




はじめに
こんにちは、検索基盤部 検索研究ブロックの真鍋です。ヤフー株式会社から一部出向していて、主にZOZOTOWNの検索機能へのランキングモデルの導入に従事しています。
本記事では、Elasticsearch上でランキングモデルを扱うための有名なプラグインの仕組みと、同プラグインにZOZOが実装した機能を紹介します。
まず、本記事の背景を説明します。ZOZOTOWNでキーワード検索すると、結果の商品が並びます。結果の商品は非常に多数になることも多いので、ユーザ体験を損なわないためには、その並び順も重要です。ここで言うランキングモデルとは、この並び順の決定のために、商品のスコアを計算する式のことを指します。このような式は機械学習によって生成され、非常に複雑になることもあります。そのため、検索エンジンの標準機能では実行できず、プラグインを導入して初めて実行できることもあります。
ZOZOTOWNでは検索エンジンとしてElasticsearchを使用しています。そして、Elasticsearch上でランキングモデルを実行するために、OpenSource Connectionsが提供するLearning to Rank pluginを使用しています。以下、このプラグインを指して、単に本プラグインと呼びます。
本記事の前半では、本プラグインの仕組みを説明します。まずランキングモデルを実行する仕組みを紹介し、次にランキングモデルを学習するための特徴量の値を出力する仕組みを紹介します。後半では、ZOZOが本プラグインに実装した、特徴量キャッシュの機能を紹介します。これは、ランキングモデルの実行と特徴量の値の出力を併用する際に、後者を効率化するための機能です。
具体的なコードとしては、本プラグインのバージョンv1.5.8-es7.16.2を例に説明します。
本記事では本プラグインの詳しい使い方は紹介しませんが、過去の記事で紹介しておりますので、ぜひ合わせてご覧ください。
目次
ランキングモデルの実行の仕組み
まず、本プラグインでランキングモデルを実行する仕組みを紹介します。本プラグインでランキングモデルを実行するには、例えば以下のクエリをElasticsearchに送信します(本プラグインの公式ドキュメントより引用)。
{ "query": { "match": { "_all": "rambo" } }, "rescore": { "window_size": 1000, "query": { "rescore_query": { "sltr": { "params": { "keywords": "rambo" }, "model": "my_model" } } } } }
このクエリでは、以下のことが指定されています。
- クエリキーワードが
rambo - 既存の検索結果の上位1,000件をランキングモデルで並べ替える
- その際に使うランキングモデルの名前が
my_model
LtrQueryParserPluginによるクエリのパースと、RankerQueryオブジェクトの生成
例のクエリは、まず本プラグインのコードのうち LtrQueryParserPlugin に入力されます。LtrQueryParserPlugin はElasticsearch本体が提供するインタフェース SearchPlugin を実装しています。このため、LtrQueryParserPlugin はElasticsearch本体の SearchModule から見えるようになっています。
SearchModule はクエリの各要素(例のクエリで言うと match や sltr)をどのクラスにパースさせるかを管理しています。具体的には、組み込みのクラスのほか、各プラグインが SearchModule#getQueries で指定してくるクラスも考慮します。
LtrQueryParserPlugin#getQueries では、以下の通り sltr 要素を StoredLtrQueryBuilder にパースさせるという指定をしています。ただし、StoredLtrQueryBuilder.NAME は sltr であることに注意してください。この指定のため、次は本プラグイン独自の StoredLtrQueryBuilder に制御が移ります。
new QuerySpec<>(StoredLtrQueryBuilder.NAME, (input) -> new StoredLtrQueryBuilder(getFeatureStoreLoader(), input), (ctx) -> StoredLtrQueryBuilder.fromXContent(getFeatureStoreLoader(), ctx)),
StoredLtrQueryBuilder
StoredLtrQueryBuilder はクエリのJSONをパースし、メモリ上の表現(後述の RankerQuery)をビルドするのに使います。ビルドのために、以下の主要なメンバーを持っています。
- ランキングモデル名
- ストア名
- ランキングモデルが保存されているElasticsearchインデックスの名前(デフォルトは
.ltrstore)
- ランキングモデルが保存されているElasticsearchインデックスの名前(デフォルトは
Map<String, Object>- クエリの
paramsに対応するオブジェクト(例のクエリを参照)
- クエリの
StoredLtrQueryBuilder#doToQuery を呼ぶと、RankerQuery が返ります。このとき、ランキングモデル本体もメモリにロードされます。
StoredLtrQueryBuilder のコードは以下にあります。
RankerQuery
Elasticsearchは検索ライブラリLuceneに依存しています。RankerQuery は、Luceneが提供する抽象クラス Query の実装です。これはクエリのメモリ上の表現にあたります。以下の主要なメンバーを持っています。
FeatureSet- ランキングモデルで使用する特徴量のリスト
LtrRanker- ランキングモデルのうち、
FeatureSet以外の部分に対応するオブジェクト
- ランキングモデルのうち、
List<Query>- 子
Queryのリスト
- 子
