



こんにちは。MSP技術推進部の手塚(@tzone99)です。
この記事では、エンジニア向けのツールを周囲のエンジニア以外のチームにも導入し、チームを跨いだコミュニケーション上の課題を解決した事例をご紹介します。
普段エンジニアとしてプロダクトを開発する中でも、エンジニア同士のやり取りだけで業務が完結しないケースも多いかと思います。周囲のチームとやり取りする中でコミュニケーションのずれが発生した場合の対応として、今回の事例が参考になれば幸いです。
MSP技術推進部の活動について興味のある方はこちらの記事もぜひご覧ください。
目次
背景
私の所属するMSP技術推進部は服づくりに関する技術を開発する部門です。
ZOZOTOWN内で販売されるMS(マルチサイズ)アイテムの生産プラットフォームとして、アパレル商品の企画、設計、生産に関わる業務システムを開発し、ITを活用した新しい服づくりを追求しています。MSアイテムは最大56サイズから自分の体型に合ったサイズを選択可能、という特徴を持っており既存のサイズに囚われずいろんな体型の方にファッションを楽しんでいただけるアイテムです。
一般的な場合と同様、このような多サイズのアイテムにおいても、生産の際はサイズ毎のパターンデータ(服の設計図)を用意する必要があります。従来SMLの3サイズ程度だったパターンデータを最大56サイズ分用意するためパターン設計の負荷が高いことは明らかです。
一般的なアパレルCADにはサイズ毎のパターンデータを生成(グレーディング)する機能が備わっているとはいえ、MSアイテムで想定しているような大小様々なサイズにそのまま機能を適用できる訳ではありません。現状、細かなパターン調整工数が大量に発生しており、事業のスケールを妨げる一因になっています。
このような背景からMSアイテムのような多サイズ展開に適したパターンデータの生成ツールを開発するプロジェクトが発足しました。
コミュニケーション上の課題
大枠としてアパレル専門職であるグレーディングチームがパターンデータの生成に必要な業務要件を数式や図で定義し、それをエンジニア側で実装するという流れで開発を進めていました。

パターン生成のためのルールは例えば以下のように数式や関数として表現されており、ルールが増えていくにつれて変更に伴うタイポ、計算ミスがどうしても防ぎきれなくなっていきました。

またルールによっては表ではなく図で管理したいものも多くありました。しかし、数式とこれらの図の整合性をとることもルールが増えるにつれ困難になっていきました。
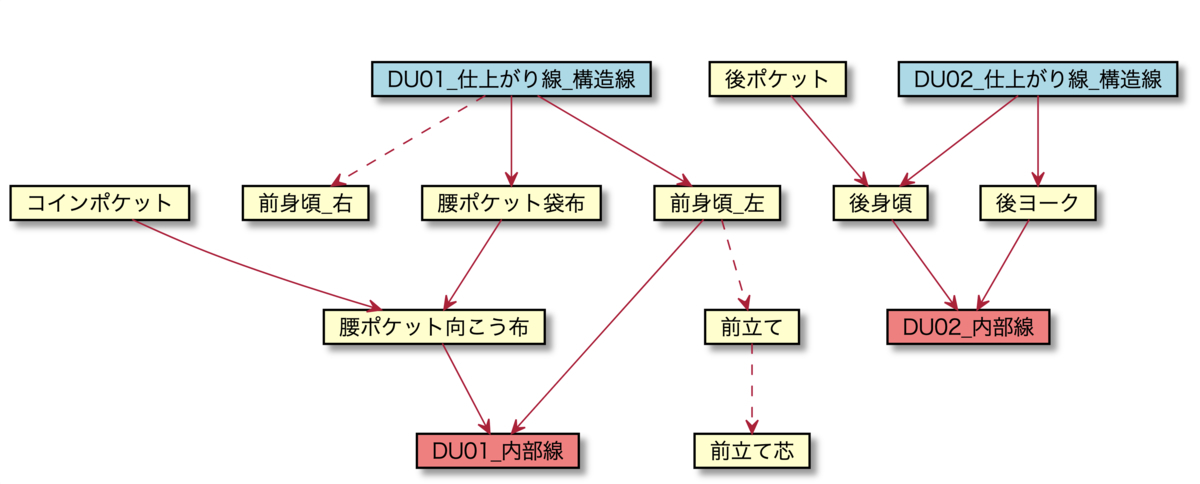
このようなルール管理上のタイポや計算ミス、ドキュメント間の不整合から要件の確認工数がどんどん増えてしまい、開発のボトルネックになってしまいました。
そこで、ここまでの進行の振り返りを実施し、コミュニケーション上の課題を明文化しました。結果として以下のような課題がメンバー全員の共通認識となりました。
- 大量の計算式が業務要件として定義されているため、単純なタイポ、計算ミスが防ぎきれない
- 業務要件のレビューの負荷が特定のメンバーに集中してしまっている
- 内容の重複があり、1箇所の変更が影響範囲に網羅的に反映されず、ドキュメント間の不整合が発生している
- 変更されたルールのステータス(検討中/検討済み)が曖昧である
- 当初想定しきれなかったルール定義上の課題に対処するため、ルールの変更が想定以上に頻繁に発生している
業務要件のMarkdown/PlantUML化
上記の課題を仕組みで解消するために、ツールの運用、特にそれまで業務要件の定義で使っていたGoogleスライドやスプレッドシートの利用を見直しました。
