




はじめに
こんにちは。検索基盤部の倉澤です。
検索機能におけるtypo(誤字脱字や綴り間違いなど)は難しい問題1とされています。typoの扱い方によってはユーザーに悪い検索体験を提供してしまう恐れがあります。例えば、typoを含む検索クエリを入力された時にユーザーが意図している検索結果を得ることができないといった問題があります。
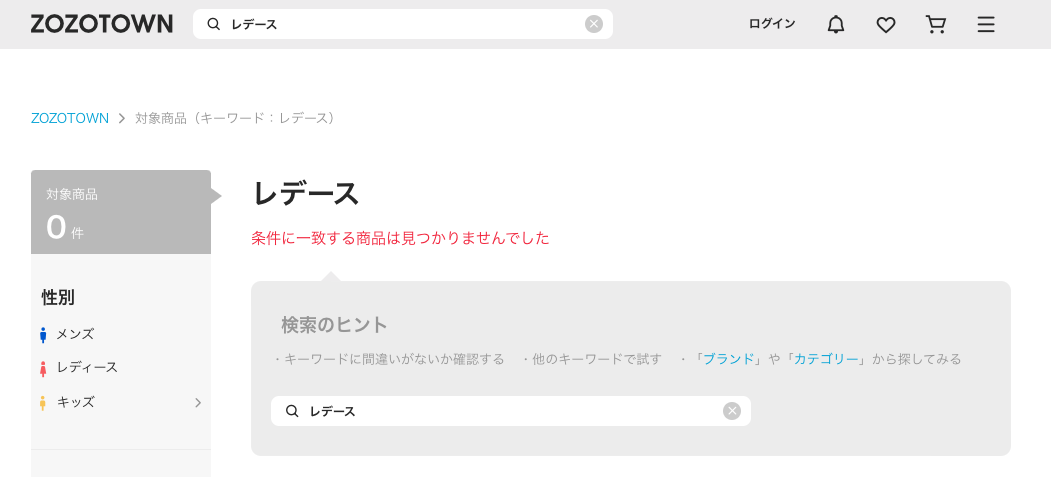
例に漏れず、ZOZOTOWNでもtypoを含む検索クエリが入力された場合に検索結果が表示されないといった問題が発生しています。以下、「レディース」と入力するつもりが「レデース」と入力してしまった場合の検索結果です。
今回は日本語におけるtypoの一般的な解決策を調査・検証し、その結果・課題点を紹介します。手法の検証が容易であることを優先し、以下の2つの方法について検証しました。
- Elasticsearchを用いてtypoを含む検索クエリでも検索結果を得る方法
- ユーザーの検索クエリログを用いてtypoを正しいクエリに修正する方法
目次
Elasticsearchを用いた検索時のtypoの扱い方
本章では、Elasticsearchを用いてtypoを含む検索クエリでも検索結果を得る方法について説明します。1つ目はFuzzy match(あいまい検索)と呼ばれる手法で、ユーザーが完全な検索クエリを入力しなくても、関連する結果を得られるようにします。2つ目はSynonym token filterを用いた手法で、typoクエリを修正クエリへ変換し検索結果を得られるようにします。
以下の表に、それぞれの手法の概要と、精度と運用コストの観点からの評価をまとめました。
| 手法 | 概要 | 精度 | 運用コスト |
|---|---|---|---|
| Fuzzy match | ElasticsearchのQuery DSLで用意されているFuzzy queryを用いたあいまい検索により検索結果を返す | Not Good 入力されたクエリの文字数に対するfuzzinessの設定など検索結果をコントロールするのが難しい |
Good ElasticsearchのVersionによるメンテナンス程度で負担が小さい |
| Synonym token filter | ElasticsearchのSynonym token filterによりtypoクエリから正しいクエリへ展開し検索結果を返す | Good Synonym token filterで定義しているクエリによってヒットする結果をコントロールすることができる |
Not Good 新しいtypoクエリが発見された場合にSynonym token filterの定義に追加するコストが発生し続ける |
Fuzzy match
Elasticsearchには、あいまい検索を実現するためにFuzzy queryが用意されています。Fuzzy queryは、レーベンシュタイン距離(以下、編集距離と呼ぶ)によりtypoを含む検索クエリでも検索結果を返すことができます。
編集距離は、ある文字列を別の文字列へ変換するために必要な操作回数を表します。具体的には、以下の4つの操作を用いて文字列を変換します。
- 文字の挿入
- 文字の削除
- 文字の置換
- 文字の転置
例えば、「レデース」という文字列を「レディース」に変換する場合、文字の挿入を1回行えば変換ができます。この場合の編集距離は1となります。
Fuzzy queryでは、この編集距離をfuzzinessというパラメータを用いて指定でき、設定した値を最大値として範囲内に収まるキーワードをマッチさせることが可能です。
一方、Fuzzy queryには検索結果をコントロールするのが難しいという問題点があります。指定の編集距離内であれば、どのようなクエリでも検索結果を返してしまうため、関連しない結果がヒットしてしまう可能性があります。特に文字数が少ないクエリの場合は、指定の編集距離内に収まるクエリが多くなり、この問題が顕著になります。
例えば、ユーザーがズボンに関連する商品を探しており「ズボン」と入力するつもりが「ザボン」と入力してしまった場合について考えます。
GET kurasawa_test_index/_search { "query":{ "match": { "keyword": { "query": "ザボン", "fuzziness": "AUTO" } } } }
上記の検索クエリを実行すると、以下のような結果が返ってきます。