詳しくは説明しませんが、ランキングモデルにおける特徴量とは、スコアを計算するためのクエリキーワードやドキュメントに関する値です。例えば、ドキュメント中でクエリキーワードが出現する回数などです。LtrRanker は、具体的な特徴量を覚えておくオブジェクト FeatureVector の用意とスコアの計算を責務とします。List<Query> が必要なのは、本プラグインでは、1つの特徴量は1つの子 Query に対応するためです。
RankerQuery のコードは以下にあります。
Query#rewrite
ここで、クエリ1つに Query オブジェクト1つが対応するのであれば分かりやすいです。しかし、実際にはそうではありませんので注意してください。すなわち、同一のクエリでも処理の途中で Query オブジェクトが変わることもあります。具体的には、Query#rewrite を呼ぶと、別の Query オブジェクトが返ります。これは、抽象的なクエリを具体的で実行可能なクエリに書き換えたり、実行の効率が悪いクエリを良いクエリに書き換えたりするメソッドです。
RankerQuery そのものに書き換えるべきところはありません。ただし、RankerQuery#rewrite は子 Query の rewrite も呼び出します。そして、そこで書き換えが行われた場合は、新しい RankerQuery を生成して返します。
@Override public Query rewrite(IndexReader reader) throws IOException { List<Query> rewrittenQueries = new ArrayList<>(queries.size()); boolean rewritten = false; for (Query query : queries) { Query rewrittenQuery = query.rewrite(reader); rewritten |= rewrittenQuery != query; rewrittenQueries.add(rewrittenQuery); } return rewritten ? new RankerQuery(rewrittenQueries, features, ranker, featureScoreCache) : this; }
RankerQuery#createWeightによるRankerWeightオブジェクトの生成
ここまで、クエリに対応する Query オブジェクトの生成を説明してきました。ここから、クエリを実行するためのオブジェクトの生成を説明していきますが、そのためにはElasticsearchにおけるクエリの実行の基本を知る必要があります。まず、Elasticsearchのインデックスは複数のセグメントに分かれています。そして、複数のセグメントに分かれたインデックス上でクエリを実行するために、異なる役割を持つ以下のオブジェクトを生成していきます。
Query- クエリに対応するオブジェクト(インデックスの状態とは独立)
Weight- あるクエリをある時点のインデックスに対して実行するためのオブジェクト
Scorer- あるクエリをある時点のインデックスのあるセグメントに対して実行するためのオブジェクト
さて、本節では Weight を説明します。前述の通り、あるクエリをある時点のインデックスに対して実行するためのオブジェクトが Weight です。Weight の生成は、Query#createWeight を IndexSearcher を引数として呼び出すことで行われます。これは、IndexSearcher が、ある時点のインデックスの状態に対応するためです。
RankerQuery#createWeight の実装は以下です。ただし、スコアが不要という特殊な場合の処理が入っていますので、そこは省略しました。
@Override public Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) throws IOException { (省略) List<Weight> weights = new ArrayList<>(queries.size()); // XXX: this is not thread safe and may run into extremely weird issues // if the searcher uses the parallel collector // Hopefully elastic never runs MutableSupplier<LtrRanker.FeatureVector> vectorSupplier = new Suppliers.FeatureVectorSupplier(); FVLtrRankerWrapper ltrRankerWrapper = new FVLtrRankerWrapper(ranker, vectorSupplier); LtrRewriteContext context = new LtrRewriteContext(ranker, vectorSupplier); for (Query q : queries) { if (q instanceof LtrRewritableQuery) { q = ((LtrRewritableQuery) q).ltrRewrite(context); } weights.add(searcher.createWeight(q, ScoreMode.COMPLETE, boost)); } return new RankerWeight(this, weights, ltrRankerWrapper, features, featureScoreCache); }
特徴的な処理としては、子 Query についても、それぞれ対応する Weight を生成しています。FeatureVectorSupplier と LtrRewritableQuery は、あまり本記事の主題の処理に関わっていないと思われますので、これらの説明は省略します。
RankerWeight#scorerによるRankerScorerオブジェクトの生成
Elasticsearch (Lucene) のインデックスはインデックスセグメントに分かれています。そして、IndexSearcher や Weight は、ある時点での検索対象のインデックスセグメントのリストを保持しています。これに対して、単一のインデックスセグメントに関するクエリ処理を行うのが Scorer です。