これらのツールは確かにアイデアの可視化や共有には便利ですが、今回のように数式や関数で定義されたルールが頻繁に更新されるケースでは、より組織的な変更管理フローとそれに適したツールが必要と判断しました。挙がっていた課題の解決に必要な機能(タイポの防止/相互レビュー/頻繁な更新に耐え得る変更履歴と変更ステータス管理)を洗い出していくとソースコード管理に求められるものと同等でした。
したがってエンジニア向けのツールを要件定義にも導入するのが良さそうだという見通しの元、ツールを選定しました。利用するメンバーが非エンジニアであることもふまえて特に以下の点を意識しました。
- 学習・導入・運用コストが小さいもの
- GUIで操作できるもの
- ツールの使い方に関してWeb検索ですぐHitするもの
ルールの記述はMarkdownをベースとし、図示した方が分かりやすいものはPlantUMLを用いて作図することで全てのルールをテキスト化しました。導入するツールとルールの定義(または変更)のフローを以下のように定め、運用を始めました。

運用の初期対応
エンジニアにとってはどれも馴染み深いツールですが、他のチームのメンバーにとっては初めて使うものばかり。円滑に運用を開始するためにハンズオンを実施しました。
ハンズオンでの情報過多による運用初期の混乱を抑えるため、必要最小限のトピックに絞って説明するにとどめました。約3時間で以下のトピックについて説明しました。
- Visual Studio CodeでのMarkdown編集、拡張機能の追加
- よく使う機能
- Open folder(フォルダごと開く)
- Search(フォルダ内テキスト検索)
- 正規表現を使った検索
- 例えばアルファベット大文字4桁+数字4桁の変数を全て検索したい場合:[A-Z]{4}[0-9]{4}
- Source Control
- Diff(差分)
- Discard changes(変更を破棄)
- Command list(F1キーで開く)
- File: Compare Active File With(2つのファイルを比較)
- Markdown: Open preview(Markdownをプレビュー)
- PlantUML: Preview Current Diagram(PlantUMLをプレビュー)
- Preferences: Open User Setting(ユーザー設定を変更)
- Git: Stash(変更に名前をつけて一時退避)
- Git: Pop Stash(退避した変更を戻す)
- キーボードショートカット
- マルチカーソルと選択
- Visual Studio Codeに拡張機能を追加
- おすすめ拡張機能
- Markdown all in one
- Markdownが見やすくなる。自動フォーマット機能あり。
- Highlight
- settings.jsonに以下のテキストを追加すると全角のスペース、かっこ、英数字をハイライト表示できるのでエラー防止に。
- Markdown all in one
- よく使う機能
"highlight.regexes": { "( )": [{ "backgroundColor": "lightgray" }], "([0-9A-Z()])": [{ "color": "red", "backgroundColor": "yellow" }] }
- GitHubの仕組みを説明
- バージョン管理とは
- リモート/ローカルリポジトリ
- 変更履歴の統合
- ブランチ
- GitHub基本操作のハンズオン(テスト用のリポジトリを作ってみんなでアクセス!)
