



はじめに
こんにちは、データシステム部MLOpsブロックの薄田(@udus122)です。
この記事ではFour Keysなどの指標を活用して、定量的な根拠に基づきチームの開発生産性を改善する考え方とふりかえり手法を紹介します。
Four Keysとはデプロイ頻度、変更のリードタイム、変更障害率、平均修復時間の4つの指標からなるソフトウェアデリバリーや開発生産性の指標です。
Four Keysなど開発生産性の指標を計測し、定期的にふりかえっているけれど、なかなか具体的な改善につながらない。
そんな悩みはないでしょうか?
実際に私たちのチームで抱えていた開発生産性の改善に関する課題と解決策を紹介します。皆さんのチームで開発生産性を改善する際のご参考になれば幸いです。
目次
開発生産性の改善に取り組んだ背景
MLOpsブロックがFour Keysを活用した開発生産性の改善に取り組んだ背景ときっかけを紹介します。
MLOpsブロックはZOZOTOWNやWEARの推薦、検索といった機械学習系のマイクロサービスを開発・運用するチームです。MLプロダクトを世に出すために必要となるモデル作成以外の全てのエンジニアリングを担当しています。API開発からインフラの設計構築、CI/CDパイプラインの構築、負荷試験、アラート対応、実験基盤の整備など業務は多岐に渡ります。
MLOpsブロックでは週に1度業務のふりかえりを実施しています。ふりかえりはKPTの形式で実施していました。KPTは「Keep、Problem、Try」の3要素を検討するふりかえりのフレームワークです。
ZOZOでは開発生産性の指標を可視化するため全社的にFindy Team+を導入しています。Findy Team+はGitHub Pull Request(以下プルリク)のステータスの変化などから開発生産性の指標を集計・可視化してくれるツールです。MLOpsブロックでもFindy Team+を使ってFour Keysなど開発生産性の指標を確認できる状態でした。
従来はふりかえりを始める前にDevOps分析(Four Keys)を確認する流れでFindy Team+を活用していました。
しかし指標を観測してもこれを活用した具体的な開発生産性の改善は滞っていました。
そんな中、2024年度の全社目標で生産性の向上が掲げられました。これをきっかけに改めて開発生産性の指標を活用して、チームの開発生産性を改善する取り組みを始めました。
チームの改善に取り組む上での課題
MLOpsブロックの開発生産性の改善における課題は、観測した指標を具体的なチームの改善行動に活かせていないことでした。
特に開発生産性の指標が変化する要因を把握できていないことが大きな問題でした。
これまでの経験から、開発生産性の指標を活用したチーム改善のプロセスは次の流れで進めるのが理想だと考えています。
- 開発生産性の指標の変化を観測する
- 指標の変化要因となった事実を特定する
- 事実から横展開可能な成功や改善すべき失敗を発見する
- 成功や失敗から具体的な改善点を決め、実行する
- 改善行動の結果、指標が変化したかどうかを確認する(ステップ1に戻る)
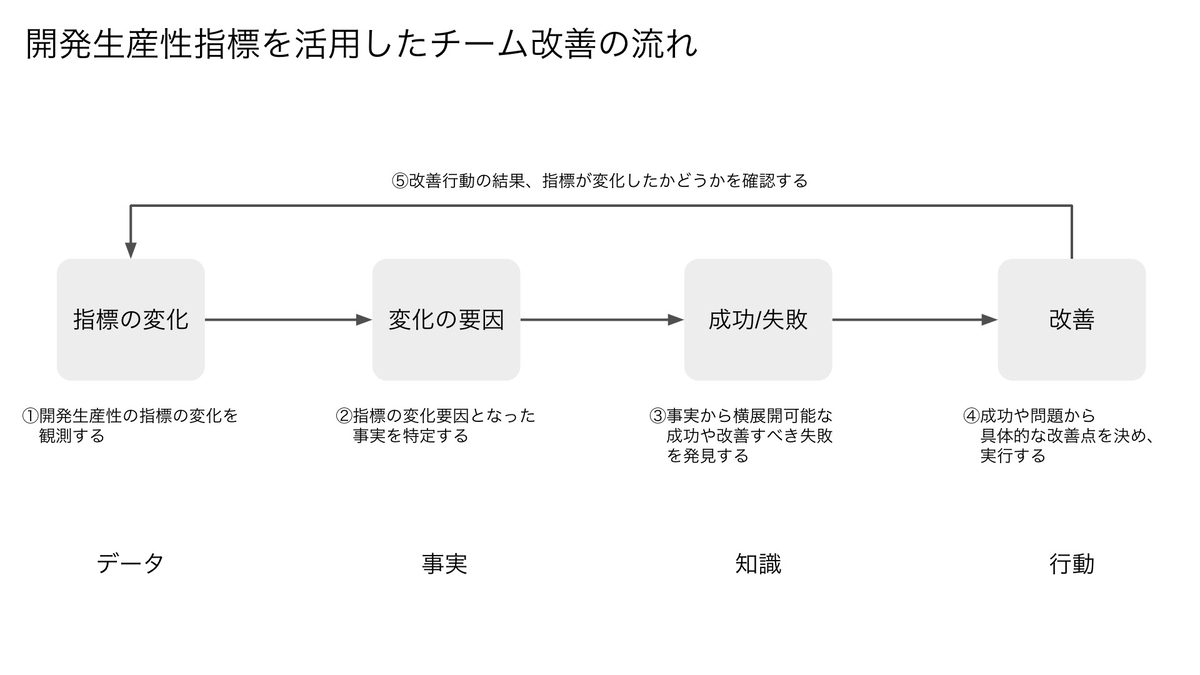
