ZMP(ZOZO Marketing Platform)という基盤を開発しています。ZMPは施策担当者やマーケティング担当者のみでキャンペーン配信を実施できるようにするプラットフォームです。
詳しくは以下のテックブログをご覧ください。
コンテンツの作成においてImagenを活用することでクリエイティブ作成の幅が広がりそうだと感じました。また、パーソナライズ配信においては、ユーザーごとに好みをベクトルデータとして持っておけば、ユーザーごとに異なるデザインを配信時に自動で生成するなども出来ると思いました。
現在MAから配信しているコンテンツは画像しか利用しておりませんが、Veoなどのモデルを利用することで動画を使ったより視覚的なコンテンツを作成するなど、マーケティングにおける活用の幅は大いにあると思いました。
What’s new in BigQuery
MA部MA施策推進ブロックの吉川(@luckyriver)です。MA領域のマーケティング施策の運用とそれに関わる開発業務へ携わっています。今回参加したGoogle Cloud Next '25のセッションの中から、今後のマーケティング施策の運用・開発にどう影響しそうか、特に印象的だった点についてご紹介します。
今回のセッションでは、BigQueryの最新イノベーションとして、AIとの統合強化が大きなテーマとして語られていました。BigQueryは単なる「データウェアハウス」から、AI活用を前提とした、より賢くより多機能なデータプラットフォームへと大きく進化しています。セッションでは、この進化を「自律的なデータAIプラットフォーム」への移行として説明していました。
ここでいう「自律的」とは、将来的にBigQuery自体がデータ管理の最適化や問題の自動検知・修正などをある程度自ら行うようになることを指します。これにより、ユーザーは面倒な作業から解放され、データやAIを活用した新しい価値の創出により集中できるようになるのを目指しているとのことです。
BigQueryのプラットフォームとしての進化は、大きく以下の段階で整理できます。
- 構造化データを高速に分析するデータウェアハウスとしての誕生
- 非構造化データも扱えるレイクハウス要素の取り込み(多様なデータの一元管理・分析へ)
- AI(特にGemini)活用を前提としたデータ活用・分析プラットフォームへの進化

つまり、BigQueryはデータを貯める場所から、AIと共にデータを最大限に活用するための、インテリジェントな統合基盤へと進化していると考えられます。
今回のセッションでは、顧客事例として大手玩具メーカーのマテル社が紹介されました。同社はBigQuery MLとGeminiを活用し、大量の消費者レビュー分析において、データ分析の大幅な効率化、コスト削減、そしてデータに基づいた意思決定の迅速化を実現したとのことです。
マテル社では以前、世界中から集まる膨大な消費者フィードバック(製品レビューなど)を手作業(スプレッドシート等)で分類・集計していました。その作業に、数ヶ月単位の時間、金額的なコスト、ブランド間の比較が困難といった課題がありました。そこで同社は、BigQuery MLとGeminiを活用し、SQLをベースに消費者レビューのテキストを「トピック」「サブトピック」「属性」「センチメント(感情)」といった構造化されたデータへ自動で分類・変換するシステムをBigQuery内に構築し、既存のデータ処理パイプラインに組み込みました。
以下の例では、SQLベースでの消費者レビューをGeminiが解釈しJSON形式で出力する様子を表しています。

その結果、分析時間を「数ヶ月から1分」へと劇的に短縮し、外部ツール利用時と比較して年間100万ドル以上のコスト削減にも成功したそうです。さらに、全社で統一された基準により消費者インサイトを迅速に把握・比較できるようになり、製品改善やマーケティング戦略への活用が進んでいるとのことでした。
私たちZOZOTOWNでも商品ページにレビュー投稿できる機能を提供しています。このレビューを活用して、より精度の高い、ユーザー一人ひとりに合ったおすすめ商品をパーソナライズして訴求できる可能性があると考えています。しかし膨大なレビューデータかつ自然言語であるため、そのままの状態では「どの商品が」「どのような点(例:サイズ感、素材、デザイン、ブランド等)について」「どのように評価されているのか」といった情報を、大規模かつ体系的に分析・活用することが困難です。
