



こんにちは。ECプラットフォーム部データエンジニアの遠藤です。現在、私は推薦基盤チームに所属して、データ集計基盤の運用やDMP・広告まわりのデータエンジニアリングなどに従事しています。
以前、私たちのチームではクエリ管理にLookerを導入することで、データガバナンスを効かせたデータ集計基盤を実現しました。詳細は、以前紹介したデータ集計基盤については以下の過去記事をご覧ください。
本記事では、データ集計基盤に「データバリデーション」の機能を加えて常に正確なデータ集計を行えるように改良する手段をお伝えします。
データバリデーションとは
データバリデーションとはデータの安全性・妥当性を確認・検証することです。データバリデーションは以下の視点から検証することが一般的です。
- データ型:型(Int・Stringなど)として妥当なデータか
- データ形式:データの形式(「空値が許されるか?」「指定された範囲内の値であるか?」など)として妥当なデータか
- ビジネスロジック:開発時に定めた集計定義的に妥当なデータか
今回は上記に示された3つの観点から、絶えず流れてくるデータが集計仕様どおりになっているかを検証することでデータ集計における正確性向上へのさらなる改善を図ります。
RDBではテーブルの各カラムにおけるデータの型があらかじめ定められているので、「データ型」における妥当性はデータ集計開始時には既にクリアしています。一方、「データ形式」・「ビジネスロジック」における妥当性は依然不明であり、データ集計前に何らかの方法で検証することが必要です。
バリデーション導入後のデータ集計基盤
データマートの更新は、GCPのApache AirflowマネージドサービスであるCloud Composerを用いたデータ集計基盤を構築することで実現しています。Apache AirflowはPythonで定義したワークフローをスケジュール・モニタリングするためのプラットフォームです。
なお、Cloud Composer・Apache Airflowの詳しい説明はここでは省きます。Cloud Composer公式サイト・Airflow公式サイトをそれぞれご覧ください。
まず、BigQueryへのデータ取り込み完了直後にCloud Pub/SubをKickして、Cloud Functions経由でデータ集計基盤を起動させます。
従来は起動後すぐにデータマートを更新していましたが、今回はデータマート更新で用いるデータ群が全て妥当なデータであることを確認してからデータマートを更新するようにします。以下の図は、データ取り込み完了後からCloud Composer内の処理までを、データバリデーション導入前後で比較したものです。
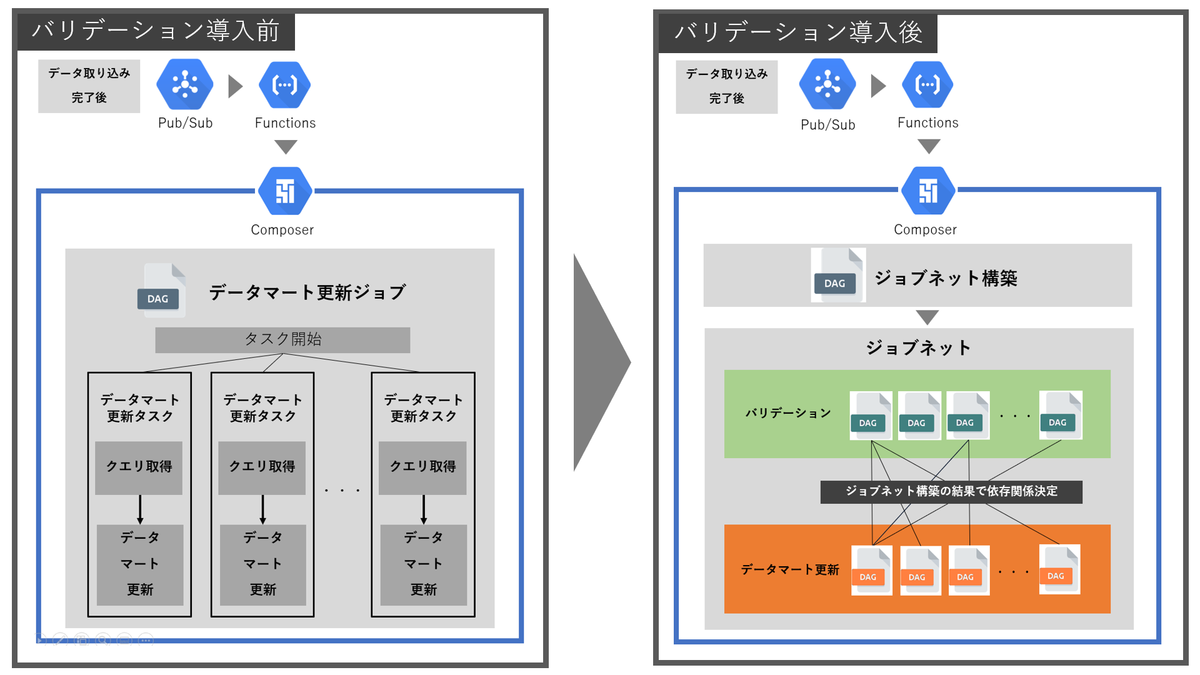
データバリデーション導入前後のフローを比較すると、導入後はジョブネット構築・バリデーションが主に追加されています。これらを次項で説明します。
ジョブネット構築
Cloud Composerでは、個々の処理をタスクと呼び、タスクに名前をつけ処理内容を記述します。そして、それらのタスクの依存関係をDAG(有向非巡回グラフ)で定義することによりワークフローを構築します。DAGの作成方法の詳細はCloud Composer公式ページ内の「DAG(ワークフロー)の作成」をご覧ください。