... "hits" : [ { "_index" : "kurasawa_test_index", "_id" : "xxx", "_score" : xxx, "_source" : { "keyword" : "ズボン", ... } }, { "_index": "kurasawa_test_index", "_id" : "xxx", "_score" : xxx, "_source" : { "keyword" : "リボン", ... } }, { "_index": "kurasawa_test_index", "_id" : "xxx", "_score" : xxx, "_source" : { "keyword" : "おぼん", ... } }, ]
上記の検索結果を見てみると、ユーザーが意図している「ズボン」がヒットしていることがわかります。しかし、「リボン」や「おぼん」もヒットしていることがわかります。これらは「ザボン」に対する編集距離が1であることからヒットしており、ユーザーが意図していない結果もヒットしてしまっています。
このようにFuzzy queryではユーザーが意図していない結果もヒットしてしまうため、検索結果をコントロールするのが難しいという問題点があります。
過去の検索クエリのログからtypoのクエリとそれに対応する修正クエリが傾向として把握できている場合は、次章のSynonym token filterを用いることで検索結果をコントロールできます。
Synonym token filter
検索時のAnalyzerにSynonym token filterを追加することで、typoクエリから修正クエリへ変換し検索結果を返すことができます。Fuzzy queryとは異なり、予め定義した正しいクエリへと変換できるため、検索結果をコントロールできます。
以下に、Synonym token filterによる検証手順を説明します。前項の例を元に「ザボン」を「ズボン」に変換するようにSynonym token filterを定義します。
# インデックスの作成 PUT /kurasawa_test_synonym # アナライザーの定義 PUT kurasawa_test_synonym/_settings { "analysis": { "filter": { "my_synonym_filter": { "type": "synonym", "synonyms":[ "ザボン=>ズボン" ] } }, "analyzer": { "my_index_analyzer": { "type": "custom", "tokenizer": "kuromoji_tokenizer" }, "my_search_analyzer":{ "type":"custom", "tokenizer": "kuromoji_tokenizer", "filter":[ "my_synonym_filter" ] } } } } # マッピングの定義 PUT kurasawa_test_synonym/_mapping { "properties":{ "keyword": { "type":"text", "analyzer": "my_index_analyzer", "search_analyzer":"my_search_analyzer" } } } # ドキュメントの登録 POST /kurasawa_test_synonym/_bulk {"index": {"_id": 1}} {"keyword": "ズボン"} {"index": {"_id": 2}} {"keyword": "リボン"} {"index": {"_id": 3}} {"keyword": "おぼん"}
上記で定義したインデックスに対して、以下の検索クエリを実行します。
GET kurasawa_test_synonym/_search { "query": { "match": { "keyword": "ザボン" } } }
以下の検索結果から、ユーザーが意図している「ズボン」のみがヒットしていることがわかります。
{ ... "hits" : [ { "_index" : "kurasawa_test_synonym", "_id" : "xxx", "_score" : xxx, "_source" : { "keyword" : "ズボン" } } ] } }
このようにSynonym token filterを用いることで、typoクエリから修正クエリへ変換し検索結果をコントロールできます。
ただし、Synonym token filterを用いる場合は、予めtypoクエリと正しいクエリの対応を把握しておく必要があります。さらに、新しくtypoと思われるクエリが発見された場合は都度filterに定義を追加するなどの運用コストがかかります。そのため、Synonym token filterを用いるかどうかは、検索結果に対する精度と運用コストのバランスから判断する必要があります。
ユーザーの検索クエリログを用いたスペルコレクション
本章では検索する前にtypoクエリを修正することを想定したスペルコレクションの手法を紹介します。また、今回紹介する手法はユーザーの検索クエリのログを用いた手法です。