そこで、私たちもマテル社の事例のように、AI(Geminiなど)を活用してレビューを構造化・定量的なデータに変換することで、レビュー解析の精度や網羅性を向上させられるのではと考えています。これにより、個々のユーザーの潜在的な好みや懸念点をより深く理解し、商品レコメンデーションやUI/UXの改善に繋げていける可能性があると考えています。
Gemini in BigQuery: Your AI assistant for transforming your data workflows
BigQueryとGeminiの統合がどのようにデータ活用やAI開発を加速させ、どのような価値をもたらしているか、顧客事例を交えてご紹介します。
英国の通信会社であるVirgin Media O2社ではデータチームへの依存、手作業による非効率、データのサイロ化といった課題がありました。そこで同社はBigQueryの各種AI支援機能(Data Preparation・Data Canvas・コード生成等)を活用し、専門知識がなくてもデータ準備から分析、可視化までを容易に行える環境を整備しました。例えば、SQLからGeminiを呼び出してサポートチケットの重要情報(いつ・だれが・どこで・なにを)を自動抽出する、といった活用例も紹介されました。これにより、作業工数の大幅な削減(手作業で80%以上、エンジニア負荷で30%以上)が見込まれています。

また、食品会社のGeneral Mills社は、AI時代のデータ需要増大への対応や開発効率化のため、Geminiのコード支援機能を導入し、開発者の生産性向上を実現しています。例えば、SQLのコメントに自然言語でビジネスロジックを書くと、GeminiがSQL文に変換してくれる機能などが紹介されました。これにより、SQLの調査や学習にかかるコスト削減が期待できます。
私たちZOZOTOWNにおいても、集計やユーザーターゲティングのためのSQL作成時に、膨大なデータを理解し扱う必要があり、これに多くの時間と手間がかかっています。Geminiによるコード支援機能を活用すれば、SQL作成・運用に関わる多くのステップが効率化され、時間と手間を大幅に削減できることが期待されます。これにより、マーケターやアナリストはより迅速にデータインサイトを発見し、効果的な施策の立案・実行に集中でき、結果としてマーケティング施策のPDCAサイクルをさらに高速化できる可能性があると考えています。
Enterprise-grade security and scale for serverless workloads with Cloud Run
MA部MA基盤ブロックの富永(@turbofish_)です。私からは、アプリケーション開発に関連する新機能へフォーカスしてご紹介します。
このセッションでは、前半はCloud Runのエンタープライズ対応における進化と最新機能について、後半はKubernetesとCloud Runを比較しCloud Runが採用された顧客事例のケーススタディが説明されました。
Cloud Runとは、Google Cloudが提供するフルマネージドなサーバーレスコンテナプラットフォームです。VMなどの管理をすることなくスケーラブルなインフラストラクチャを享受できるため、開発チームはシンプルな運用で高いベロシティを実現できます。まずは発表された内容をまとめ、その後に著者が気になった点についてピックアップしてお話しします。
エンタープライズ対応におけるCloud Runの特徴
1. セキュリティとコンプライアンス
- 2層のサンドボックスによるセキュアな実行環境
- データ暗号化とトラフィックへのアクセス制御
- FedRAMP High、HIPAAなどの米国におけるセキュリティ認証を取得済み
- IAMやVPCの統合により、既存のセキュリティアーキテクチャと連携可能
2. 多様なワークロード対応
- AI推論、Webサービス、APIバックエンド、データ処理など幅広い用途に対応
- 公開もしくは非公開、規模の大小に関わらず、様々なアプリケーションに対応
- スタートアップ時間が長いアプリ(例:Spring Boot)にも対応可能
3. コスト効率
- トラフィックに応じた自動スケーリング/ゼロスケールで無駄なコスト削減
