



こんにちは、技術戦略部のikkouです。2025年6月17、18日の2日間にわたり「KubeCon + CloudNativeCon Japan 2025」がヒルトン東京お台場で開催されました。ZOZOは今回シルバースポンサーとして協賛し、スポンサーブースを出展しました。
本記事では、前半はZOZOのエンジニアが気になったセッションを紹介します。そして後半はZOZOの協賛ブースの様子と各社のブースコーデのまとめを写真多めでお伝えします。
- KubeCon + CloudNativeConとは
- ZOZOエンジニアの気になったセッションの紹介
- Kubernetes SIG Node Intro and Deep Dive
- Platform Engineering Day 2: Why Service Iterations Are the Crux of Developer Platforms
- Japan Community Day Doc Sprint参加レポート
- Exploring Tenant-centric Strategies To Simplify Multi-cluster and Multi-cloud Complexities
- Cloud Native Scalability for Internal Developer Platforms
- ZOZOブースの紹介
- 協賛企業ブースのコーデまとめ
- おわりに
KubeCon + CloudNativeConとは
KubeCon + CloudNativeConは、ZOZOでも利用しているKubernetesをはじめとしたCloud Native Computing Foundation (CNCF)に関する技術を中心とした大規模カンファレンスです。これまではUSやEUなどで開催されていて、例年ZOZOのエンジニアも現地参加してきました。
- KubeCon + CloudNativeCon Europe 2024 参加レポート - ZOZO TECH BLOG
- KubeCon + CloudNativeCon Europe 2023 参加レポート - ZOZO TECH BLOG
- KubeCon + CloudNativeCon North America 2022参加レポート〜3年ぶりのアメリカ現地開催の様子とセッション紹介〜 - ZOZO TECH BLOG
今回は「KubeCon + CloudNativeCon Japan」として初めて日本で開催されました。初回から想定を上回る1,500人の参加者が集まり、チケットも売り切れになったそうです。
ZOZOエンジニアの気になったセッションの紹介
今回、ZOZOからは10名を超えるエンジニアが参加しました。代表して5名から、それぞれが気になったセッションを紹介します。
Kubernetes SIG Node Intro and Deep Dive
こんにちは、MLOpsブロックの木村です。「Kubernetes SIG Node Intro and Deep Dive」セッション(登壇者:Narang Dixita Sohanlal 氏[Google]、Paco Xu 氏[DaoCloud]、椎名宏典 氏[Independent])をご紹介します。
https://kccncjpn2025.sched.com/event/1x6zP/kubernetes-sig-node-intro-and-deep-dive-narang-dixita-sohanlal-google-paco-xu-daocloud-hironori-shiina-independentkccncjpn2025.sched.com
このセッションでは、Kubernetesのノード周辺に関する最新機能についての発表が行われました。特に注目されていたのは、GPUのような特殊なリソースをPodやコンテナ間で柔軟にリクエスト・共有できるようにするための仕組みであるDynamic Resource Allocation (DRA)と、Podの再起動を伴わずにリソースの割り当てを変更可能とする機能In-Place Pod Resizeの2つです。どちらも、リソース使用量が変動しやすいワークロードを効率的に運用するうえで非常に有用なアップデート情報でした。