- 基本のPull, Commit, Push
- コンフリクトの発生と解消
- 独自ブランチでの作業
- ブランチのMerge
- 変更履歴の確認
- プロジェクトでの運用フロー説明
運用フローを明文化し、各レビュアーの観点も明記して記載内容やレビュアーの重複がなくなるよう運用を設計しました。
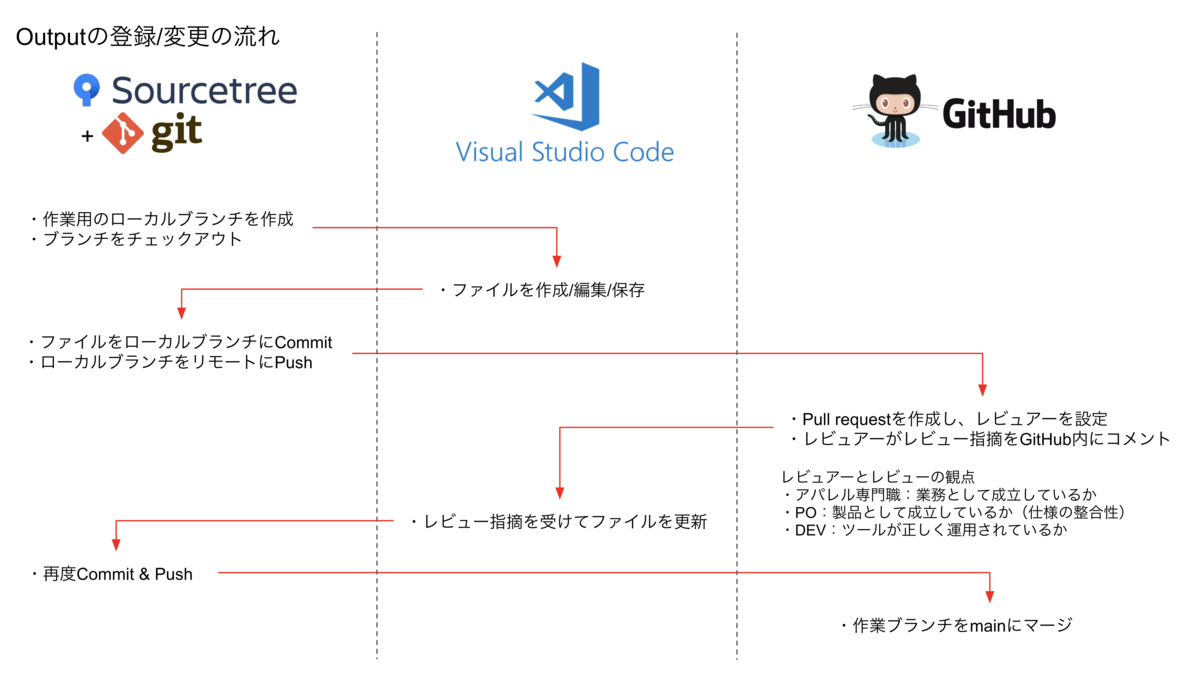
もちろん上記の他にも運用していく中で様々な状況への対応が必要ですし、より良い運用のために知っておくべき操作も数多くあります。
しかし、それらは運用しながら適宜コメントを入れることで徐々に理解を深めてもらうようにしました。分からなくてもまずは使ってもらう、試してもらうというモチベーションで使ってもらいました。
導入したツールを使ったやりとりはメンバー全員が見えるオープンなものになるため、エンジニアメンバーの使い方を見ながら他の非エンジニアメンバーも使い方を学んでいけることを期待しました。
自作のLinter導入、継続的メンテナンス
上記の運用に加え、わざわざ人間がチェックする必要のない単純なルールの記載ミスを検出するLinterをPythonで自作しました。このLinterはMarkdown Table及びPlantUMLの構造解析と正規表現マッチングによるエラー検出を組み合わせた簡易的なものです。
例えば以下のコードでMarkdownファイル内のTableから特定の一列を配列として取得します。
# Markdownファイルに含まれるTableのデータを配列に格納 def get_table(path): with open(path) as f: lines = f.readlines() table = [] for line in lines: row = re.split('\\|', line) cells = [] for cell in row: cell = cell.strip() cell = cell.replace('\\', '') cells.append(cell) table.append(cells) return table # Tableのデータ配列から任意の一列を取得 def get_column_contents(table, header): index = table[0].index(header) contents = [] for row in table: contents.append(row[index]) del contents[:2] # table