



こんにちは。技術戦略部の廣瀬です。
弊社ではサービスの一部にSQL Serverを使用しています。SQL Serverの各バージョンにはMicrosoftのサポート期間が設定されています。直近ではSQL Server 2012のサポートが、2022年7月12日に終了します。サポートが切れる前にSQL Serverのバージョンを上げる必要がありますが、既存環境で実行中のSQLがバージョンアップ後も正常に動作するか事前検証が必要です。
本記事では、このクエリ互換性に関する検証精度を向上させた事例を紹介します。
クエリ互換性の検証方法
SQL Serverをバージョンアップする際のクエリ互換性を検証するための補助ツールとして、Data Migration Assistant(以下、DMAと呼ぶ)というツールが提供されています。このツールを使うと、例えば以下のようなクエリ互換性に関するアドバイスを確認できます。

移行元のバージョン及び互換性レベルから、移行先のバージョンで各互換性レベルを選択した場合のクエリ互換性に関する問題を自動で検出してくれます。画像の例では互換性レベル110のSQL Server 2012から、SQL Server 2019にバージョンアップする場合の分析結果です。互換性レベル110と120では4項目、130以上だと5項目の指摘事項があると分かります。このように、バージョンだけでなく指定する互換性レベルによっても指摘事項数が変わってきます。
「Unqualified Join(s) detected」という指摘では、明示的に「JOIN」を指定しないと稀にスロークエリ化することがあるという問題が説明されています。このように、バージョンアップの際に対応が必要な項目を自動で検出してくれるため便利なツールですが、課題も存在します。
DMAの課題
DMAでは、ストアドプロシージャや関数など、SQL Serverが持っているオブジェクトは互換性の有無を検証してくれます。ですが、アプリケーション側に記述されているSQLについては検証してくれません。アプリケーション側で記述されているクエリは、拡張イベントで「sql_batch_completed」を取得して結果ファイルをDMAに入力することで互換性の検証が可能です。しかし、プロダクション環境で実行されている全てのクエリを拡張イベントで収集することは負荷的なオーバーヘッドの面で許容できない場面があるかと思います。そのため、アプリケーション側で記述されているクエリの互換性をDMAを使ってより安全に検証するためには、別の方法が必要となります。以降では、私たちがとった手段をご紹介します。
アプリケーション側に記述されたクエリ互換性をDMAで検証する方法
DMAでは、アセスメントを開始する前にアドホッククエリのデータを入力できる箇所があります。「Learn more」のリンク先の記事では、ファイルの生成方法が説明されています。
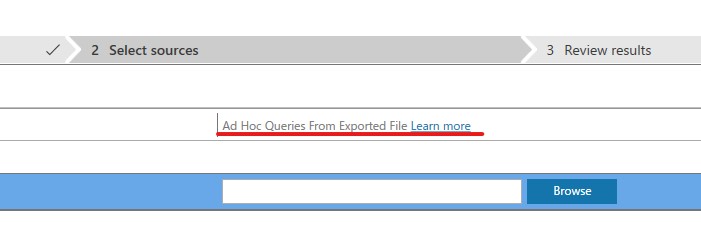
リンク先の記事によると、Visual Studio Codeの拡張機能である「Data Access Migration Toolkit」を使用します。この機能を使うと、DMAにインプットするjsonファイルを生成できます。「Data Access Migration Toolkit」がサポートしているファイル形式は以下の通りです。
- Java
- C#
- XML
- JSON
- Properties
- SQL files
- Plain text / Unstructured
今回調査したいアプリケーションのファイル形式はサポート対象外だったため、プログラムファイルを直接入力に使うことはできません。したがって、以下の手順をとることにしました。
- 実際に実行されたクエリテキストを収集
- 収集したクエリテキストを「Data Access Migration Toolkit」に入力
- 生成されたjsonファイルをDMAに入力して互換性を検証
以降で順番に説明します。
1. 実際に実行されたクエリテキストを収集
拡張イベントは前述の通りオーバーヘッド増加の懸念が理由で使用できません。代りに、DMVの一種である「sys.dm_exec_query_stas」を使用します。このDMVは実行されたクエリのパフォーマンス統計を保持しているDMVなので、アプリケーション側に記述されているクエリも収集が可能です。まず、収集用のテーブルを作成します。
select max(dbid) as dbid ,query_hash ,cast(max(qt.text) as nvarchar(max)) as query_text ,max(execution_count) as max_execution_count ,1 as updated_count ,getdate() as created_at ,getdate() as updated_at into dm_exec_query_stats_dump from sys.dm_exec_query_stats qs outer apply sys.dm_exec_sql_text(qs.plan_handle) as qt where qt.text is not null and objectid is null --procedure / function / trigger等を除外 and qt.text not like '%api_cursor%' group by query_hash