Weight#scorer を単一のインデックスセグメントに対応する LeafReaderContext を引数として呼び出すことで Scorer を生成できます。RankerWeight#scorer の場合は、以下の通り RankerScorer を生成します。
@Override public RankerScorer scorer(LeafReaderContext context) throws IOException { List<Scorer> scorers = new ArrayList<>(weights.size()); DisiPriorityQueue disiPriorityQueue = new DisiPriorityQueue(weights.size()); for (Weight weight : weights) { Scorer scorer = weight.scorer(context); if (scorer == null) { scorer = new NoopScorer(this, DocIdSetIterator.empty()); } scorers.add(scorer); disiPriorityQueue.add(new DisiWrapper(scorer)); } DisjunctionDISI rankerIterator = new DisjunctionDISI( DocIdSetIterator.all(context.reader().maxDoc()), disiPriorityQueue, context.docBase, featureScoreCache); return new RankerScorer(scorers, rankerIterator, ranker, context.docBase, featureScoreCache); }
例によって、子 Query に対応する子 Weight についても、それぞれ対応する子 Scorer を生成する必要があります。このとき、子 Scorer については2通りに保持しておきます。
List<Scorer>DisiPriorityQueue
通常は List<Scorer> で持っておけば良さそうですが、あえて DisiPriorityQueue でも持っています。詳しくは後述しますが、Scorer はスコアリング対象のドキュメントのイテレータを持ちます。DisiPriorityQueue は、Scorer の優先度付きキューで、Scorer のイテレータが注目しているドキュメントのIDを優先度とします。これは、全ての子 Scorer のイテレータを効率的に対象のドキュメントまで進める (advance) ために用意されているデータ構造だと思われます。ちなみにここで、Disi = Doc ID set iteratorです。
以下、RankerScorer による具体的なスコアリングについて見ていきます。
RankerScorerによるドキュメントのスコアリング
Scorer によるドキュメントのスコアリングは、スコアリング対象の各ドキュメントについて、以下を繰り返すことで行われます。
Scorer#iteratorでDocIdSetIteratorを取得し、DocIdSetIterator#advanceを、スコアリング対象のドキュメントのIDを引数として呼び出します。advanceの返り値は、イテレータが実際に注目しているドキュメントのIDです。これがスコアリング対象のドキュメントのIDと異なる場合には、スコアリング対象のドキュメントはScorerになった元のQueryとマッチしなかったということです。このとき、実際にはスコアリングの対象外になります。Scorer#scoreを呼び出すと、イテレータが実際に注目しているドキュメントのスコアが返ります。
この処理は本プラグインの外で行われます。例えば例のクエリのように rescore_query に sltr を入れた場合は、QueryRescorer#rescore で行われます。この場合、実際にはスコアリングの対象外になったドキュメントのスコアは0です。
具体的な Scorer の実装である RankerScorer の場合は、RankerScorer#iterator で独自実装の DisjunctionDISI が返ります。
そして DisjunctionDISI#advance(下記)では、まず、RankerScorer 自身が Scorer ですので、main.advance として自身のイテレータを進めます。RankerScorer にとってはどんなドキュメントもスコアリング対象ですので、自身のイテレータは全ドキュメントのイテレータ(無名クラス。DocIdSetIterator#all で取得)です。その後、全ての子 Scorer のイテレータも進める必要があります (advanceSubIterators)。このとき、先ほどの DisiPriorityQueue を使います。
この処理は、特徴量キャッシュにヒットした場合には行われませんが、この工夫については後にZOZOの取り組みの説明で詳しく説明します。
@Override public int advance(int target) throws IOException { int docId = main.advance(target); if (featureScoreCache != null && featureScoreCache.containsKey(docBase + target)) { return docId; // Cache hit. No need to advance sub iterators } advanceSubIterators(docId); return docId; }
RankerScorer#score
RankerScorer#iterator の advance の処理が終わったら、RankerScorer#score を呼ぶことができます。ここでランキングモデルが実行され、結果がスコアとして返ります。具体的には以下の処理が行われます。ただし、特徴量キャッシュについては後でまとめて説明しますので、ここでは特徴量キャッシュが無効の場合の処理を説明します。
FeatureVectorを初期化します。- 子
Scorer(1つの特徴量に対応)ごとに:- スコアリング対象のドキュメントが元のクエリとマッチするか確認します。