headerを除外 return contents # テスト実行 def test(self): FILEPATH = './filename.md' COLUMN_NAME = 'Target Column Name' table = get_table(FILEPATH) column_contents = get_column_contents(table, COLUMN_NAME) # 取得した列データに対してテストを実行 # . # .
Markdown Parserは既に数多くのものが開発され公開されていますが、今回のMarkdownの用途はTableに特化していたため既存のParserを使うのはオーバースペックと判断しました。
以下のコードは数式から変数のリストを抽出するものです。業務要件として定義されている数式や変数には一定のルールがあるため、正規表現で十分抽出できると判断しました。
# 数式から変数のリストを抽出する def get_var_list_in_formula(formula): result = [] if formula != '': var_list_row = re.split(r'\(|\)|\+|\-|\*|\/|\=|\,', formula) for var in var_list_row: if var != '' and re.search(r'[0-9]{0,1}[a-zA-Z]+', var): var = var.strip(' ') if re.match(r'[0-9]{1}', var): var = var[1:] var = remove_landmark_prefix(var) var = remove_landmark_suffix(var) result.append(var) return result # 接頭語付き変数から接頭語を除外する def remove_landmark_prefix(s): if s.startswith(('m', 'g', 'r', 'd')): s = s[1:] return s # 接尾語付き変数から接尾語を除外する def remove_landmark_suffix(s): if s.endswith('c'): s = s[:-1] return s
このLinterで以下のようなケースを検出できるようになりました。
- 未定義の変数の使用
- 関数内で引数の型、引数の数が想定外
- 未使用の変数の検出
- タイポにありがちな不正な書式