- ゾーン冗長性がデフォルトで提供され、過剰なリソース確保が不要
- 複数の課金モードやコミットメント割引も利用可能
2025年のエンタープライズ向け新機能ハイライト
- Vertex AI × Cloud RunでAIアプリをサーバーレスで運用
- GPUサポートがGA。5秒で起動可能
- Direct VPC Egressが強化され、スピード、信頼性、コストで優位
- Cloud RunインスタンスにVPC直結のIPを付与
- Identity-Aware Proxy(IAP)の組み込み
- ロードバランサーなしで直接Cloud Runへアクセスできるようになる
- マルチリージョンデプロイとフェイルオーバー
- 今後、クロスリージョンフェイルオーバー機能(readiness probeに基づく)も提供予定
- Cloud Run Worker Pools(まもなく提供予定)
Cloud Runのエンタープライズ活用

最近では、Vertex AIにモデルをホスティングし、フロントエンドをCloud Runで構成するアーキテクチャがよく見られるとのことです。2024年にCloud StorageバケットをCloud Runコンテナ内のファイルとしてマウント可能になりましたが、これによってAIモデル、メディア、構成ファイルの取り扱いが容易になりました。
上記の発表の中でも特に私が気になったものとして、Cloud Run Worker Poolsという、常時ポーリング型処理に特化した構成が新たに発表されました。Worker Poolsは、Kafkaなどの非リクエストベースのワークロードに対応する新リソースとして、APIリクエストを受信せず、CPU使用率によってオートスケールできます。常時稼働ワーカー専用に設計されているため、より効率的な料金体系が適用され、アイドル時のコスト懸念が軽減されているそうです。私が所属するMA部でも、処理をexactly onceにするためにPub/Subのpullサブスクリプションを起点としたサービスを作成するなど、非リクエストベースのワークロードが複数存在しています。そのため、このような機能が欲しいと度々話していたので、個人的にはとても嬉しい発表でした。
関係して、最近MA部で行ったメール配信システムの大幅なリアーキテクチャで、要件に合わせて様々な設定のCloud Runを使用しジョブキューで連携させることにより、柔軟でスケーラブルな配信システムを実現できました。アーキテクチャについて説明したテックブログを公開していますので、こちらもぜひご一読ください。
セッションの後半には、オーストラリアの4大銀行のひとつであるオーストラリア・ニュージーランド銀行のオンラインサービスANZ Plusの開発者によるケーススタディの発表がありました。ANZ Plusでは、KubernetesとCloud Runの使用を比較検討した上で、Cloud Runをほとんどのアプリケーションのデフォルトのランタイムとして採用することにしたそうです。現在では1,600を超えるCloud Runサービスが本番環境で稼働しているとのことです。
ANZ PlusによるCloud RunとKubernetesの比較検討

金融機関である同社にとっては、高可用性とリージョン障害時のフェイルオーバーが不可欠です。Kubernetesでのマルチリージョン対応は、多数のクラスターやゾーンの設定、ネットワーク構成などが必要で、大がかりです。しかし、Cloud Runならクラスターやノードのプロビジョニングが不要で、gcloudコマンドでシンプルにサービスをデプロイできます。さらに、クロスリージョンのロードバランサーや、Spannerのデュアルリージョン機能(シドニー・メルボルン間)と組み合わせることで、高可用性を実現しています。
ANZ Plusでの具体的なCloud Run活用例として、1日1億リクエスト以上を捌く同社のプッシュ配信サービスの事例が紹介されました。ショッピングが活発に行われる時間帯やプロモーションキャンペーン中などのアクセスがスパイクする時間帯にも、Cloud Runのオートスケールのおかげでパフォーマンスを低下させることなく対応できている、とのことです。MA部でもプッシュ、メール、LINEでの配信を行なっており、配信システムにCloud Runをよく利用していることから、そのありがたさについて非常に共感できました。