| 手法 | 概要 | 精度 |
|---|---|---|
| Peter Norvig, "How to Write a Spelling Corrector"を元にしたスペルコレクション | Peter Norvig, "How to Write a Spelling Corrector"の提案手法を日本語に適用するために改良した方法。typoクエリに対する修正候補を編集距離を用いて生成し、文章中の出現確率が最大となるクエリを出力する | ZOZOTOWNのデータを用いて検証した結果、正しく修正できたクエリの割合: 69% |
| 再検索クエリログを用いたスペルコレクション | 各ユーザーの連続する検索クエリログから再検索されたクエリを修正候補のクエリとみなし、出現確率が最大となるクエリを出力する | ZOZOTOWNのデータを用いて検証した結果、正しく修正できたクエリの割合: 14% |
Peter Norvig, "How to Write a Spelling Corrector"を元にしたスペルコレクション
Peter Norvig, "How to Write a Spelling Corrector"の提案手法がスペルを修正する手順を簡単に説明します。具体的な手法については、文献を参照してください。
- 文章中の各クエリの出現頻度を算出する
- typoクエリに対する編集距離1の文字列を生成し、手順1の文章中に存在するクエリを修正候補のクエリとする
- typoクエリに対する編集距離2の文字列を生成し、手順1の文章中に存在するクエリを修正候補のクエリとする
- 修正クエリを以下の優先順位で決定する
- 4.1. 編集距離0の文字列が手順1の文章中に存在すれば、入力されたクエリを修正クエリとする
- 4.2. 手順2の修正候補クエリが存在すれば、その中から出現頻度が一番高いクエリを修正クエリとする
- 4.3. 手順3の修正候補クエリが存在すれば、その中から出現頻度が一番高いクエリを修正クエリとする
- 4.4. 入力されたクエリを修正クエリとする
この提案手法を日本語に適用しZOZOTOWNのデータを用いて検証するためには、以下の点が課題になりました。この課題に対する原因と解決策を記載します。
| 課題 | 原因 | 解決策 |
|---|---|---|
| ファッション用語に特化したコーパスの準備 | ファッション用語に特化した外部公開されたコーパスが存在しない | ZOZOTOWNのユーザーの検索クエリのログを用いる |
| 日本語で編集距離1または2の文字列を生成する際の計算量が膨大 | 漢字・カタカナ・ひらがなの文字数を2000文字とすると、長さnの文字列に対する編集距離1の文字列を生成するための操作回数は、削除(n回)と置換(2000n回)、転置(n-1回)、挿入(2000(n+1)回)の合計4002n+1999回が必要となる | 編集距離1または2の文字列の中から既知のクエリの集合を取得する処理をElasticsearchのFuzzy matchを用いる |
ElasticsearchのFuzzy matchを用いることで、編集距離1または2の文字列の中から修正候補となる既知のクエリの集合を取得する処理の高速化がのぞめます。Peter Norvig, "How to Write a Spelling Corrector"の実装を一部変更し、ElasticsearchのFuzzy matchを用いたスペルコレクションを実装しました。
# 各クエリの出現頻度を保持する辞書 TERM_FREQ = { "ズボン": 10, "リボン": 5, "おぼん": 2 } # Fuzzy queryを実行するためのクエリ ES_QUERY = { "query": { "fuzzy": { "keyword": { "value": "", "fuzziness": "2" } } }, "size": 20 } # Elasticsearchのインデックス名 ES_INDEX_NAME = "kurasawa_test_index" # Fuzzy matchを用いて編集距離1または2の文字列の中から修正候補となる既知のクエリの集合を取得する関数 def edit(es_client, word): ES_QUERY["query"]["fuzzy"]["keyword"]["value"] = word result = es_client.search(index=ES_INDEX_NAME, body=ES_QUERY) return set(hit["_source"]["keyword"] for hit in result["hits"]["hits"]) def known(word): return set(w for w in word if w in TERM_FREQ) def correct(es_client, word): candidates = known([word]) or edit(es_client, word) or [word] return max(candidates, key=lambda w: TERM_FREQ.get(w, 0)) correct(es_client, "ザボン") >> "ズボン"
今回、上記の解決策を用いてスペルコレクションを実装した結果の評価結果を以下に記載します。