DRAは、これまでPod作成時に静的に確保されていたGPUなどの特殊リソースを、Podがノードにスケジュールされるタイミングで、ノード上の利用可能なデバイス状況に応じて柔軟かつ動的に割り当てるための仕組みです。これにより限られたリソースの利用効率を高めることができます。さらに、1つのGPUを複数のPodで共有したり、Pod側からデバイスの構成パラメータを細かく指定したりできます。この機能は、Kubernetes v1.32でベータ版として導入されました。
さらに、Kubernetes v1.33では、以下のアルファ機能が追加されました。
- Partitionable Devices:物理GPUを分割して複数Podに割り当て、リソース効率を最大化
- Device Taints and Tolerations:特定のPodにのみ特定デバイスを使わせる制御
- Admin Access:DRAに管理者用のアクセス権限を導入
今後Kubernetes v1.34での正式サポート(GA)を目指して活発に開発が進められています。詳細については以下の公式ドキュメントをご参照ください。
次に紹介されていたIn-Place Pod Resizeは、既存のPodを削除せずにCPUやメモリのrequests / limitsを動的に変更できる機能です。これまでKubernetesではリソースを変更する際にはPodを再起動する必要がありましたが、この機能によって、Podを停止せずにリソース構成を変更できるようになります。
Kubernetes v1.27ではアルファ版として登場し、v1.33では以下の改善がありました。
--subresource=resizeによる明示的なリサイズAPIの提供- リサイズ反映までの時間が大幅に短縮され、即時対応が可能に
特に注目すべき点はダウンタイムの削減です。v1.31ではリソース変更の反映に60〜90秒ほどかかっていましたが、v1.33では即時で反映されるようになり、よりスムーズなリソース変更が可能になりました。
この2つの機能は、今後のKubernetesにおいて非常に重要な役割を果たすと考えられます。DRAによるGPUの細かな割り当て制御は、AI/MLの活用が進む中で高まるGPU需要に対し、限られたリソースをいかに効率よく活用するかという課題の解決に貢献します。また、In-Place Pod Resizeを活用することで、動的に変化するワークロードにも柔軟かつ迅速に対応することが可能になります。
特にDRAは、今回のKubeCon + CloudNativeCon Japan 2025でも複数のセッションで取り上げられており、コミュニティ内でも高い関心を集めているテーマであることが印象的でした。今後のバージョンアップを通じて、より高度で柔軟なリソース管理が実現されていくことに期待されます。SIG Nodeチームは、ノードやリソース管理の進化を牽引する存在であり、今後のアップデートにも引き続き注目していきたいです。
Platform Engineering Day 2: Why Service Iterations Are the Crux of Developer Platforms
計測プラットフォーム開発本部・システム部SREブロックの近藤です。「Platform Engineering Day 2: Why Service Iterations Are the Crux of Developer Platforms 」セッション(登壇者:Puja Abbassi氏[Giant Swarm])をご紹介します。私の所属する部署では、既存プロダクトの開発・運用に加え、計測技術を活用したPoCや新規プロダクトの立ち上げにも取り組んでいます。そのため、KubeConの中ではやや異色に感じたセッションでしたが、普段の業務に通じる内容が多く、非常に実践的な学びが得られました。