- マッチするなら(必ずマッチする想定ですが)、
FeatureVectorに子Scorerのスコア(1つの特徴量の値に対応)をセットします。
FeatureVectorに基づいて、ランキングモデルを実行します。
@Override public float score() throws IOException { fv = ranker.newFeatureVector(fv); if (featureScoreCache == null) { // Cache disabled int ordinal = -1; // a DisiPriorityQueue could help to avoid // looping on all scorers for (Scorer scorer : scorers) { ordinal++; // FIXME: Probably inefficient, again we loop over all scorers.. if (scorer.docID() == docID()) { // XXX: bold assumption that all models are dense // do we need a some indirection to infer the featureId? fv.setFeatureScore(ordinal, scorer.score()); } } } else { (省略) } return ranker.score(fv); }
特徴量ロギングの仕組み
ここまで、ランキングモデルの実行について説明してきました。本プラグインの主要な機能として、他に特徴量ロギング (feature score logging) があります。これは、特徴量の値をレスポンスに含めるという機能です。Elasticsearchの外部のツールでランキングモデルを機械学習するためには、Elasticsearchから特徴量の値を出力する必要があります。特徴量ロギングは、これを実現するための機能です。
特徴量ロギングのためには、例えば以下のクエリをElasticsearchに送信します(本プラグインの公式ドキュメントに基づき作成)。これは、前の例のクエリをベースとして、特徴量ロギングの指定を加えたものです。具体的には、0はじまりで0番目の rescore_query について、そこで使用しているランキングモデル (my_model) の特徴量の値をレスポンスに含めるという指定です。
ここからは、以下のようなクエリに対して、本プラグインがどのように動作しているかを説明します。
{ "query": { "match": { "_all": "rambo" } }, "rescore": { "query": { "rescore_query": { "sltr": { "params": { "keywords": "rambo" }, "model": "my_model" } } } }, "ext": { "ltr_log": { "log_specs": { "name": "log_entry1", "rescore_index": 0 } } } }
LtrQueryParserPlugin#getFetchSubPhasesによるLoggingFetchSubPhaseの挿入
Elasticsearch本体の SearchModule は、前述の通りクエリの各要素をどのコンポーネントにパースさせるかの他、FetchSubPhase のリストも管理しています。これは、ドキュメントの情報を集めて検索結果を組み立てるためのfetch phaseで行う処理のリストです。
本プラグインでは、検索結果に特徴量を挿入する必要があるので、fetch phaseに処理を追加する必要があります。このために、LtrQueryParserPlugin では、SearchPlugin#getFetchSubPhases というAPIを実装しています。LtrQueryParserPlugin#getFetchSubPhases で独自実装の LoggingFetchSubPhase を返し、SearchModule がそれを読みます。そして、fetch phaseに LoggingFetchSubPhase の処理が追加されます。
@Override public List<FetchSubPhase> getFetchSubPhases(FetchPhaseConstructionContext context) { return singletonList(new LoggingFetchSubPhase()); }
LoggingFetchSubPhase#getProcessorにおける特徴量ロギングの下準備
FetchSubPhase における処理は、FetchSubPhase#getProcessor から、FetchSubPhaseProcessor#process へと流れます。本記事では詳しくは触れませんが、この流れ自体はElasticsearch本体のコードで記述されていますので、詳しくは FetchPhase#execute あたりを参照してください。
さて、FetchSubPhase#getProcessor はクエリごとに一度だけ走る処理です。その実装である LoggingFetchSubPhase#getProcessor では特徴量ロギングの下準備をします。具体的な下準備は以下の通りです。
- 特徴量ロギング対象のクエリごとに、ロギング用のクエリ(後述します)に書き換え、対応する
HitLogConsumer(これも後述します)も生成します。- 特徴量ロギング対象のクエリがnamed queryの場合は
LoggingFetchSubPhase#extractQueryで行います。 - Rescore queryの場合は、同
extractRescoreで行います。
- 特徴量ロギング対象のクエリがnamed queryの場合は
- ロギング用のクエリを収集し、全てを
BooleanQuery(いわゆるORクエリ)としてまとめたものを用意します。以下のコードで言うとBooleanQuery.Builder builder = new BooleanQuery.Builder()からbuilder.build()までです。これがメインのクエリになります。 - メインの
BooleanQueryに対応するWeightもここで用意します。