開発生産性の指標を活用してチームを改善するには、ステップ2で変化要因となった事実を把握することが重要です。ステップ3での成功や失敗原因の分析はステップ2で変化の要因となった事実を起点に考えます。以前のMLOpsブロックで行っていたように指標を見て良かった点や悪かった点を考えるだけでは不十分です。
実際MLOpsブロックでもこの「指標が変化した要因の把握」がうまくいっていませんでした。原因は大きく3つありました。
- Four Keysの考え方に対する理解不足
- 指標に含まれるノイズ
- ふりかえりプロセスでの「要因の把握」の漏れ
次にそれぞれの課題について詳細を説明します。
Four Keysの考え方に対する理解不足
Four Keysの可視化はFindy Team+を利用することで実現できていました。しかしその背後にある考え方に対する理解度は浅く、指標の背後にある原因を考えたり、指標の変化から改善策を検討したりする材料が少ない状態でした。
Four Keysは単独でみるとソフトウェアデリバリーのパフォーマンスを示す指標です。チームの生産性を示す指標ではありません。Four Keysはチームのデリバリーパフォーマンスを結果としてのみ表します。そのため変化の要因やその他の影響については、Four Keysの指標のみでは判断できません。
変化の要因やその他の影響を無視すると、例えば目先のデリバリーを優先して長期的なコードの保守性を疎かにしてしまうリスクがあります。デプロイ頻度・変更リードタイムの改善を重視し過ぎて他のことが疎かになってしまうと本末転倒です。
Four Keysを提唱したDORAの研究では、背後にあるチームのCapability1とセットで分析し、Four Keysが生産性などの組織全体のOutcome2と関連があることを示しています。つまり、Four Keysを開発生産性の指標として扱う場合は単独で見るのではなく、背後に存在するCapabilityとセットで見る必要があります。
以下が最新版(2024年9月23日時点)のDORA Core Modelです(DORA | Researchより引用)。
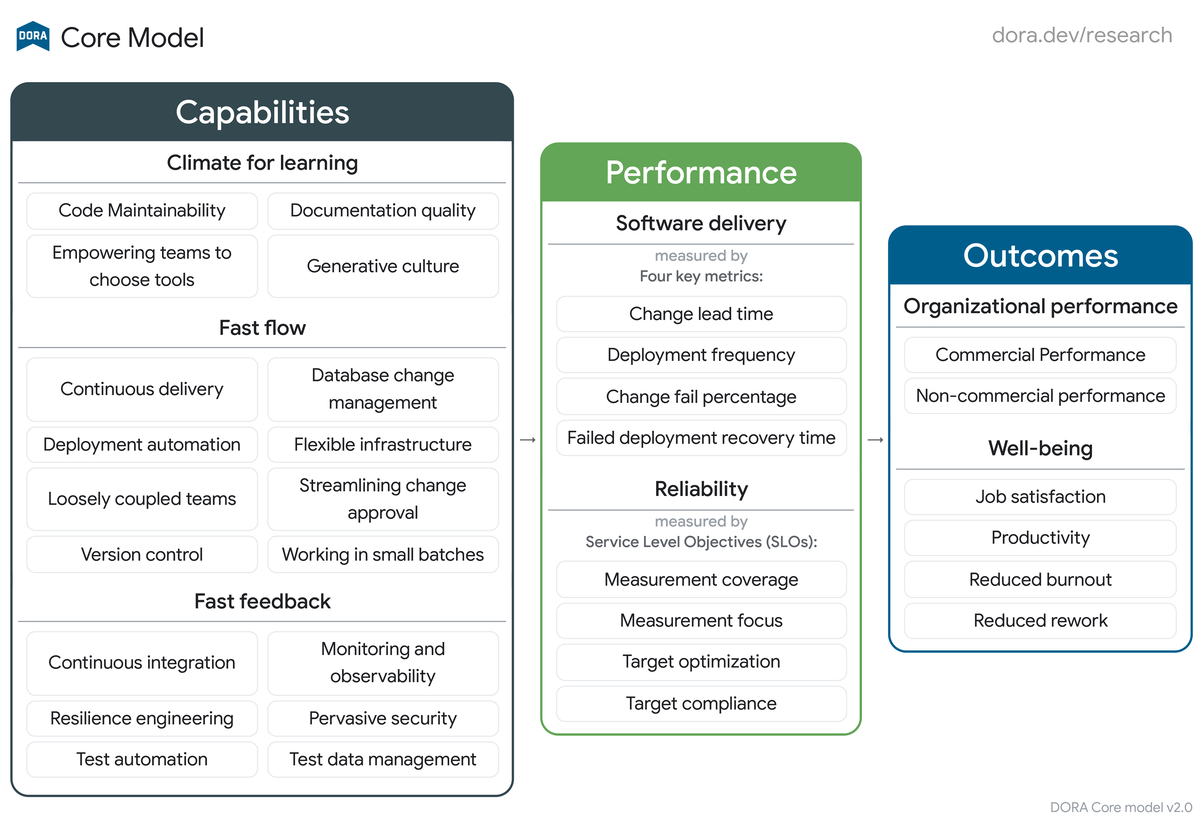
こちらの図からチームのCapability、Performance、Outcomeの関係が読み取れます。チームのCapabilityがFour Keysなどのパフォーマンス指標を説明し、パフォーマンス指標から組織のOutcomeを予測できることを示しています。大元の出発点としてチームのCapabilityがあり、Four Keysを変化させる要因であることが読み取れます。
このことから改善すべき対象はチームのCapabilityであり、Four KeysはCapabilityの改善結果を確認するための指標であるとわかります。
以前はこの考え方が念頭になかったため、指標を見ても何を改善すればよいか分からず具体的な改善施策につなげることができていませんでした。
指標に含まれるノイズ
指標に含まれるノイズが原因で、指標の変化からチームのCapabilityの改善につながる事実を抽出することが困難という問題もありました。
ここで言うノイズ3とは、チームのCapability以外に由来する指標の変化です。指標の集計定義や集計の仕組みの不完全さに由来するリードタイムの外れ値や例外的な変更障害などが該当します。