https://kccncjpn2025.sched.com/event/1x70r/platform-engineering-day-2-why-service-iterations-are-the-crux-of-developer-platforms-puja-abbassi-giant-swarmkccncjpn2025.sched.com
Internal Developer Platform(IDP)
本セッションでは、開発者体験(DX)を向上させるための基盤として「Developer Platform」が紹介されました。その中でも、社内での開発者向けに最適化された仕組みとして「Internal Developer Platform(IDP)」が取り上げられています。
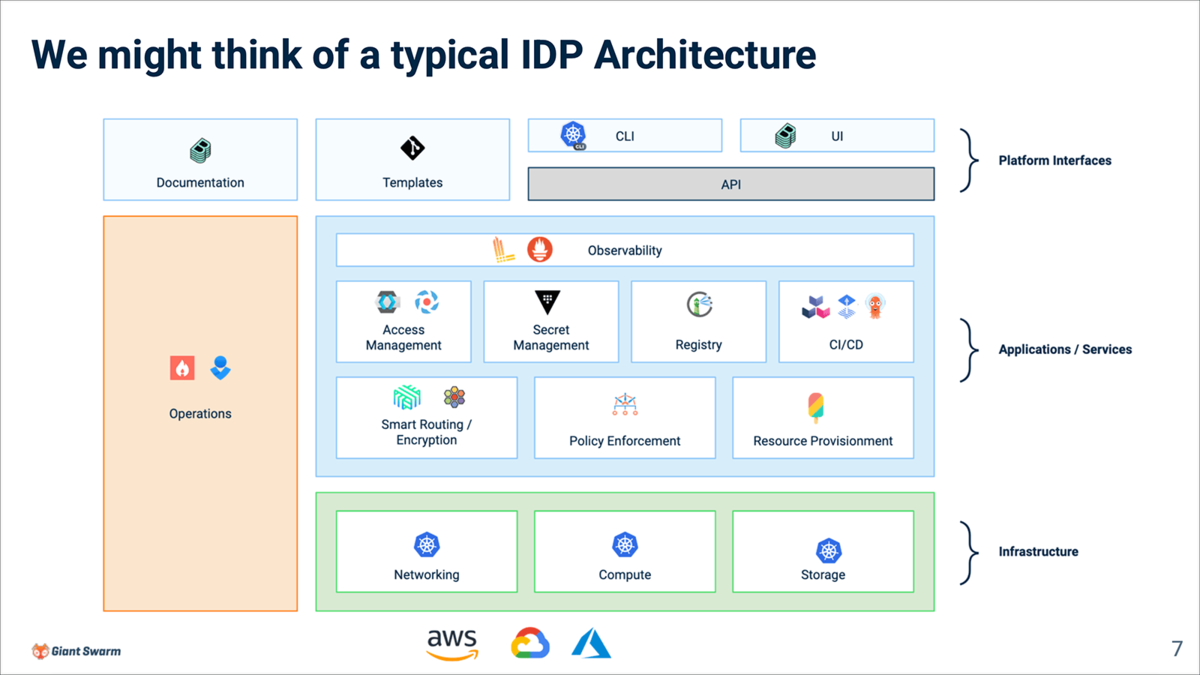
IDPのサービスアーキテクチャが図示されており、非常にわかりやすい構成でした。弊チームではリリース自動化には取り組んでいるものの、IDPとしての構成図は明確に描けていなかったため、この図に当てはめることで自分達が注力している部分(Applications / Services層)を再認識する良い機会となりました。
Golden Path
セッション内で印象的だったキーワードのひとつが「Golden Path」です。これは、開発者が迷わず最適な方法でアプリケーションを構築・運用できるよう導く、標準化されたベストプラクティスの道筋と定義されています。新規プロダクトのスピーディな立ち上げが求められる弊チームにとって、Golden Pathの整備はDX向上の鍵であり、改めてその重要性を実感しました。

Day 2
このセッションでは「Day 2」というフェーズが明確に定義されており、プロダクトがリリースされた後の運用・改善フェーズに焦点が当てられていました。セッション内でDay 2におけるアプリケーション開発者・プラットフォームエンジニアそれぞれの役割や課題が具体的に紹介されています。


Best Practices
セッションの最後では、Day 2を見据えたベストプラクティスが紹介されていました。

中でも「イテレーションをKPIとする」という考え方は、これまであまり意識できていなかった視点であり、非常に良い気づきとなりました。弊チームではPoCからプロダクトフェーズへの移行が多いため、継続的な改善を前提としたプラットフォーム設計と運用が今後ますます重要になると感じています。今回のセッションで得た知見を活かし、Golden Pathの整備や自己サービス化の推進など、開発者がより快適に開発できる環境づくりを進めていきたいと思います。
Japan Community Day Doc Sprint参加レポート
EC基盤開発本部 SRE部 商品基盤SREブロックの佐藤です。私はJapan Community Dayで開催された『Doc Sprint』に参加しました。
Japan Community Dayとは

KubeCon + CloudNativeConの開催前日に行われる実質0日目イベントで、Cloud Native Community Japanが主催となって企画しています。公式サイトのとおり、セッションやLTに加えてハンズオン型プログラムが充実しており、初参加の人でも気軽にOSSへ関われるのが大きな魅力です。今回は、その中で開催された『Kubernetesドキュメント Doc Sprint』に参加しました。
Doc Sprintの概要
- 目的:Kubernetes 公式ドキュメント日本語版の品質向上と翻訳差分の解消
- 対象リポジトリ:https://github.com/kubernetes/website
- メンター:レビューとマージ権限を持つDocs Approver2名
当日の作業フロー
リポジトリ準備
kubernetes/website をForkし、ローカルにclone。ローカルプレビュー