最終的にはメインの Weight と、HitLogConsumer のリストを LoggingFetchSubPhaseProcessor に渡して、処理が終了します。
@Override public FetchSubPhaseProcessor getProcessor(FetchContext context) throws IOException { LoggingSearchExtBuilder ext = (LoggingSearchExtBuilder) context.getSearchExt(LoggingSearchExtBuilder.NAME); if (ext == null) { return null; } // NOTE: we do not support logging on nested hits but sadly at this point we cannot know // if we are going to run on top level hits or nested hits. // Delegate creation of the loggers until we know the hits checking for SearchHit#getNestedIdentity CheckedSupplier<Tuple<Weight, List<HitLogConsumer>>, IOException> weigthtAndLogSpecsSupplier = () -> { List<HitLogConsumer> loggers = new ArrayList<>(); Map<String, Query> namedQueries = context.parsedQuery().namedFilters(); BooleanQuery.Builder builder = new BooleanQuery.Builder(); ext.logSpecsStream().filter((l) -> l.getNamedQuery() != null).forEach((l) -> { Tuple<RankerQuery, HitLogConsumer> query = extractQuery(l, namedQueries); builder.add(new BooleanClause(query.v1(), BooleanClause.Occur.MUST)); loggers.add(query.v2()); }); ext.logSpecsStream().filter((l) -> l.getRescoreIndex() != null).forEach((l) -> { Tuple<RankerQuery, HitLogConsumer> query = extractRescore(l, context.rescore()); builder.add(new BooleanClause(query.v1(), BooleanClause.Occur.MUST)); loggers.add(query.v2()); }); Weight w = context.searcher().rewrite(builder.build()).createWeight(context.searcher(), ScoreMode.COMPLETE, 1.0F); return new Tuple<>(w, loggers); }; return new LoggingFetchSubPhaseProcessor(Suppliers.memoizeCheckedSupplier(weigthtAndLogSpecsSupplier)); }
RankerQuery#toLoggerQuery
LoggignFetchSubPhase#extractQuery や extractRescore を辿っていくと、RankerQuery#toLoggerQuery に辿り着きます。これは、特徴量ロギング対象のクエリを、特徴量ロギング用に書き換える処理です。具体的には以下のように書き換えます。
まず、特徴量ロギングのためには特徴量の値が出れば良く、モデルのスコアは不要です。
そこで、モデルのスコアを計算する部分である Ranker をダミーの NullRanker に置き換えます。
さらに、Ranker は特徴量の値を受け取れるので、それを利用して特徴量ロギングを行います。なので、その動作をする LogLtrRanker で NullRanker をラップする形にします。
public RankerQuery toLoggerQuery(LogLtrRanker.LogConsumer consumer) { NullRanker newRanker = new NullRanker(features.size()); return new RankerQuery(queries, features, new LogLtrRanker(newRanker, consumer), featureScoreCache); }
HitLogConsumer
HitLogConsumer は、大まかにいうと LogLtrRanker で受け取った特徴量の値を保存しておくためのオブジェクトです。
HitLogConsumer は、ドキュメントごとに呼ばれる HitLogConsumer#nextDoc でドキュメントへフィールドを追加し、そこへの参照を維持しておきます。そして、特徴量ごとに呼ばれる HitLogConsumer#accept で得られた特徴量の値を、参照を通じてフィールドへ追加します。
HitLogConsumer は LogLtrRanker.LogConsumer インタフェースを実装しており、この名前で呼ばれることもあるので注意が必要です。例えば、前述の RankerQuery#toLoggerQuery の引数の型は LogLtrRanker.LogConsumer ですが、その実装は HitLogConsumer です。
LoggingFetchSubPhaseProcessor#processにおける実際のロギング
FetchSubPhaseProcessor#process はドキュメントごとに走る処理です。LoggingFetchSubPhaseProcessor#process では、ここで実際のロギングを行います。基本的には特徴量ロギング抜きのランキングモデルの実行と同様で、イテレータを対象のドキュメントまで進めて、スコアを計算するという流れになります。このとき、これまで述べてきた通り、以下の流れで特徴量ロギングの処理が走ります。