指標の変化からチームのCapabilityを改善するには、指標の変化がチームのCapabilityに紐づいていることが大切です。しかしこのようなノイズが指標に含まれることでチームのCapabilityに関わる事実が見えにくくなっていました。
MLOpsブロックの指標におけるノイズの原因は次の3つでした。
- ステージング環境を含めた変更障害の集計定義
- 変更障害の切り戻し以外のRevert活用
- 幅広い業務内容による指標の上振れ
順番に説明します。
ステージング環境を含めた変更障害の集計定義
変更障害率の一般的な定義は「デプロイが原因で本番環境で障害が発生する割合(%)」です。cf. エリート DevOps チームであることを Four Keys プロジェクトで確認する
Findy Team+の定義では不具合を含む変更が本番環境にデプロイされた時、変更障害としてカウントします。逆に言えば不具合を含む変更であっても本番環境へデプロイされていなければ変更障害としてカウントしません。
一方で私たちのチームでは本番環境の前段のステージング環境への反映においても、不具合が発生した場合は変更障害としてカウントしています。我々の変更障害の定義は「本番/ステージング環境において変更をデプロイにより意図しない不具合が発生すること」です。
なぜ通常よりも厳しい定義を採用しているのか説明します。
MLOpsブロックでは次のブランチ戦略を採用しています。
- メインブランチ(
main)の内容がステージング環境に反映される - リリースブランチ(
release)の内容が本番環境に反映される - 開発作業は、メインブランチからフィーチャーブランチ(ブランチ名は任意)を作成する
- メインブランチに変更が加わる度に、その内容をリリースブランチに反映するリリースプルリクが自動で作成・更新される
- リリースする際は、メインブランチから発行されるリリースプルリクをマージする
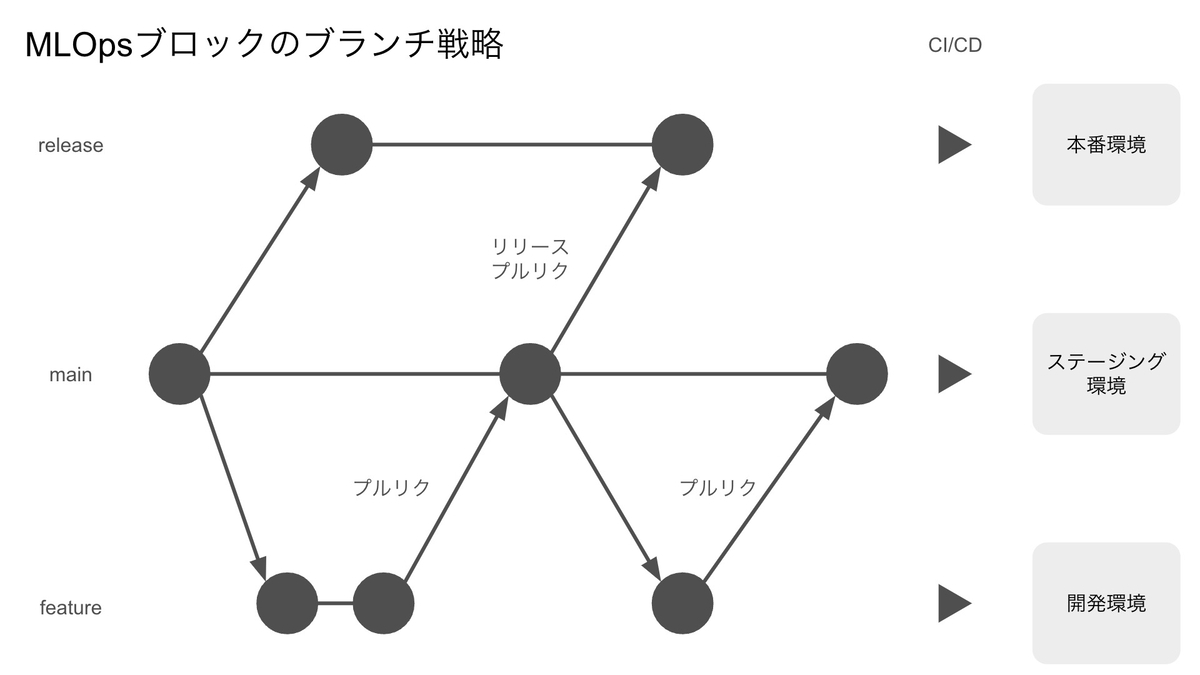
本番環境に対する変更は常にリリースプルリクを経由して反映されます。リリースプルリクのブランチ名も常に固定です。しかしFindy Team+はブランチ名から変更障害を判定する仕組みになっているため、本番環境に対する変更が通常のリリースなのか変更障害を修復するものなのか区別できません。そのため本番環境における変更障害を集計対象に含めることができませんでした。
またリリースプルリクはメインブランチに変更が反映されると自動で作成されます。リリースプルリクにはこれからステージング環境で検証する変更も含まれます。そのためタイミングによっては検証中の変更を他の人が誤って本番リリースしてしまう危険もあります。このように、ブランチの運用ルール上ステージング環境に反映されている内容は常に本番環境にも反映される可能性がありました。そのためチームの理想はステージング環境にも変更障害がないことでした。
MLOpsブロックの業務にはCI/CD整備やインフラ構築などが含まれます。問題があると本番環境への適用前にリリースが失敗する、または問題があってもユーザー影響のある障害にはつながらない作業も少なくありません。ステージング環境での変更障害も集計に含めることで、これらの作業で発生した問題も指標に反映されてふりかえりが可能になるメリットもありました。
