



はじめに
こんにちは、MA部MA開発ブロックの平井です。普段はマーケティングオートメーションシステムの運用、開発を担当しています。現在、開発ブロックではリアルタイムマーケティングシステムのリプレイスプロジェクトに取り組んでいます。リプレイスプロジェクトを進める上で、性能目標を満たすためにアプリケーションのパフォーマンスチューニングが必要でした。今回、Cloud Traceを利用してアプリケーションパフォーマンスを可視化し、パフォーマンスチューニングを行ったためその知見を共有したいと思います。
この記事の内容を読むと、以下の内容について知ることができます。
- Cloud Run上の処理をCloud Traceを用いて可視化する方法
- Cloud Traceでトレース情報を確認する方法
- Cloud Traceをパフォーマンスチューニングに活用した一例
目次
- はじめに
- 目次
- 背景
- 課題
- Cloud Traceについて
- Cloud Traceで処理を可視化するために
- アプリケーションの計装
- Google Cloudサービスの各トレース情報紐付け
- Cloud Trace上でのトレース情報の見え方
- パフォーマンスチューニング
- まとめ
背景
本記事の本題へ入る前にリプレイス先のシステムについて説明します。私たちMA部ではインフラにGoogle Cloudを利用することが多く、今回開発しているシステムもGoogle Cloudを利用しています。Cloud Run上に構築された複数のアプリケーションがPub/Subで連携し1つのシステムを構成しています。また、メインのデータベースとしてAlloyDBを利用しています。
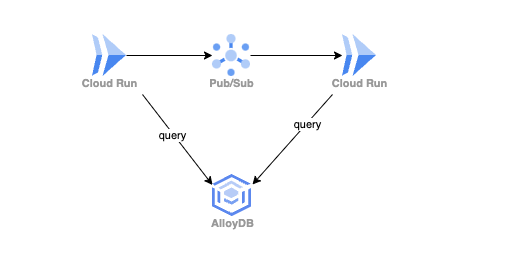
今回は、システムを構成している個々のアプリケーションのパフォーマンス改善ポイントを特定するためにCloud Traceを利用しました。
課題
パフォーマンスチューニングを行う上で、Cloud Traceを利用するまでは以下のような課題がありました。
- アプリケーション内で実際にどのような処理が実行されているかわかりづらい。
- アプリケーション内の各処理の実行時間がわからない。
また、「アプリケーション内の各処理の実行時間がわからない」という課題について、具体的に実現したいことは以下です。
- アプリケーション上で実行されるクエリ実行時間を知りたい。
- Pub/Subメッセージのパブリッシュにかかる時間を知りたい。
- Cloud Loggingに連携したログをもとに特定処理の実行時間を知りたい。
Cloud Traceを利用することで以上のような課題を解決できました。
Cloud Traceについて
今回利用したCloud TraceはGoogle Cloudが提供する分散トレースシステムです。分散トレースシステムを活用することで、マイクロサービスシステムの処理の流れを把握できます。しかし、今回の目的はマイクロサービス全体の処理を把握することではなく、アプリケーションのパフォーマンスチューニングだったため、APM(アプリケーションパフォーマンス監視機能)として利用しました。