基本的にCloud Composerにおけるワークフローは1つのDAG内で定義します。しかし、ワークフローの規模が大きくなるにつれてタスクの依存関係が複雑になりDAGが肥大化するといった管理面でのデメリットが発生します。
DAGの肥大化を防ぐため、ワークフローを複数のDAGを組み合わせたジョブネットとして定義するように構築します。なお、ジョブネットとは一般的には実行順序を指定した1つ以上のジョブの集まりのことを指します。
ジョブネットでは2種類のDAGを作成します。
- バリデーションDAG:バリデーションのタスクを行うDAG。バリデーション項目数と同じ数だけ作成される。
- データマート更新DAG:データマート更新のタスクを行うDAG。依存するバリデーションDAG全てが正常終了しなければ起動しないようにする。更新するデータマート数と同じ数だけ作成される。
バリデーションDAGとデータマート更新DAG間の依存関係はワークフロー内で自動的に設定するようにします。ワークフロー全体の最初のステップとして、この依存関係を把握してジョブネットを構築します。
具体的に言うと、バリデーション・データマート更新でそれぞれ使用する全クエリを取得してクエリ構文を解析します。以下の図のように、データマート更新クエリから集計元テーブルを割り出し、その集計元テーブルと各バリデーションのクエリで用いるテーブルを一致させることで依存するDAG同士を結びつけていきます。

このように、クエリ解析で得られたDAG間の依存関係データはCloud Composer環境にカスタムプラグインとしてインストールすることで、実行順序が動的に変化するジョブネットを構築しました。
さて、Cloud Composerでジョブネットを構築するにあたり、以下の工夫した2点について解説します。
- テンプレートによる効率的なDAGの作成
- DAG間の依存関係の設定方法
テンプレートによる効率的なDAGの作成
バリデーションDAG・データマート更新DAGは関数でDAGのテンプレートをそれぞれ用意して、引数に任意の値を渡すことでDAGを作成します。例えば、バリデーションDAGにおけるコーディングは以下のようになります。
from airflow.models import DAG def validation_dag(validation_info): dag_id = "validation_" + validation_info['validation_id'] dag = DAG(dag_id, default_args=default_args, schedule_interval=None, catchup=False) # 中略 return dag for validation_info in validation_config: validation_id = validation_info['validation_id'] globals()[validation_id] = validation_dag(validation_info)