まとめると次の3つの理由から集計の定義にステージング環境を含める判断をしました。
- Findy Team+の集計の仕組みとリリースプルリクの運用ルールの兼ね合いに問題があったため
- ステージング環境の変更はそのまま本番環境への影響につながるリスクがあるため
- ステージング環境における問題をふりかえりの俎上にのせるため
一方でこの定義変更により、本番環境に影響がなかった些細なミスも集計対象に含まれ、ノイズとなっていました。ステージング環境で発見できた小さな失敗(タイプミスなど)まで含めてふりかえりで会話し対策を検討しているとキリがありません。ふりかえりの時間は有限です。
変更障害の修正以外のrevert活用
Findy Team+では変更障害の発生を判定する際に直接的な判定は難しいため、変更障害の修正プルリクの有無で判定します。MLOpsブロックでは名前が"hotfix"または"revert"から始まるブランチを変更障害の修正プルリクのブランチ名としています。これに一致するブランチがメインブランチにマージされたことを持って変更障害の発生を集計していました。
2種類のブランチ名は、次の2つの方法で作られた修正プルリクを変更障害として集計するために使い分けています。
- "hotfix": 手動で発行された変更障害の修正プルリクを判定する
- "revert": GitHubのPull Request revert機能を利用した変更障害の修正プルリクを判定する
Findy Team+での集計でノイズとなったのは"revert"のプルリクでした。
GitHubのPull Request revert機能で作られる"revert"プルリクの変更内容は大きく分けて2種類ありました。
- 変更障害の修復
- 一時的な設定変更などの切り戻し
前者は変更障害ですが、後者は変更障害として含めたくありません。一時的な設定変更などを切り戻す際にrevert機能を使わないことでこの問題は回避可能です。しかし、GitHubのPull Request revert機能は便利です。GitHubのUIからワンクリックで修正できる変更を手作業で行うのは無駄が多くミスのリスクも高まります。そのため他の方法で課題を解決する必要がありました。
幅広い業務内容による指標の上振れ
MLOpsブロックの業務は多岐に渡るためプルリクの種類も様々です。中には簡単な設定変更や権限付与などリードタイムが極端に短く済むプルリクも多くあります。
それらはデプロイ頻度やリードタイムの指標を底上げし、結果として全体の開発生産性スコアも業界のベンチマークと比較して上振れていました。
見た目上のスコアが良くても、チームに課題がないのかというとそうではありません。これまで指標のスコアが見かけ上高くなっていたことにより、課題のあるプルリクを見逃してしまうケースがありました。
ふりかえりプロセスから「要因の把握」が漏れていた
従来のふりかえりプロセスには、指標の変化のみを見て要因となった事実を確認するステップがないという問題がありました。
従来のふりかえりの流れでは最初にFindy Team+のDevOps分析(Four Keys)を確認し、すぐにKeepとProblemの検討を始めていました。