Cloud Traceに関する詳細な情報については公式ドキュメントを確認してください。
APMを提供するサービスは多数ありますが、システムがGoogle Cloud上に構築されていて、利用しているサービスとの親和性が高く簡単に導入できることから、Cloud Traceを選択しました。
Cloud Traceで処理を可視化するために
Cloud Traceを利用して適切に処理を可視化するためには、以下を実現する必要がありました。
- アプリケーションの計装
- Google Cloudサービスの各トレース情報紐付け
これから、これらのポイントについて実際のアプリケーションコードを使って説明します。今回実装したシステムではGoを使用しているため、説明に使用するのはGoのソースコードです。
アプリケーションの計装
「計装」とは分散トレーシングの文脈でよく使用される用語です。「アプリケーションを計装」するとは、アプリケーションにトレース機能を組み込み、トレース情報を収集できるようにすることを指します。今回実装したシステムではOpenTelemetryフレームワークを利用して計装を実現しています。GoでOpenTelemetryを構成するために必要な設定については公式ドキュメントを参考にしてください。
Google Cloudサービスの各トレース情報紐付け
Cloud Run
Cloud Runではリクエスト受信時に自動でトレース情報を生成します。ただ、アプリケーションにOpenTelemetryを構成したとしても自動生成されたトレース情報がアプリケーションのトレース情報と紐づかないため処理を可視化するには不十分です。
今回実装したシステムではルーティングライブラリにchiを利用しています。以下のようにotelhttpのハンドラをミドルウェアとして登録することで、Cloud Runが自動生成したトレース情報とアプリケーションのトレース情報が紐づきます。
func tracingHandler(next http.Handler) http.Handler { return otelhttp.NewHandler(next, "http-request") } func NewRouter(conf *config.Config) (*chi.Mux, error) { //その他のコードが続く //otelhttpハンドラの登録 router.Use(tracingHandler) //その他のコードが続く return router, nil }
AlloyDB
AlloyDBで実行されたクエリはトレース情報として自動的にCloud Traceへ送信されます。ただ、何も設定しない状態だとCloud Runが自動生成したトレース情報と紐づいていないため、完全に別の処理として認識されてしまいます。今回実装したシステムではGORMをO/Rマッパーとして利用しているため、GORMが用意しているgo-gorm/opentelemetryを利用しました。
以下が実際のアプリケーションコードを簡素化したものです。