バリデーションDAGのテンプレートを関数 validation_dag で作成します。なお、引数はバリデーションの詳細情報を格納した配列、返り値はDAGのオブジェクトです。
関数 validation_dag を呼び出した結果をグローバル変数に格納すれば、バリデーションDAGが効率的に作成されるようになります。
DAG間の依存関係の設定方法
Cloud ComposerではDAG内のタスクを定義する際にAirflowで用意されているOperatorを用います。異なるDAG同士の依存関係を設定するには、ExternalTaskMarker・ExternalTaskSensorというOperatorを用います。
ExternalTaskMarker(Airflow Version 1.10.8以降に実装)は別のDAGのタスクを実行させるOperatorです。以下のコード例のように external_dag_id と external_task_id に後続の別のDAGのタスクを指定します。
from airflow.sensors import external_task_sensor start_following_dag_task = external_task_sensor.ExternalTaskMarker( task_id=f"start_following_dag_{update_datamart_dag_id}", external_dag_id=f"{update_datamart_dag_id}", external_task_id=f"start_update_{update_datamart_table_name}", execution_date = "{{ execution_date }}", dag=validation_dag,)
一方、ExternalTaskSensorは別のDAGのタスクのステータスを定期的に確認するOperatorです。以下のコード例のように external_dag_id と external_task_id に先行の別のDAGのタスクを指定します。
from airflow.sensors import external_task_sensor verify_leading_dag_task = external_task_sensor.ExternalTaskSensor( task_id=f"verify_leading_dag_{validation_dag_id}", external_dag_id=f"{validation_dag_id}", external_task_id=f"check_status_{validation_dag_id}", timeout=600, allowed_states=['success'], failed_states=['failed', 'skipped'], execution_date_fn=lambda dt:dt + timedelta(0), mode="reschedule", dag=update_datamart_dag,)