この流れでは、指標を見てもなぜそのように変化したのか曖昧なまま改善点を出すことになります。結果として、チームの改善までつなげづらい状況となっていました。
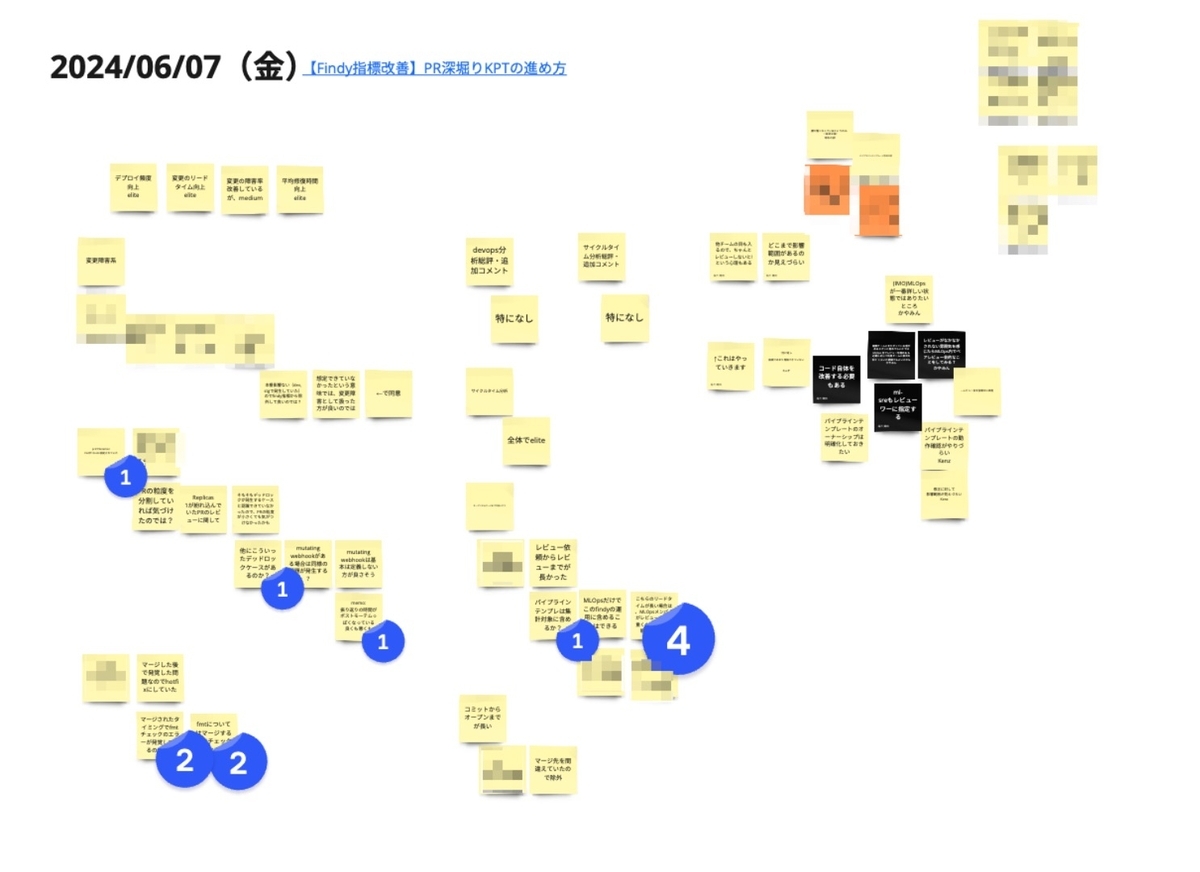
下の図は従来のプロセスで進めたある日のふりかえりのKPTです。各人のKPTがバラバラに配置されており、具体的な問題ではなく個人のアイデアがベースとなってふりかえりが進んでいることが見て取れます。
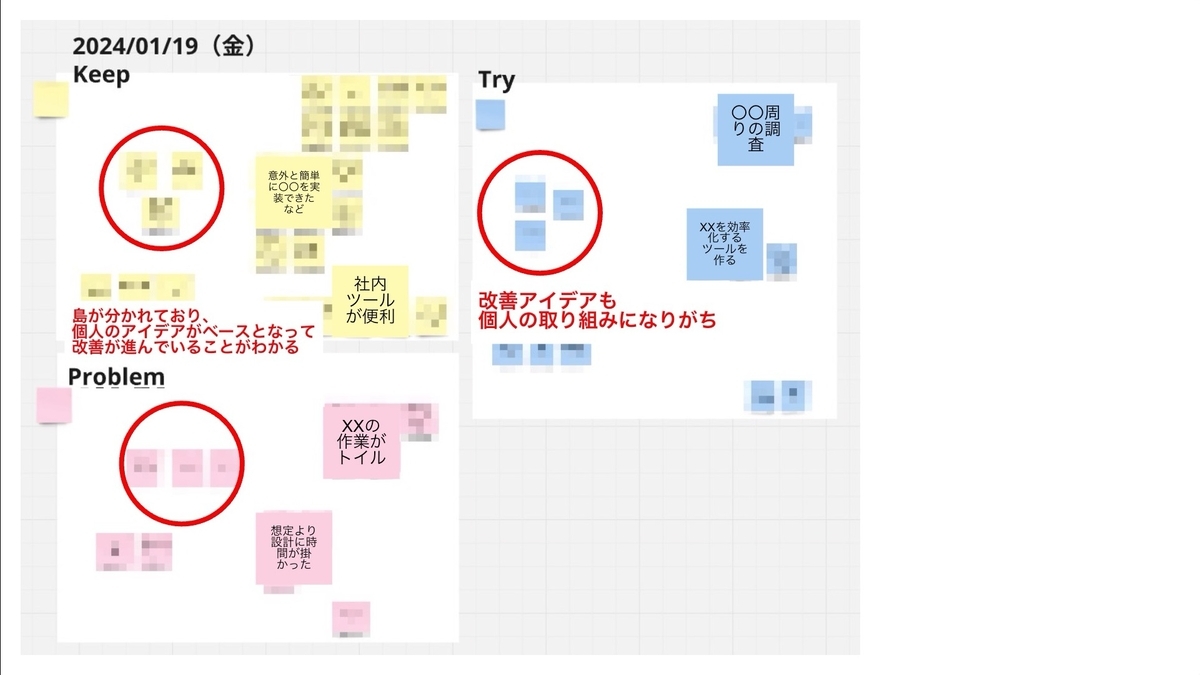
このように指標の変化の要因が曖昧になることで起こる問題は次の通りです。
- ふりかえりの主語がチームではなく個人に寄ってしまい、チームの改善に繋がるアイデアが出づらい
- 他のメンバーが課題の具体的な内容や大きさを把握しづらく、改善の優先度を決めにくい
- 問題の重要性に関わらず直近起きた問題の方が議論に上がりやすい
チームの改善サイクルを回すために行った工夫
本章ではチームの開発生産性の改善に取り組む上で存在していた課題に対して、どのような解決策を取ったのか紹介します。
MLOpsブロックで開発生産性の指標を活用したチームの改善がうまくいかなかったのは、次の3つの原因から指標が変化した要因を把握できていなかったためでした。
- Four Keysの考え方に対する理解不足
- 指標に含まれるノイズ
- ふりかえりプロセスから「要因の把握」が漏れていた
これらの課題を解決するために、次の3つの対策を実施しました。
- Four Keysの考え方についてチーム内で認識を合わせた
- 指標の定義と集計対象を明確化し外れ値を除外した
- 「プルリク深掘り」という手法でふりかえりを実施し、改善に繋がりやすい工夫をした
それぞれ具体的にどのようなことを行ったのか説明します。
Four Keysの考え方についてチーム内で認識を合わせた
指標を見るだけで終わってしまっていた要因の1つは、チームのCapabilityとセットでFour Keys指標を活用できていなかったことでした。Four KeysをチームのCapabilityに絡めて評価する考え方がチーム内に浸透していなかったため、指標を見てもどの部分を改善すべきか手がかりがなく具体的な改善施策につなげられていませんでした。
対策としてFour Keysの指標と背後にあるチームのCapabilityの関係についてチーム内で認識合わせを行いました。またFour Keysのふりかえりの際に単に指標のみを評価するのではなく、チームのCapabilityの課題について合わせて議論しました。
この考えのきっかけやチームで会話をする材料として、以下の資料がとても参考になりました。
Four Keysの考え方を共有したことで、次の共通認識を得ることができました。
- 全体の指標の数値が基準より高くても問題が隠れている場合がある
- 指標のスコアを変化とその要因と合わせて把握し、それらを起点にチームのCapabilityの問題を検討することが大切
指標の定義と集計対象を明確化し外れ値を除外した
続いて、指標に含まれるノイズの問題をどのように解決したか説明します。
変更障害の数値がばらつく原因は3つありました。