func NewPostgresHandler(config *config.Config) *PostgresHandler, err { dsn := "host=localhost user=gorm password=gorm dbname=gorm port=9920 sslmode=disable TimeZone=Asia/Tokyo" db, err := gorm.Open(postgres.Open(dsn), &gorm.Config{ Logger: customLogger, }) if err != nil { return nil, err } //その他のコードが続く err = db.Use(tracing.NewPlugin(tracing.WithoutMetrics())) if err != nil { return nil, err } //その他のコードが続く } func (h *PostgresHandler) GetDB(ctx context.Context) *gorm.DB { tx, ok := ctx.Value("transaction").(*gorm.DB) if ok { return tx } return h.db.WithContext(ctx) }
NewPostgresHandler関数ではDB接続設定をしています。db.Use(tracing.NewPlugin(tracing.WithoutMetrics()))の部分でopentelemetryライブラリを利用することを宣言しています。GetDBはリポジトリ層から呼び出される*gorm.DBを返すメソッドです。重要なのは最後のreturn h.db.WithContext(ctx)でContextを渡している部分です。Contextを利用してトレース情報を伝播するため*gorm.DBに渡す必要があります。
Pub/Sub
Pub/Subに関してもトレース情報は自動生成されます。そのため、アプリケーションのトレース情報と自動生成されるトレース情報を紐づける必要があります。
func PublishMessage(ctx context.Context, projectID string, message *pubsub.Message, isLoggingBody bool) error { client, err := pubsub.NewClientWithConfig(ctx, projectID, &pubsub.ClientConfig{ EnableOpenTelemetryTracing: true, }) if err != nil { return err } defer client.Close() t := client.Topic(topicID) defer t.Stop() result := t.Publish(ctx, message) //その他のコードが続く }
PublishMessageはPub/Subメッセージをパブリッシュする関数です。NewClientWithConfig関数でクライアントを初期化する際にEnableOpenTelemetryTracingをtrueに指定する必要があります。この設定をすることでメッセージAttributesのgoogclient_traceparentフィールドに親トレースIDが入り、このフィールドの値をもとにトレース情報を伝播できます。