今回の調査で「何回実行されたか」はそこまで重要な情報ではありません。1回でも実行されたクエリは互換性をDMAで検証すべきです。そのため、テーブルのサイズ増大を抑制するために「query_hash」でgroup byを行います。また、ストアドプロシージャなどのオブジェクトは今回取得する必要はないため、objectidがnullなデータだけを収集対象とします。あとは以下のクエリをSQL Serverのエージェントジョブで実行して、1分間ごとにキャッシュの情報をupsertしていきます。
set nocount on set lock_timeout 1000 set transaction isolation level read uncommitted while (1=1) begin merge dm_exec_query_stats_dump as target using ( select max(dbid) as dbid ,query_hash ,cast(max(qt.text) as nvarchar(max)) as query_text ,max(execution_count) as max_execution_count ,1 as updated_count from sys.dm_exec_query_stats qs outer apply sys.dm_exec_sql_text(qs.plan_handle) as qt where qt.text is not null and objectid is null --procedure / function / trigger等を除外 and qt.text not like '%api_cursor%' group by query_hash ) as source on target.query_hash = source.query_hash when matched then update set max_execution_count = (case when source.max_execution_count > target.max_execution_count then source.max_execution_count else target.max_execution_count end) ,updated_count = target.updated_count + 1 ,updated_at = getdate() when not matched then insert (dbid, query_hash, query_text, max_execution_count, updated_count, created_at, updated_at) values (source.dbid, source.query_hash, source.query_text, source.max_execution_count, 1, getdate(), getdate()) option (maxdop 1); waitfor delay '00:01:00' if (getdate() >= '2022/04/01') return end
収集期間は数日から、最長でも1か月間収集すれば月次で実行されるレアなクエリも収集できるかと思います。収集後のテーブルの中身はこのようになっています。
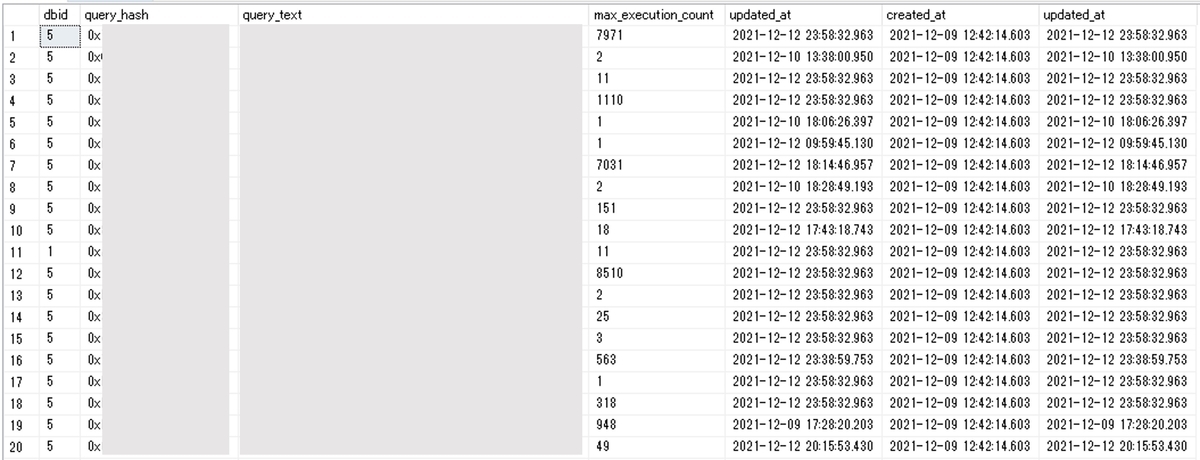 弊社の環境では、1DBあたり5000種類ほどのクエリを収集できたケースもありました。
弊社の環境では、1DBあたり5000種類ほどのクエリを収集できたケースもありました。
2. 収集したクエリテキストを「Data Access Migration Toolkit」に入力
続いて、収集したデータを「Data Access Migration Toolkit」に入力し、DMAが解釈可能なjson形式に変換します。サポートファイルとして「SQL files」とあったため、収集したSQLを1まとめにしたファイルを作成して入力してみました。ファイルの中身は以下のようになっていました。
(@P1 int)select * from table_1 where ... (@P1 int,@P2 datetime,@P3 int,@P4 int)select col_1, col_2 from table_2 where ... ... (@P1 int)select col_n from table_n where ...