- ステージング環境を含めた変更障害の集計定義
- 変更障害の切り戻し以外のrevert活用
- 幅広い業務内容により、指標が上振れする
Four Keys指標の考え方を共有し前回からの変化に着目すること、後述する「プルリク深掘り」の手法で変化要因を深掘ることで指標の上振れにより課題を見逃す問題は解決できました。
残る2つの課題をどのように解決したか紹介します。
ブランチ名でふりかえるべき失敗と些細なミスを区別した
変更障害の定義にステージング環境を含めることによる弊害は、本番環境に影響がなかった些細なミスまで集計対象になってしまい、ふりかえりの時間を無駄にしてしまうことでした。
この問題を解決するために、ブランチの命名ルールを分けることにしました。Findy Team+はブランチ名を元に集計対象をフィルタリングできます。MLOpsブロックではふりかえる必要がない些細なミスの修正には"fix"で始まるブランチ名を、変更障害の修正としてふりかえるべきプルリクには"hotfix"で始まるブランチ名を使用しました。
些細なミスの基準については全てのプルリクを分類できるほど明確化できておらず迷うケースは多少存在します。迷った場合に"fix"を付与すると問題を見逃すリスクがあります。そのため迷う場合や繰り返し同じ問題が発生する場合は積極的に"hotfix"のブランチ名を付与し議論の俎上に載せることを推奨しています。
ふりかえりの準備で外れ値を除外する運用を行った
前述の通り、GitHubのPull Request revert機能を利用することで本来は変更障害ではない変更が変更障害として集計され、ふりかえりのノイズとなってしまう問題がありました。
設定の切り戻しなど変更障害の修正ではない例外的なrevertプルリクには特定のラベルを付与して集計対象から除外することにしました。これにはFindy Team+のラベルフィルター機能を使っています。
一方で上記のようなブランチやラベルの運用は人に依存するためこれだけでは課題が残ります。
ブランチやラベルの運用は明確な基準を設けることが難しく個々人の判断では多少のブレが出ます。ブレを最小限に抑えるためふりかえりの前日にふりかえりのファシリテーションの担当者が集計されたプルリクを簡単に確認し、除外すべきプルリクがあるかどうかをチェックしています。
手間にはなりますが5分程度実施することで個々人の判断によるブレを防止し、ふりかえりの質を向上させています。
「プルリク深掘り」という手法でふりかえりを実施し、改善に繋がりやすい工夫をした
続いてふりかえりの具体的な進め方についてご説明します。
従来のふりかえりの問題点は、指標の変化を見てその要因となった事実を確認するステップがないことでした。これにより指標の観測から具体的なチームの改善に繋げづらくなっていました。
この課題を改善するために、指標の観測からチームの改善に繋げやすい「プルリク深掘り」という手法を考えました。
具体的には指標の変化を見てその原因となったプルリクについて深掘りをするふりかえり手法です。
プルリク深掘りの進め方について説明します。プルリク深掘りは、次のような役割分担とタイムテーブルで進めます。ツールはMiroを使っており、Miroの画面を共有しながら進めています。私たちのチームでは隔週でプルリク深掘りを実施しています。