Cloud Runの性能の良さはミッションクリティカルなアプリケーション開発に対する大きな強みですが、ここ数年の進化によりさらにエンタープライズのニーズへしっかり応えられる段階に進化しているという点が強調されたセッションでした。AI活用、セキュリティ、マルチリージョン対応、バッチ処理、常時稼働のWorker Poolsなど様々なユースケースに対応し、Cloud Runはこれからの企業インフラの中核としてますます注目されていくことになりそうです。
What’s new in Gemini Code Assist
What’s new in Gemini Code Assistというセッションでは、2024年にリブランドされた開発者向けAI支援ツールであるGemini Code Assistについて、デモを交えて説明されました。Gemini Code Assistでの提供モデルは、Gemini 1.0 Proから1.5 Pro、そして現在のGemini 2.0へと進化を遂げました。Gemini Code AssistはStandard EditionとEnterprise Editionに分かれ、特にEnterprise Editionでは企業独自のコードベースや知識を考慮して提案する一方で、機密情報を安全に守ることができます。ここに、無料で使用できるindividualsが最近加わりました。
ソフトウェア開発へのAIの活用は、業界のトレンドとなっています。Googleが支援する調査機関DORAの調査によると、現在では多くの企業がAIの活用をビジネスにとって不可欠なものと認識しており、開発者の約75%がすでにAIをコードの作成や問題解決に活用しています。ただし、生産性向上を感じている開発者も多い一方で、コードの品質や安定性の低下、信頼性の課題といった懸念も存在しています。
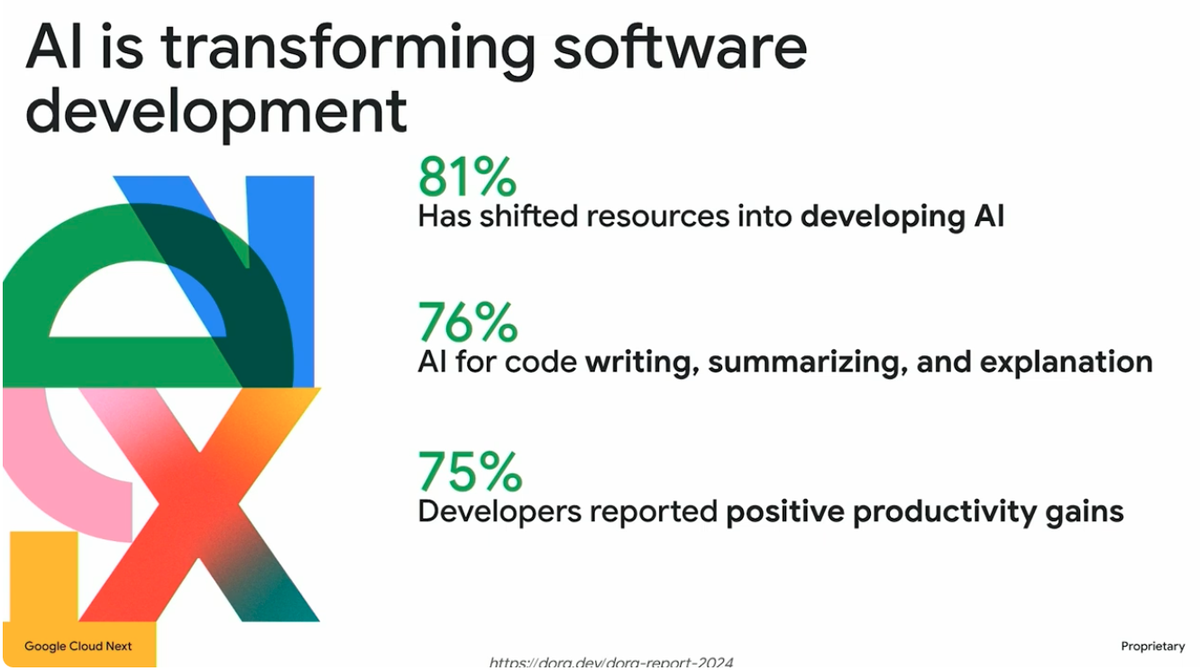
GoogleはGemini Code Assistを、単なるIDEでのコード補完だけでなく、ドキュメントの作成、テスト、セキュリティチェック、デプロイメントまで、ソフトウェア開発のライフサイクル(SDLC)全体を支援するエンタープライズ向けのAI開発ツールとして設計しています。そのため、セキュリティ、運用管理、プライバシー保護の観点からも厳格な整備がなされています。
ソフトウェア開発ライフサイクル全体で適切なサポートを提供するGemini Code Assistの機能として、Gemini Code Assist ToolsやGemini Code Assist Agents、Code Assist for GitHubについて説明されました。ToolとAgentの違いとしては、ツールがチャット内でのプロンプト補完を担うのに対し、エージェントは複数のタスクを自然言語で連携・自動化するもので、複数のサブプロンプトを駆使して単一のプロンプトよりも正確で安定した結果を導き出します。
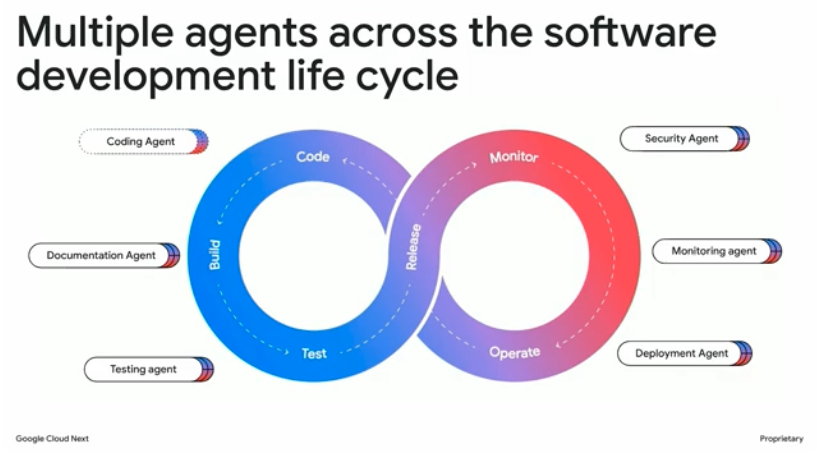
Gemini Code Assistはエージェントなどを通して様々な情報ソースを統合してコンテキスト(文脈)を共有することで、異なるプラットフォームに散在する情報を横断的に考慮しコード品質向上に関するアドバイスを行います。コンテキストには、ローカルのコードベースから関連ファイルを自動抽出する「プロジェクトコンテキスト」、独自のライブラリやコーディング規約をRAGで活かす「エンタープライズコンテキスト」、さらにコード以外にもPRDやJiraなどのタスク管理ツールまで含めた「エンジニアリングコンテキスト」があり、さまざまな情報をコンテキストとして取り込むことで、より精度の高い提案を実現しています。
Gemini Code Assistが解釈するコンテキスト

情報の運用管理やアクセス制御も強化されており、どの情報がインデックス対象になるか、誰がどの情報にアクセスできるかといった点を細かく制御できます。