jsonファイルは正常に出力されましたが、中身は以下のようになっていました。
{
"SqlDialect": "t-sql",
"Workspaces": [
{
"Path": "SOME_PATH\DMA\\sql",
"Issues": [
{
"File": "file:///SOME_PATH/DMA/sql/input.sql"
}
]
}
]
}
この形式では正しいjsonファイルを生成できないようです。したがって、別のサポート対象のファイル形式であるXMLに変換してみました。まずはシンプルにタグでクエリ全体を囲ってみました。
<xml> (@P1 int)select * from table_1 where ... (@P1 int,@P2 datetime,@P3 int,@P4 int)select col_1, col_2 from table_2 where ... ... (@P1 int)select col_n from table_n where ... </xml>
このxmlファイルを入力したところ、where句などに不等号が入っていることでxmlのパースでエラーとなり、上手くいきませんでした。そこで、各ステートメントをCDATAセクションで囲うことにしました。これにより「]]>」という文字列以外は通常の文字として解釈してくれます。ファイルは以下のようになります。
<xml> <![CDATA[ (@1 int)SELECT * form some_table_1 where ... ]]> <![CDATA[ (@P1 int)SELECT * form some_table_2 where ... ]]> </xml>
このxmlファイルを入力したころ、以下のようなjsonファイルが生成されました。
{ "SqlDialect": "t-sql", "Workspaces": [ { "Path": "c:\\SOME_PATH\\DMA\\xml\\ng", "Issues": [ { "File": "file://SOME_PATH/DMA/xml/ng/test.xml", "Queries": [ { "Text": "\r\n(@P1 int)SELECT * from ****\r\n", "LineNum": 2, "ColNum": 10, "ConfidenceLevel": 2 }, { "Text": "\r\n(@P1 int)SELECT * from ***\r\n", "LineNum": 5, "ColNum": 10, "ConfidenceLevel": 2 } ] } ] } ] }
DMAへの入力用のjsonとして良さそうです。しかし、こちらのファイルをDMAに入力したところ、以下のエラーが出てしまいました。
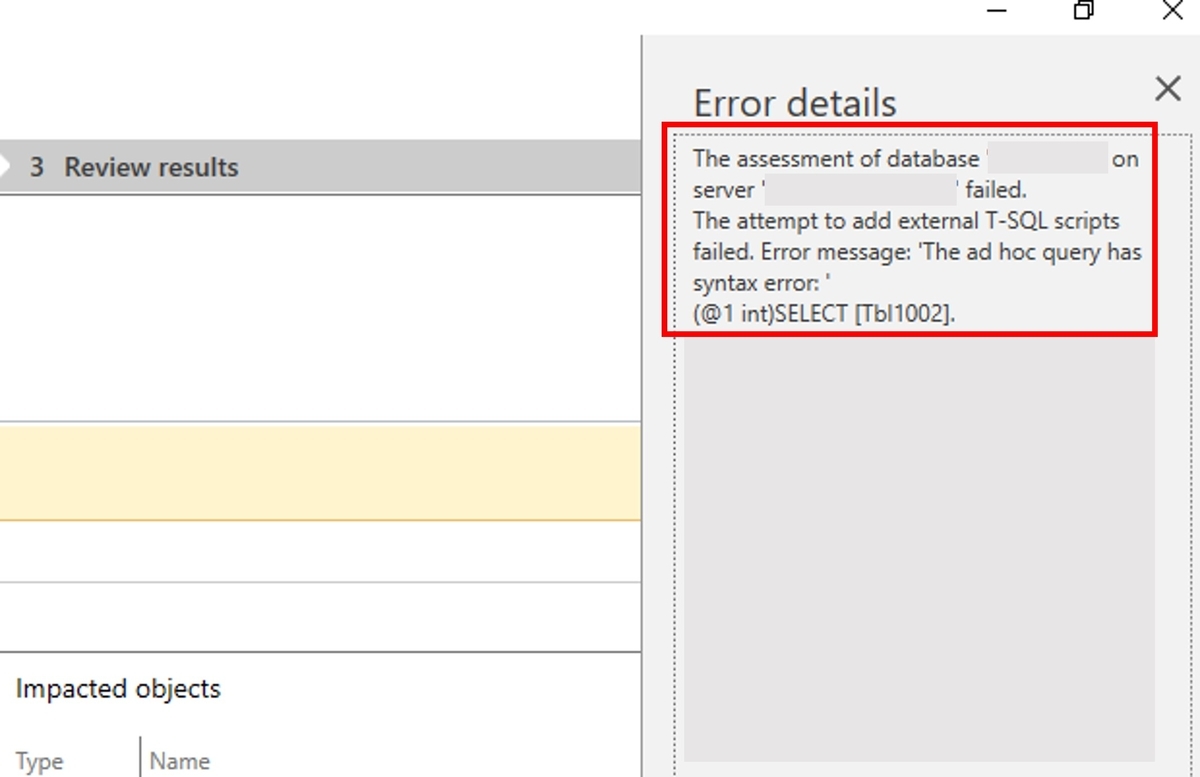