- 特徴量ロギング対象のクエリそれぞれについて、
HitLogConsumer#nextDocでドキュメントにフィールドを追加します。 - メインの
Scorer#score(BlockMaxConjunctionScorer#score) で、全ての子Scorer(RankerScorer) につき以下を行います。ただし、以下2点に注意してください。(1) メインのクエリはBooleanQueryですが、対応するメインのScorerはBooleanScorerではなくBlockMaxConjunctionScorerです。(2) 1つの子Scorerが特徴量ロギング対象の1つのQueryに対応しますが、これらは必ずRankerScorerとRankerQueryになるはずです。- 子の
RankerScorer#scoreにおいて:LogLtrRanker#newFeatureVectorを呼びます。ここでHitLogConsumerをFeatureVectorに見せかけるためLogLtrRanker.VectorWrapperでラップします。- 全ての孫
Scorer(これ1つが1つの特徴量に相当します)について:Scorer#scoreを呼び、具体的な特徴量の値を計算します。- その値を引数として、
LogLtrRanker.VectorWrapper#setFeatureScoreを呼びます。HitLogConsumer#acceptで、特徴量の値をドキュメントのフィールドに追加します。
LogLtrRanker#scoreを呼びます。NullRanker#scoreを実行し、モデルのスコアの計算をスキップします。
- 子の
LoggingFetchSubPhaseProcessor#process の実装は以下の通りです。
public void process(HitContext hitContext) throws IOException { if (hitContext.hit().getNestedIdentity() != null) { // we do not support logging nested docs return; } Tuple<Weight, List<HitLogConsumer>> weightAndLoggers = loggersSupplier.get(); if (scorer == null) { scorer = weightAndLoggers.v1().scorer(currentContext); } List<HitLogConsumer> loggers = weightAndLoggers.v2(); if (scorer != null && scorer.iterator().advance(hitContext.docId()) == hitContext.docId()) { loggers.forEach((l) -> l.nextDoc(hitContext.hit())); // Scoring will trigger log collection scorer.score(); } }
また参考のため、RankerScorer#score の実装も以下に再掲します。
@Override public float score() throws IOException { fv = ranker.newFeatureVector(fv); if (featureScoreCache == null) { // Cache disabled int ordinal = -1; // a DisiPriorityQueue could help to avoid // looping on all scorers for (Scorer scorer : scorers) { ordinal++; // FIXME: Probably inefficient, again we loop over all scorers.. if (scorer.docID() == docID()) { // XXX: bold assumption that all models are dense // do we need a some indirection to infer the featureId? fv.setFeatureScore(ordinal, scorer.score()); } } } else { (省略) } return ranker.score(fv); }
特徴量キャッシュの仕組み
ここまでランキングモデルの実行と、特徴量ロギングについて説明してきました。ランキングモデルを継続的に改善する場合、既存のランキングモデルを実行して検索結果を返しつつ、新しいランキングモデルを学習するために特徴量ロギングを行うことになります。そしてこのとき、ランキングモデルの実行と、特徴量ロギングのためには、それぞれ特徴量の値を計算することになります。
ZOZOでは、この重複する特徴量の値の計算を効率化するため、特徴量キャッシュの機能を実装しました。ここでいう特徴量キャッシュとは、以下の動作により特徴量の値の計算を一度で済ませ、クエリ処理を高速化する機能です。
- ランキングモデルの実行の際に、計算した特徴量の値をキャッシュする
- 特徴量ロギングの際には、特徴量の値をキャッシュから取り出して返す(つまり、計算しない)
本記事の残りでは、本プラグインへの特徴量キャッシュ機能の実装について説明します。この機能はすでに追加されていますが、この機能の追加による変更点は以下のプルリクエストにまとまっていますので、適宜このプルリクエストを参照しながら説明します。
StoredLTRQueryBuilderがcache要素をサポートするように拡張
まず、特徴量キャッシュ機能のエントリーポイントとして、StoredLTRQuerybuilder に独自パラメータ cache を実装しています。プルリクエストで言うとこのファイルの変更です。
この変更により、特徴量ロギングの対象のクエリに以下の指定を入れることで、特徴量キャッシュ機能が有効になります。
"sltr": {
"model": "...",
+ "cache": true,
"params": {
...