本格的な構文解析ツールではないのでルールの拡充に伴い継続的にメンテナンスが必要なものの、目視確認に比べてメンテナンスコストが大きく削減され、施策としては有効な結果でした。何より大量の数式に含まれ得るタイポの目視確認が不要となり、精神衛生上かなり快適になりました。
Linterはローカルで実行できる他、GitHubにルールをPushするとCircleCIにより実行されるよう設定しチェック忘れを防止しています。
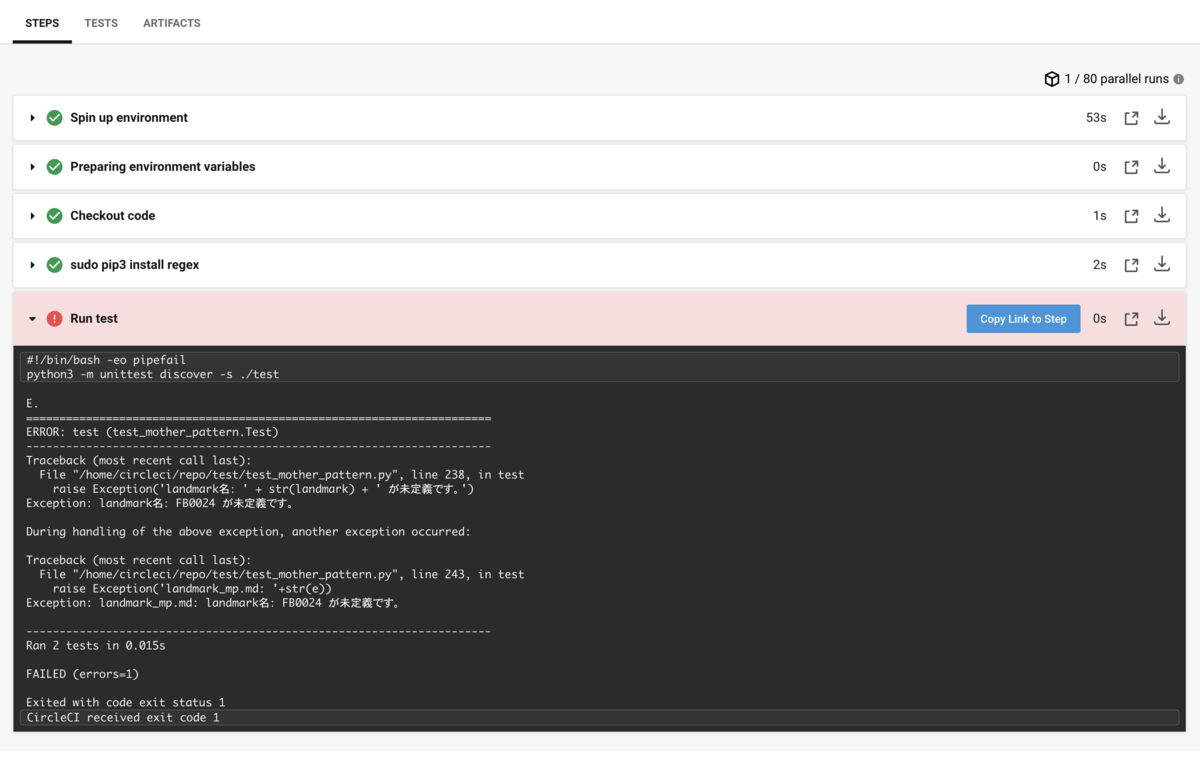
結果
これらの施策により、エンジニア側にインプットされる業務要件が精度の高いものになり、コミュニケーション上の課題を解消できました。
- 自作したLinterで単純なタイポ、計算ミスを検知
- レビュアーの役割を分散し明文化
- Markdown化に伴い項目の重複が最小限になるようルール定義のフォーマットを更新
- GitHub上での適切なブランチ運用によりルールのステータス(検討中/検討済み)を明確化
- 頻繁なルール変更に耐え得る変更フローを定義
運用開始からこれまで、パターン生成ルールの追加/更新に関する311件のCommitのうち、29件でLinterによるエラーが検出され、不正な要件がmainブランチに入るのを食い止められました。Linter単体でも9.3%の精度向上に寄与しています。
加えてLinterでチェックできないポイントはGitHub上で相互レビューを通して議論され、正しい要件がmainブランチへ入るようになりました。
またブランチ管理によりアイデアベースの要件整理や複数のトピックを混ぜることなく並行して議論できるようになりました。チームで共有し、頻繁に更新する類のドキュメントは多少作成コストや学習コストをかけてでもMarkdownで管理していくことの良さも実感しました。
私個人だけでなく、アパレル専門職のメンバーからもコミュニケーションが明確になったと好評をいただきました。
おわりに
当初はエンジニア向けのツールを他のチームに押し付けたくないという思いもありましたが、コミュニケーション上の課題を明文化し、共通認識が持てたことで自信を持って提案できました。またこの共通認識により周囲のメンバーも前向きに取り組んでくれたものと考えています。
今回ご紹介した運用はまだ始めたばかりで、ブラッシュアップする余地はまだまだあるので、今後も継続的に改善していきます。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!