構文エラーが出ています。DMVで取得したクエリテキストは、そのままだとSQL Serverの構文解釈時にエラーとなってしまうことが分かりました。例えば、(@P1 int)SELECT...はdeclare @p1 int;select...に書き換える必要があります。そのため、「sys.dm_exec_query_stats」をもとに取得したクエリテキストを、構文解析が可能になるように変換するスクリプトを弊社エンジニア(@_itito_)が実装してくれました。こちらで公開されております。動作確認できている入力ファイルの形式は文字コードがUTF-16LE、改行コードがLFの組み合わせとなっております。このスクリプトに「sys.dm_exec_query_stats」をもとに取得したクエリテキストを入力すると、以下のようなxmlファイルが生成されます。
<xml> <![CDATA[ declare @1 int;SELECT * FROM table_1 WHERE table_1.col_1 = @1 ]]> <![CDATA[ declare @P1 int;declare @P2 int;declare @P3 nvarchar(10);declare @P4 datetime; insert into table_2 (col_1,col_2,col_3,col_4) values (@P1,@P2,@P3,@P4) ]]> </xml>
このxmlを「Data Access Migration Toolkit」に入力することで、DMAで解析可能なjsonファイルを生成できました。
3. 生成されたjsonファイルをDMAに入力して互換性を検証
あとはDMAに生成したjsonファイルを入力して、互換性を検証すればOKです。「sys.dm_exec_query_stas」は実行されたクエリしかキャッシュしません。そのためアプリケーション側に記述があっても、データ収集期間に一度も実行されないクエリはjsonファイルに記載されません。そのためアプリケーション側に記述された全てのクエリの互換性レベルを確認できるわけではありません。ですが、実質未使用のクエリの互換性をチェックする必要はないと思います。そのため今回の方法は互換性を検証できるクエリ数を増やせるという点で有用と考えております。
あらためて今回紹介した手順をまとめると、以下の通りです。
- 一定期間「sys.dm_exec_query_stas」を使用して実行されたクエリテキストを収集
- 自作ツールを使用して「Data Access Migration Toolkit」で解析可能なxmlファイルを生成
- xmlファイルをVisual Studio Codeの拡張機能「Data Access Migration Toolkit」を使用してjson形式に変換
- jsonファイルをDMAに入力してクエリ互換性を検証
まとめ
本記事では、DMAを用いてアプリケーション側に記述されているクエリの互換性を検証する方法について紹介しました。移行前の検証に役立てていただけたら幸いです。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。