未指定であったことを覚えておく
他の既存のパラメータと同様に実装しているため、注意点は少ないです。ただし、このパラメータが未指定(デフォルト値 false が使われる)だったのか、明示的に false 指定だったのかは覚えておく必要があることには注意してください。これは、StoredLTRQuerybuilder をクエリのJSONとして書き出すことがあり、未指定か明示するかでJSON上の表現が変わるからです。
具体的には、boolean 型ではなく Boolean 型で持っておくということです。
| JSONのパラメータの値 | JavaのBoolean の値 |
|---|---|
| 未指定 | null |
明示的に false 指定 |
false |
明示的に true 指定 |
true |
キャッシュ本体の設計
キャッシュのデータ構造は、シャード別ドキュメントIDから特徴量の値の配列への連想配列としました。具体的には Map<Integer, float[]>(ただし、特徴量キャッシュ機能が無効の際は null)です。RankerQuery.build で生成して、RankerQuery のコンストラクタに渡す実装としています。
private static RankerQuery build(LtrRanker ranker, FeatureSet features, LtrQueryContext context, Map<String, Object> params, Boolean featureScoreCacheFlag) { List<Query> queries = features.toQueries(context, params); Map<Integer, float[]> featureScoreCache = null; if (null != featureScoreCacheFlag && featureScoreCacheFlag) { featureScoreCache = new HashMap<>(); } return new RankerQuery(queries, features, ranker, featureScoreCache); }
ドキュメントIDについて
上でシャード別ドキュメントIDに言及しましたが、Lucene/ElasticsearchにおけるドキュメントIDは少なくとも3種類あります。
_idフィールドの値- シャードをまたいでもユニークなドキュメントID
- 通常、ユーザの目に触れるのはこれ
- シャード別ドキュメントID
- 特定のシャード内のドキュメントの通し番号
- セグメント別ドキュメントID
- 特定のシャード内の、さらに特定のインデックスセグメント内のドキュメントの通し番号
- この値と、インデックスセグメントごとの
docBaseという値との和が、シャード別ドキュメントID
Query オブジェクトは特定のシャード内のドキュメントだけを扱いますので、扱うドキュメントはシャード別ドキュメントIDで一意に特定できます。ですので、今回はシャード別ドキュメントIDをキャッシュのキーにすれば良いと考えられます。
キャッシュの受け渡し
キャッシュへのエントリの挿入時とキャッシュからのエントリの引き当て時には、もちろん同一の Map を使う必要があります。本プラグインにおいて、各種オブジェクトの生成フローは下図のようになっています。図中左側がランキングモデルの実行に関わるオブジェクト群で、右側が特徴量ロギングに関わるオブジェクト群です。
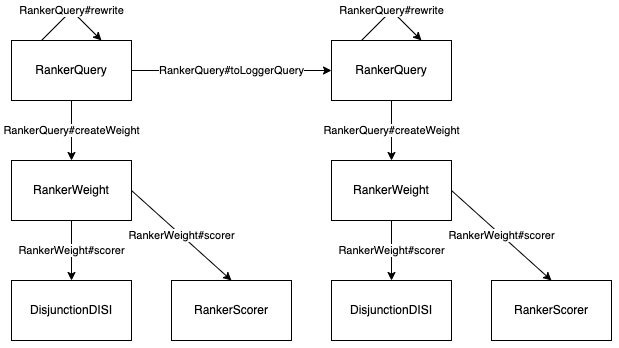
ですので、まず起点の RankerQuery(図中左上)に Map を持たせておいて、各メソッドで適切に受け渡していく必要があります。エントリの挿入は左側の RankerScorer#score で、引き当ては右側の DisjunctionDISI#advance と RankerScorer#score で行います。これらのオブジェクトは、偶然ですが全て同一のファイル RankerQuery.java に実装されており、プルリクエストで言うと以下のファイルに全ての受け渡しの処理が含まれます。
キャッシュへのエントリの挿入
ここからは、挿入と引き当てに分けて具体的な処理を説明していきます。キャッシュへのエントリの挿入は、初回の RankerScorer#score の呼び出し(ランキングモデルの実行時になるはず)で行います。キャッシュが有効の場合、ランキングモデルの実行時に、前述の既存の処理に加えて、以下の処理を行います。