Gemini Code Assistには、無料で使用できるGemini Code Assist for individualsと、有料のGemini Code Assist StandardおよびGemini Code Assist Enterpriseのプランがあります。有料プランでは、特典として著作権リスクに関する「indemnification(免責)」も提供されています。これは、Gemini Code Assistが生成したコードに関する法的責任をGoogleが担保するもので、安心して導入できるポイントのひとつです。なかでもEnterprise Editionにおいては、企業特有のニーズに応じた機能強化が行われています。たとえば、自社のプライベートAPIやライブラリを活用したコード提案機能や、GitHub、GitLab、もしくはオンプレミス環境のリポジトリなどとの連携による日次での再インデックス、セキュアな隔離環境でのコード保管(Google社員には非公開)などが用意されています。さらに、Geminiの使用状況を可視化するオブザーバビリティ機能も提供されており、DORAメトリクスや売上との相関分析、プロンプトおよびレスポンスのログ取得(プライベートバケットに保存)などが可能です。
セッションの最後に、Sentry社により、実際に社内で行われているGemini Code AssistとSentryのAIエージェントを活用した開発プロセスのデモンストレーションが行われました。デモでは、Gemini Code Assistのチャットインタフェースを通じて、Sentryのエラー情報やパフォーマンスデータをリアルタイムで取得し、エラーについて言及されているイシューを表示するなどのシーンがありました。SentryとGemini Code Assistの連携は、エラー検出から修正までの一連のプロセスをシームレスに統合し、開発者がフロー状態にある時間を伸ばし、作業効率を大幅に向上させます。このデモでの開発者体験はまるでドメインを熟知したエンジニアが常に開発者をサポートするかのような印象を受け、AIを活用した次世代の開発体験を示す好例になっていると感じました。
このように、Gemini Code Assistを使用することで、開発者は複数のツールを切り替えることなく、IDE内でエラーの詳細や関連するトランザクション情報を確認できるようになります。これにより、開発の生産性と品質の向上、ソフトウェアの迅速なリリースが可能となります。私は、開発もしくはデバッグ時にショートカットを多用してたくさんのツールを切り替えて使用しているので、IDEだけで様々な調査をショートカットしてくれるのは、近未来的な開発者体験だと感じました。複数のリポジトリでの開発と多くのドキュメントの作成・解読・管理、様々なツールを使用したデバッグ作業など、日々の作業のコンテキストスイッチを劇的に減らせるのではと大変期待しています。エンタープライズでの利用には欠かせない安全性についても強調されており、多くの企業での導入検討を後押しするのではと思います。
おわりに
本記事では幅広いテーマでサービスのアップデートについて説明しました。数多くのセッションがあり、どれも非常に興味深い内容ばかりでしたので、公式サイトのSession Libraryで、ぜひ気になったセッションを見てみてください。
イベント全体の雰囲気としては、今年も前年に引き続きAIに関する発表が多く見られ、特に基調講演は生成AIの話題を前面に押し出した内容でした。なかでも、AIエージェント同士を連携する新プロトコルであるA2A(Agent2Agent)に関する説明とそれを使用したデモで、様々な機能が連携し人間のようにデータを分析したり、音声で対応したり、値引き交渉の応諾可否について上司に相談する(!)など、多様なタスクをこなすアプリケーションの実装例が特に印象的でした。「誰でもエージェントを作成、公開し、他のエージェントとやり取りできる」仕組みが標準化されることによって、あらゆる知識やスキルが“再利用可能なインターフェース”として開かれる未来が現実味を帯びてきたと感じます。
また、セッション以外にも、企業ブースや開発者ミートアップでの様々な開発者との議論、夜に行われるイベントでの他社の方々との交流など、とても貴重な経験ができました。
最後に、弊社ではカンファレンス参加に伴う渡航費や宿泊費は福利厚生のひとつであるセミナー・カンファレンス参加支援制度によって、カンファレンス参加にかかる費用は全て会社負担です。
ZOZOでは一緒にプロダクトを開発してくれるエンジニアを募集しています。ご興味のある方は下記リンクからぜひご応募ください!