Cloud Logging
Cloud Loggingに連携したログデータをトレース情報として紐づけるためには、構造化ログの特定フィールドに適切な値を設定する必要があります。
type TraceHandler struct { slog.Handler project string } func (h *TraceHandler) Handle(ctx context.Context, record slog.Record) error { path := "projects/" + h.project + "/traces/" if s := trace.SpanContextFromContext(ctx); s.IsValid() { record.AddAttrs( slog.String("logging.googleapis.com/trace", path+s.TraceID().String()), slog.String("logging.googleapis.com/spanId", s.SpanID().String()), slog.Bool("logging.googleapis.com/trace_sampled", s.TraceFlags().IsSampled()), ) } return h.Handler.Handle(ctx, record) } func NewTraceHandler(baseHandler slog.Handler, project string) *TraceHandler { return &TraceHandler{Handler: baseHandler, project: project} } func InitLogger(config *config.Config) error { // logger設定のコードが続く traceHandler := NewTraceHandler(baseHandler, config.GcpProject) logger := slog.New(traceHandler) // logger設定のコードが続く }
こちらはloggerを設定しているコードです。今回実装したシステムでは構造化ロギングパッケージとしてlog/slogを利用しています。Handleメソッドはslog.HandlerのHandlerメソッドをオーバーライドしています。
その実装でログレコードに必ずlogging.googleapis.com/trace、logging.googleapis.com/spanId、logging.googleapis.com/trace_sampledが設定されるようになっています。
SpanContextFromContextでctxから現在のトレース情報を取得して各フィールドに適切なフォーマットで値を指定しています。こうすることで、現在のトレース情報とログを紐づけることができ、Cloud Traceの画面上で可視化できるようになります。
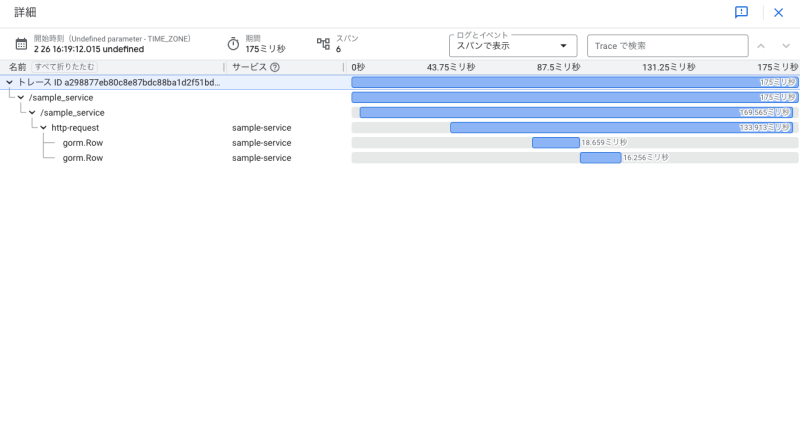
Cloud Trace上でのトレース情報の見え方