役割分担
- ファシリテーター: 1名
- 全体の進行を担当する
- 書記: 1名
- ふりかえりの中で出た気づき・アイデアなどをMiro上の付箋にメモとして残す
- アイデア出し: 残りの全員
- 指標の変化やプルリクを見て、課題や改善点のアイデア出しをする
タイムテーブル
| 時間 | タイトル | 概要 |
|---|---|---|
| 5分 | 前回のふりかえり | 前回出たネクストアクションを見て、改善できているか確認する |
| 15分 | DevOps分析の確認と変更障害プルリクの深掘り | ・指標の変化を確認する ・障害対応のプルリクを1つ1つ確認し、気付きをMiroにメモする ・プルリクの担当者にプルリクの概要や背景を説明してもらう ・口頭で出たものは書記役がメモし、残りのメンバーも気づいたことは積極的にメモする |
| 15分 | サイクルタイム分析の確認と個別のプルリクの深掘り | ・サイクルタイムが長いプルリクを全員で見ながら、気付きや改善点をメモしていく ・プルリクの担当者にプルリクの概要や背景を説明してもらう ・口頭で出たものは書記役がメモし、残りのメンバーも気づいたことは積極的にメモする |
| 5分 | 優先順位の投票 | Miroにメモしたアイデアに対して投票を行い、改善アクションを検討する優先順位をつける |
| 10分 | アクションを明確化する | 投票数の多いものから順に具体的なネクストアクションに落とし込み、担当者を決める |
進行の流れ
前回のふりかえり
プルリク深掘りは前回のネクストアクションのふりかえりから始まります。前回のネクストアクションが適切に実行されているか確認し、実行漏れがあればリマインドします。
Four Keys指標の確認と変更障害プルリクの深掘り
次にFindy Team+の「DevOps分析」を参照し、チームのFour Keys指標を確認します。
1つずつ指標を確認して改善、悪化といった変化を確認します。変更障害率のタブを確認し変更障害を修正したプルリクを一覧し、1つずつ深掘ります。
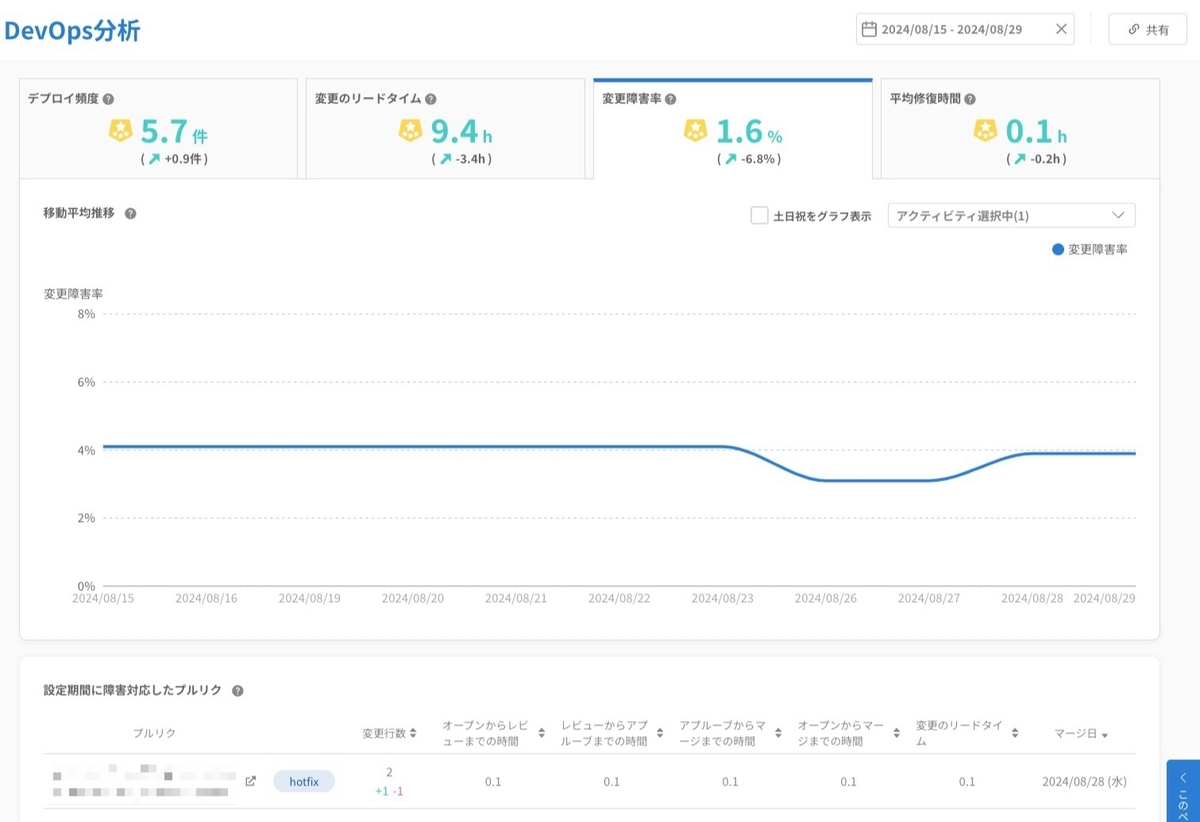
次の流れでプルリクを深掘ります。
- プルリクを開き、プルリクの作成者に変更の概要を説明してもらう
- 他のメンバーは気になる点があれば随時質問し、課題点や改善点があれば発言するかMiroに書く
- 書記はメンバーの発言を都度メモする
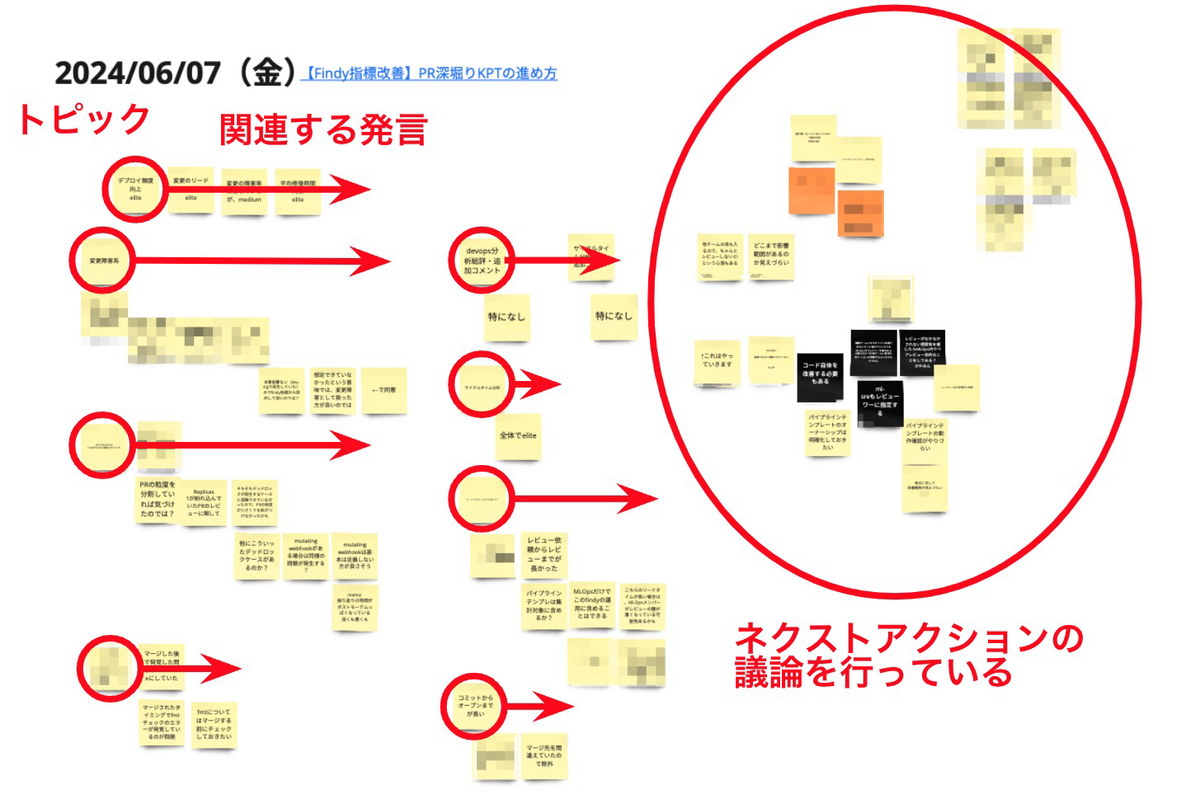
メモを整理する際のコツは、トピックごとに樹形図形式でポイントを羅列することです。改善の優先順位を決める際に、分かりやすくなります。
サイクルタイム分析の確認と個別のプルリクの深掘り
サイクルタイム分析はプルリクのリードタイムを細分化する機能です。
サイクルタイム分析についてもDevOps分析と同様にまず全体の指標を見ます。次にリードタイムが長いなど他と比較して目立ったプルリクを個別で深掘ります。
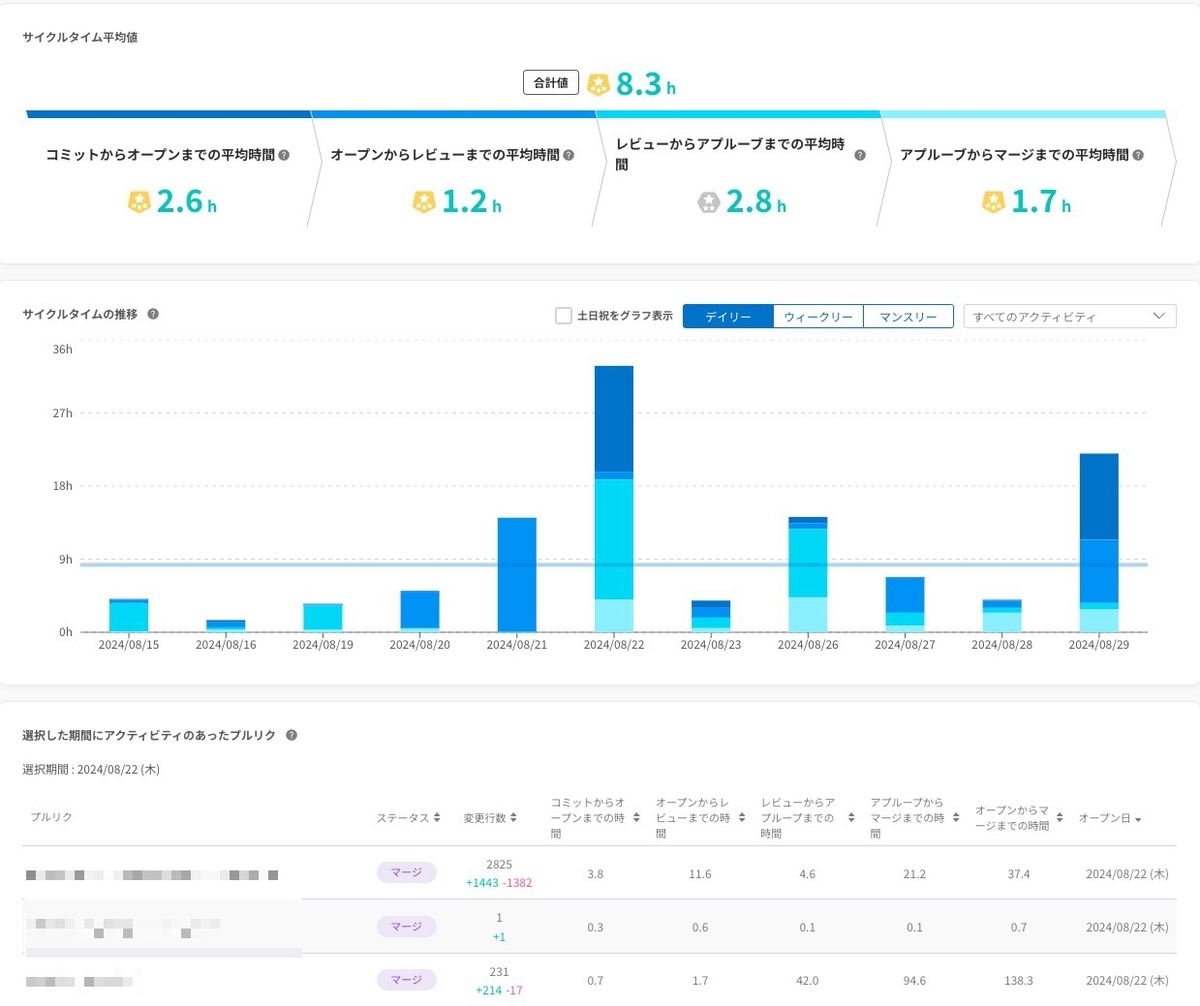
以上でプルリクの深掘りは終わりです。
改善アクションの優先順位の投票
次に深掘り中に出てきたアイデアについて、Miroの投票機能を用いてチーム全員で投票します。