評価方法は、Peter Norvig, "How to Write a Spelling Corrector"の「Evaluation」の章で紹介されている方法を用いて、独自に準備した正解データ約50件に対して、修正されたクエリが正解データと一致しているかどうかを確認しました。
| 検索クエリログ | 評価結果 |
|---|---|
| 過去1週間 かつ 検索回数が100回以上の検索クエリログ | 正しく修正できたクエリの割合: 69% |
約70%のクエリを正しく修正できていますが、以下のような課題も残っています。
- 出現回数を保持する辞書に存在しないが、typoではないクエリを誤変換してしまう可能性がある
- 正しいクエリよりも出現回数が多いtypoクエリを修正候補として返してしまう可能性がある
再検索クエリログを用いたスペルコレクション
各ユーザーの連続する検索クエリのログから起点になるクエリとその直後に発生する再検索クエリを1つのペアとします。このクエリ同士の編集距離と検索ログ内でのペアの発生確率から修正クエリを見つけることを考えます。
例えば以下のような検索クエリログがあったとします。
| ユーザーID | クエリ | 再検索クエリ |
|---|---|---|
| A | ザボン | ズボン |
| B | ザボン | ズボン |
| C | ザボン | リボン |
「クエリ」と「再検索クエリ」をペアとして、発生確率と編集距離を計算します。
| (クエリ, 再検索クエリ) | 発生確率 | 編集距離 |
|---|---|---|
| (ザボン, ズボン) | 2/3 | 1 |
| (ザボン, リボン) | 1/3 | 1 |
編集距離2以下のペアに限定し、発生確率が最大となる再検索クエリを修正クエリとします。つまり、上記の例では「ザボン」を「ズボン」に修正します。
これらの簡易的な手順を実装すると以下のようになります。
import pandas as pd import Levenshtein def correct(df, word): result = {} for record in df[df["query"]==word].values: query = record[0] next_query = record[1] ratio = record[2] distance = Levenshtein.distance(query, next_query) if distance < 3: result[next_query] = ratio return max(result, key=result.get) df = pd.DataFrame( data={ "query": ["ザボン", "ザボン"], "next_query": ["ズボン", "リボン"], "ratio": [0.6666, 0.3333] } ) word="ザボン" correct(df, word) >> "ズボン"
こちらの手法も、前章で紹介した手法と同様に評価しました。また、正解データも同様のものを用いました。
| 検索クエリログ | 評価結果 |
|---|---|
| 過去1週間 かつ 検索回数が100回以上の検索クエリログ | 正しく修正できたクエリの割合: 14% |
以下の課題により、前章で紹介した手法よりも精度が低くなってしまいました。
- 過去の検索クエリのログにない未知なtypoクエリを修正することが出来ない
- ユーザーがtypoに気づかず再検索クエリのログに正しいクエリが存在しない場合に修正することが出来ない
さいごに
今回はElasticsearchを用いた検索時のtypoへの対応方法とtypoを修正するためのスペルコレクションについて紹介しました。
検索におけるtypoは、検索結果の精度やユーザー体験を低下させる要因となります。一方で、日本語は漢字、カタカナ、ひらがなといった複数の文字で構成されていることや同音異義語、多様な表記揺れにより、一般的にtypoの修正は難しいとされています。
ZOZOTOWNの検索機能でもtypoへの対応にはまだまだ課題があります。引き続き検索精度の向上に取り組んでいきます。
ZOZOでは一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
- 書籍「Query Understanding for Search Engines」にも同様な言及がなされています。↩