以上の設定をするとCloud Traceに処理を可視化できます。
ここで、用語の説明をすると、画面上に表示される1つのプロセス全体を「トレース」と呼び、その中の各処理を「スパン」と呼びます。

一番上の/sample_serviceと記載されているスパンがCloud Runのロードバランサーが生成したスパンです。http-requestがCloud Run内の処理の起点となるスパンでその下にアプリケーションで実行された各処理が可視化されています。
このトレース情報を見るとCloud Runがリクエストを受け取った後に数回のクエリを実行して、Pub/Subメッセージをパブリッシュしていることがわかります。また、各スパンをクリックするとスパンの詳細情報を確認できます。
補足ですが、Cloud Runは一定レートでサンプリングを行いトレース情報を生成しているため、全てのリクエストのトレース情報を見ることは出来ません。
これから、アプリケーション上で利用されている各サービス毎の情報について説明したいと思います。
AlloyDB
gorm.XXXと記載されているのがアプリケーション上から実行されたAlloyDBへのクエリを表すスパンです。
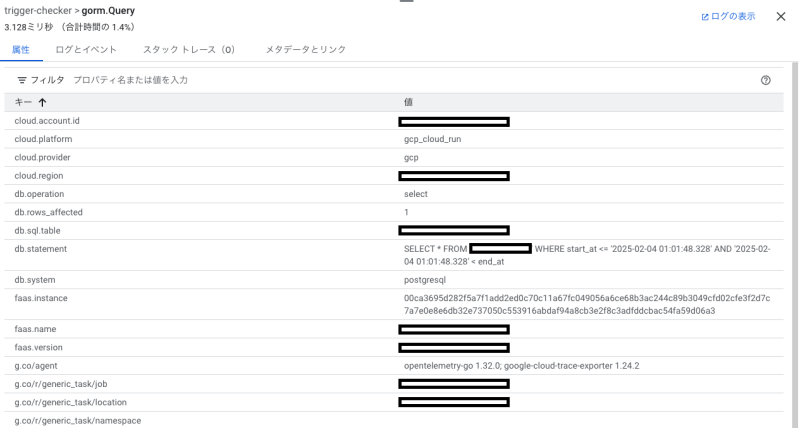
スパン詳細情報を確認すると、トレース情報からわかるクエリ実行時間の他にrows_affected、クエリステートメントなど処理を理解するために有用な情報を確認できます。これらの情報はgo-gorm/opentelemetryが自動で設定してくれるものです。
また、AlloyDBにはQuery Insightsという機能があります。この機能では、AlloyDBクラスター毎に遅いクエリの検索や、クエリの実行計画の確認などができます。Query Insightsから確認できるクエリ情報とトレース情報が紐づいていて、Cloud Trace画面へとリンクされています。そのため、Query Insightsで特定できた遅いクエリがどのアプリケーションで実行されているのかを簡単に把握できます。

Pub/Sub

こちらがPub/Subパブリッシュ処理を表すスパンです。sample-topic createのsample-topicがトピック名になるため、どのトピックに対してパブリッシュしたかを確認できます。スパン詳細情報を確認するとメッセージのBodyは確認できないもののBodyサイズなどは確認できます。トレース詳細画面からPub/Subのflow controlが行われ、その後にbatchパブリッシュが行われていることがわかります。
Cloud Logging
Cloud Loggingのログ情報はトレース詳細情報に白丸として確認できます。対象のログイベントがスパン上にプロットされているため処理中のログの実行タイミングを把握できます。
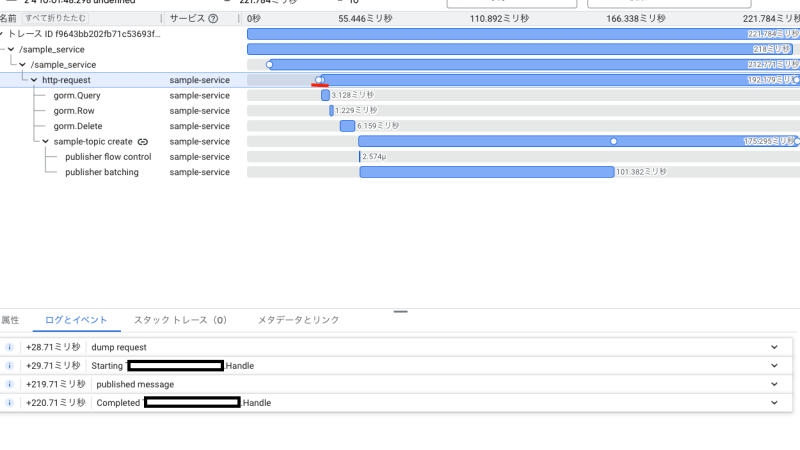
クリックすると発行されたログを一覧で確認できます。
パフォーマンスチューニング
以上のようにCloud Traceにトレース情報を可視化できました。次にCloud Traceを利用して実際に実施したパフォーマンスチューニングをいくつか説明したいと思います。