トピックや関連する発言などが書かれた全ての付箋を対象にして、1人3票でネクストアクションとしての優先度が高いと思う付箋に投票します。
得票数が高い順に詳細な議論をして、後述するネクストアクションの明確化の材料にします。
投票が終わった後で付箋をまとめて得票数トピックごとの合計で優先順位を決めます。
ネクストアクションの明確化
最後に、得票数の多い付箋から順に詳細について議論します。
この議論は課題を改善するために実施するネクストアクションを明確化することを目的としています。この時の議論のやり方は課題によって様々です。
大事なポイントは、時間内にネクストアクションの明確化と担当者の決定までをやり切ることです。ネクストアクションは、「あえて何もしない」や「改めて時間を取って話す」といったものでも問題ありません。
課題が明確な場合はすぐにネクストアクションのブレストへと移りますし、まだ課題が抽象的な場合は、改めて何が問題なのか明確にするところから始めるケースもあります。
後からふりかえりやすいようにネクストアクションの付箋の色を変えて完了です。
ふりかえりから生まれた改善施策と効果
このふりかえり手法の導入によって、滞り気味だった開発生産性の改善サイクルが再び回り始めました。
ふりかえりから生まれた開発生産性の改善施策の例は次の通りです。
- 他チームが関わるプルリクのレビューやマージのルールの明確化
- 共通のプルリクテンプレートを用意
- ブランチ名からのカテゴリラベルを自動付与する仕組みを作成
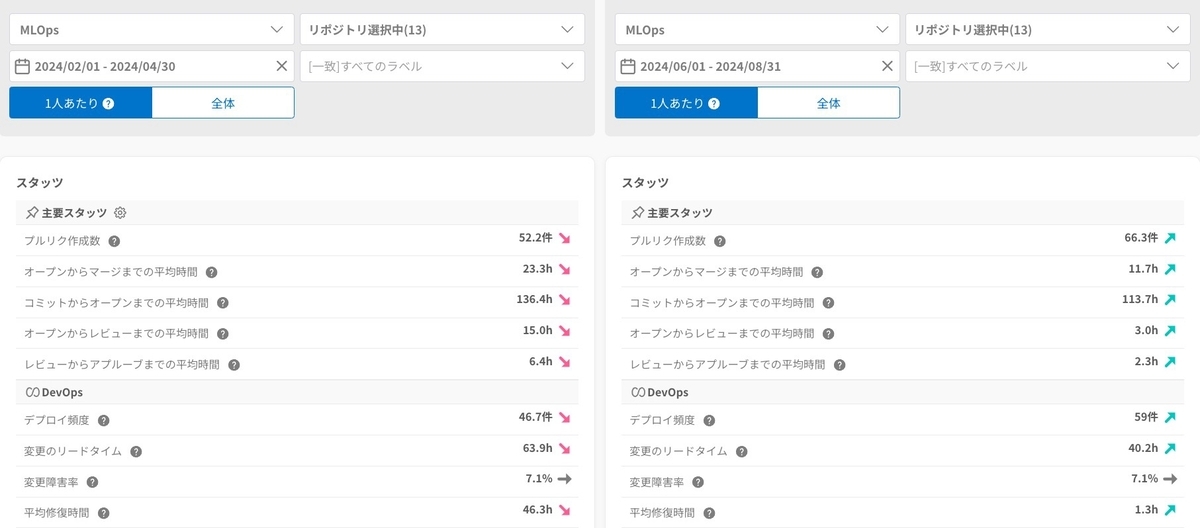
これらの改善成果として、リードタイムやアウトプット数に関する主要な指標を改善できました。オープンからマージまでの時間を約半分に短縮しながら、プルリク作成数を増やせていることが分かります。
一方で変更障害率は維持できています。これはふりかえりの内容が指標の改善ではなく、Capabilityの改善にチームの意識が向いた結果です。
実際ふりかえりから生まれた改善施策はプルリクに関わるものだけではありません。トイルの削減やコミュニケーション改善、ヒヤリハット予防など幅広い施策につながっています。実際の例は次の通りです。
- 社内問合せの対応ルールを明確化
- 業務を効率化するツールの作成
- バッチ処理の失敗アラートにチームメンションを付与
- 他チームとのコミュニケーションの場作り
今後は現状維持だった変更障害率を重点的に改善予定です。またもう1つのパフォーマンス指標である信頼性(SLOs)もふりかえりに組み込むことで多角的な視点から改善できるプロセスも検討しています。
まとめ
本記事ではチームの開発生産性を高めるために行ったふりかえり手法とその考え方について紹介しました。
ポイントはただ指標の変化を見るのではなく、その変化要因となった事実を把握しチームのCapabilityと紐づけて改善を考えることです。そのコツはノイズとなる外れ値を取り除き、ふりかえりの中でプルリクを深堀ることでした。
Four Keys指標を使ったチームの開発生産性を向上させようと考えている方は、是非参考にしてみてください。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。