ExternalTaskSensorのタスクでは、指定した対象タスクのステータスを定期的に確認します。タスク verify_leading_dag_task のステータスはそのステータスが allowed_states と同じステータスにならなければ success になりません。これにより正常終了が必須である先行ジョブの依存関係が設定できます。
このように、以上に挙げた2つのOperatorを用いたタスクをDAGに組み込むことで複数のDAG間の依存関係を実装しています。
バリデーションDAGのタスク構成
バリデーションDAGは以下の図に示されるタスクのフローで構成されます。
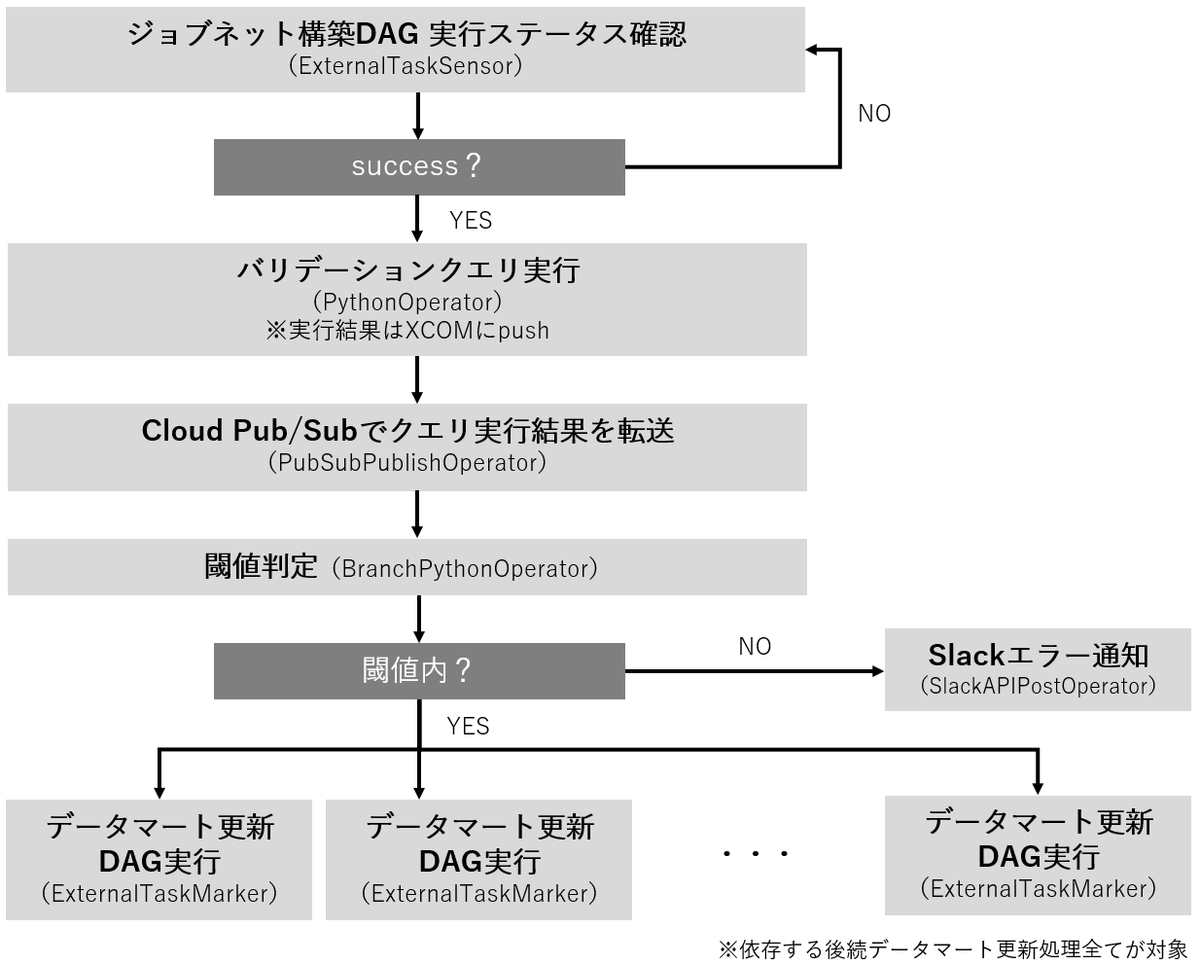
先行の依存関係であるジョブネット構築DAGにおける最後のタスクのステータスが success になるまでバリデーションDAGの実行を待機します。success になったことを確認したらバリデーションクエリを実行します。
バリデーションクエリの実行結果はCloud Pub/Subを用いてデータ転送します。これは今後Dataflowを用いてBigQueryテーブルに蓄積させたりすることでバリデーション結果を時系列で解析できるようにするためです。
次に、実行結果が閾値内であるかどうかを判定します。閾値内であれば依存する後続のデータマート更新DAGを実行させるようにして、逆に閾値内でなければエラー処理としてSlackにメッセージを送ることで不具合を通知します。
これにより、データマートへはデータバリデーションで妥当性が示されたデータのみ更新するようにします。逆に、データバリデーションでエラーが生じたデータを含むものは更新を全て意図的に止めることで、データマート更新前にクエリなどを修正するように促します。
ちなみに、Apache Airflowにはクエリ実行結果をチェックするタスクのOperatorであるBigQueryValueCheckOperatorが用意されています。しかし、今回はバリデーション結果の閾値判定を柔軟に処理できるPythonOperatorを使用しました。
まとめ
データ集計基盤にデータの質を担保する処理「データバリデーション」を導入することで、集計結果への正確さの向上を図った取り組みを紹介しました。
データバリデーションのおかげで仕様変更などでデータに変化が生じた場合に適切なタイミングでアラートされるようになりました。そのアラートに対応することで、データの仕様が常に把握できている状態になり、仕様に即さない集計結果が出力されることはなくなりました。
また、Cloud Composer上で動的にジョブネットを構築する仕組みも提案しました。これにより、複雑で動的に変化する依存関係を伴うワークフローが手動で逐一設定することなく効率よく定義できるようになりました。
近年では膨大なデータを貯めておくことが容易になった反面、意図しない集計トラブルやコスト的に非効率な集計を起こしやすくなりました。
本記事が、膨大なデータに対する集計のクオリティ管理に関する問題を解決し、データガバナンス強化の足がかりを作る手助けになれば幸いです。
このように、推薦基盤チームではさまざまなシステムを支援するデータ集計基盤の開発・運用に取り組んでいます。チームメンバーを絶賛募集していますので、ご興味のある方は以下のリンクからぜひご応募ください!