データベースへの最大接続数の調整
アプリケーションに本番相当のデータを流したところ想定よりも性能が出ませんでした。
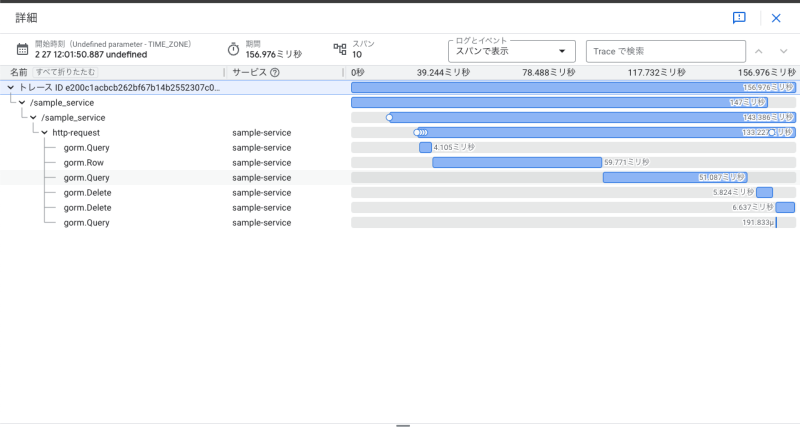
そこでトレース情報を確認したところ、以下の画像のように各クエリの実行間隔が空いていました。
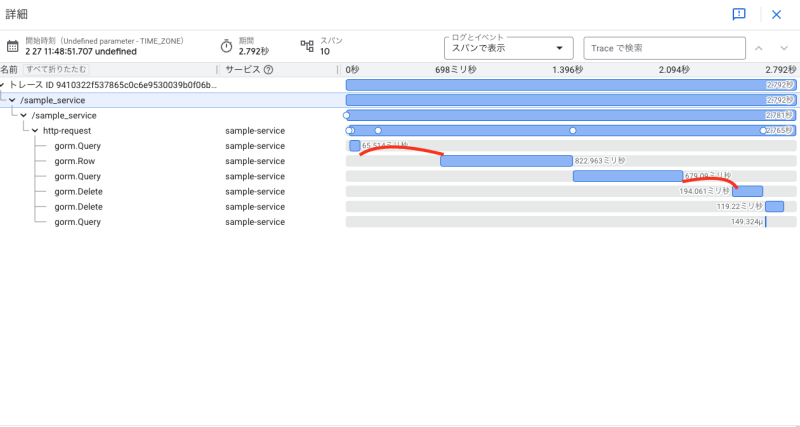
各クエリ実行の間に重い処理が無かったため、DBへのコネクション待ちが発生していることがわかりました。Cloud Runの設定を確認したところ、Cloud Runの最大同時実行数よりもデータベースへの最大接続数が少なく設定されていました。つまり、アプリケーション側から作成できる接続数をクエリ発行数が上回ってしまい、コネクション待ちが発生していたという状況でした。そのため、データベースへの最大接続数を上げることでコネクション待ちを解消できました。
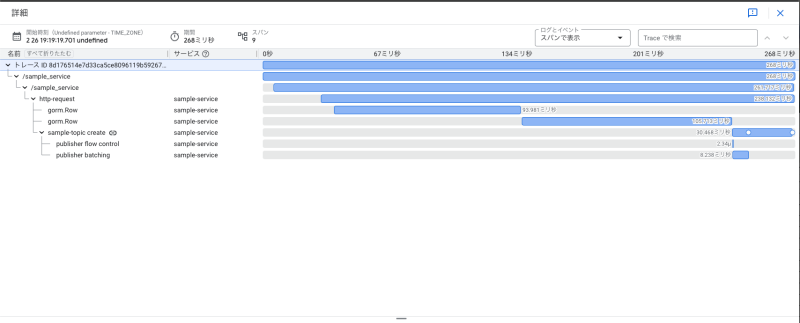
以下は修正後のトレース情報です。クエリが間隔を空けずに実行されていることがわかります。
クエリ実行間隔については処理を可視化しなければ気づけなかったため、Cloud Traceを利用したメリットがありました。
Pub/Subメッセージパブリッシュ数の削減
トレース情報を確認したところPub/Subメッセージのパブリッシュに想定よりも時間がかかっていることがわかりました。かつデータを1件毎パブリッシュしていて、1回のプロセスにおけるパブリッシュ回数が多く、全体の処理時間が増加していました。
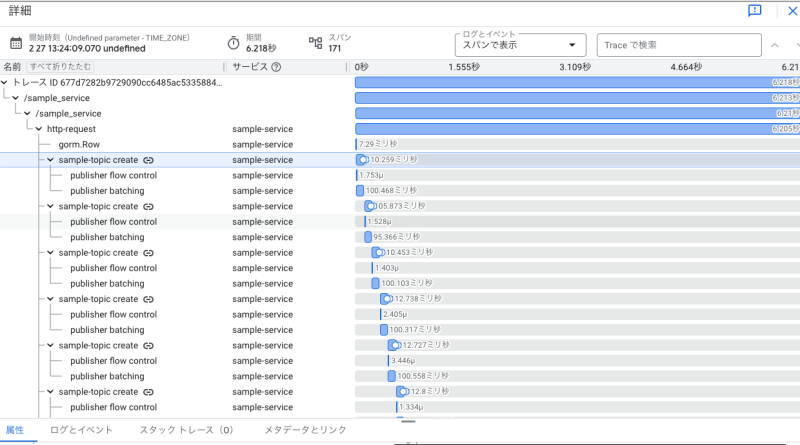
そこで、今まで1つずつパブリッシュしていたデータを配列で1つにまとめ、パブリッシュ数を減らしました。メッセージ1件のサイズは大きくなったものの、パブリッシュの実行時間はほぼ変わらなかったため全体の実行時間を大きく改善できました。
クエリ実行回数の削減
トレース情報を確認したところ、以下のように単独のクエリ実行時間は短かったものの、その実行回数が多く全体の処理時間を増加させていました。
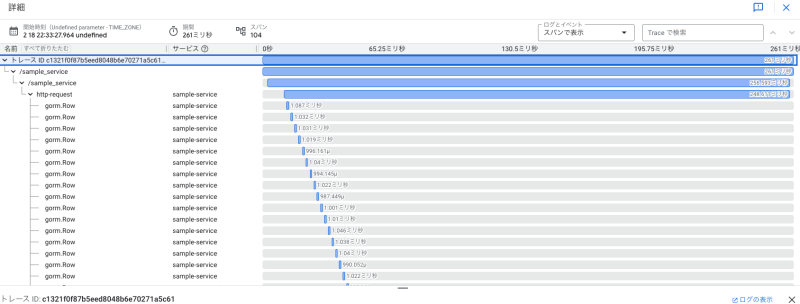
そこで、アプリケーションコードとクエリを修正することでクエリ実行回数を減らしました。以下の画像からわかるようにクエリ自体の実行時間は増えましたが、実行回数を減らしたメリットが大きく、全体の実行時間を改善できました。
「Pub/Subメッセージパブリッシュ数の削減」「クエリ実行回数の削減」に関してはある程度予想できましたが、トレース情報を確認することでより確信を持つことができました。
まとめ
本記事では、Google CloudのCloud Traceを活用してアプリケーションパフォーマンスを可視化し、パフォーマンスチューニングに取り組んだ事例をご紹介しました。Cloud Traceでデータを可視化することで、対象アプリケーションの実際の処理を理解でき、改善ポイントをより素早く特定できました。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。