- まず、特徴量の値の配列を実際に確保します。
- 次に、そこに特徴量の値を詰めます。
- 最後に、
Mapにシャード別ドキュメントIDと配列のペアを入れます。
例外処理として、もし対象ドキュメントが孫 Scorer(ある特徴量に対応する Scorer)のイテレータに含まれていなかった場合は、NaN を詰めておくことにしています。ただし、既存の処理のコメントにもある通り、この状況は本プラグイン全体を通して起こらない想定です。
} else { // Cache miss int ordinal = -1; float[] featureScores = new float[scorers.size()]; for (Scorer scorer : scorers) { ordinal++; float score = Float.NaN; if (scorer.docID() == docID()) { score = scorer.score(); fv.setFeatureScore(ordinal, score); } featureScores[ordinal] = score; } featureScoreCache.put(perShardDocId, featureScores); }
キャッシュからのエントリの引き当て
キャッシュからのエントリの引き当ては、2回目以降の DisjunctionDISI#advance および RankerScorer#score の呼び出し(特徴量ロギング時になるはず)で行います。
DisjunctionDISI#advanceでの引き当て
特徴量ロギングの対象ドキュメントまで全ての孫 Scorer(ある特徴量に対応する Scorer)のイテレータを進める処理にはコストがかかります。しかし、キャッシュにエントリが含まれている場合、そもそも特徴量を改めて計算する必要もイテレータを進める必要もないため、いわゆるearly returnを実装しました。以下に当該のソースコードを再掲します。
@Override public int advance(int target) throws IOException { int docId = main.advance(target); if (featureScoreCache != null && featureScoreCache.containsKey(docBase + target)) { return docId; // Cache hit. No need to advance sub iterators } advanceSubIterators(docId); return docId; }
RankerScorer#scoreでの引き当て
2回目以降の RankerScorer#score の呼び出し(特徴量ロギング時になることを想定)では、特徴量の値を計算する必要はなく、キャッシュから引き当てることができます。具体的には、前述の既存の処理に比べて、孫 Scorer の score メソッドを呼ばなくなっています。ここが特徴量キャッシュの主要な効果になると期待されます。コードでは以下の箇所です。
if (featureScoreCache.containsKey(perShardDocId)) { // Cache hit float[] featureScores = featureScoreCache.get(perShardDocId); int ordinal = -1; for (float score : featureScores) { ordinal++; if (!Float.isNaN(score)) { fv.setFeatureScore(ordinal, score); } } } else { // Cache miss
まとめ
本記事では、以下を解説しました。
- OpenSource Connections Elasticsearch Learning to Rank pluginの仕組み
- ランキングモデルの実行の仕組み
- 特徴量ロギングの仕組み
- 本プラグインの処理の効率化のためにZOZOで実装した、特徴量キャッシュ機能
ZOZOでは、検索機能を開発・改善していきたいエンジニアを全国から募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!