Hugoサーバーを起動し、ブラウザで該当ページを確認。修正前後の差分を比較。ドキュメント編集
content/ja/docs/以下のMarkdownを修正。PR作成
mainブランチにPull Requestを提出し、Reviewerをアサイン。レビュー&マージ
メンターが即時レビュー → LGTM → Approved → Merge。初のコントリビュートが、わずか数十分で完了しました。
得られた学び
翻訳ガイドラインの理解と運用
翻訳ルール(Localization Guide)にあるように、表記の統一や語彙の取り扱いには明確なルールが定められています。日本語訳では、下記の項目にあるような細かい議論が発生しやすいことを実感しました。それをApproverの方と直接相談できたのは貴重な体験でした。
- 長音記号(例:クラスター vs クラスタ)を使うか
- カタカナ表記または英語表記か
- 特に「node」のように文脈によって意味が変わる単語の扱い(例)
コントリビューションの可視化とモチベーション
DevStatsダッシュボードを使うと、コントリビューターの国別・企業別・個人別の貢献状況などを確認でき、モチベーションアップに直結する仕組みがあることを知りました。自分の名前も実際に確認できました。
コントリビューターロールの明確化
Kubernetes Docsチームには明確なロールと責任があり、少しずつ経験を積んで、Reviewer・Approverへと進んでいける仕組みが整備されていました。
- Anyone:定期的にコントリビュートする人。誰でもなれる。
- Member:Issueのトリアージや非公式レビューが可能になる。
- Reviewer:公式レビューをリードし、品質保証を担う。
- Approver:マージ権限を持ち、ドキュメント全体の整合性を管理する。
その他
- 日本語翻訳は世界で3番目に活発な言語化プロジェクト(資料:Kubernetes SIG Docs Localization Subproject (ja))。
- とくにブログの翻訳は世界最速を目指している(記事が出た当日に徹夜で翻訳することもあるそうです!)。
- 活動を支えるために、小さなPRや更新の積み重ねが大切である。
- Slack(#sig-docs-ja)で情報共有や相談ができる。
- 「このページに記載されている情報は古い可能性があります」バナーがついているページは、初心者に最適な貢献ポイント。
まとめ
Doc Sprintは「Approverにすぐ相談できる」「PRがその場でマージされる」という即時フィードバックが魅力の学習環境でした。ドキュメントは常に改善余地があり、OSS初心者が成功体験を得やすい入口だと実感しました。今後も更新が滞っているページの刷新に取り組み、Kubernetes日本語ドキュメントの充実に貢献していきたいと思います。
最後に、機会をくださったApproverの皆さん、そして一緒に参加してくださった皆さん(ZOZOブースにもお越しくださりありがとうございました!)に感謝いたします。
Exploring Tenant-centric Strategies To Simplify Multi-cluster and Multi-cloud Complexities
SRE部フロントSREブロックの三品です。私が所属するSRE部フロントSREブロックでは、ZOZOTOWNが持つAPIの中でもクライアントに近い、BFFを含むFrontendレイヤーのサービスを運用しており、言わばEmbedded SRE的な業務を行っています。今回、日本初開催のKubeConに参加して私が今回興味深いと感じたセッションを紹介します。
https://kccncjpn2025.sched.com/event/1x710/exploring-tenant-centric-strategies-to-simplify-multi-cluster-and-multi-cloud-complexities-wei-huang-fan-yang-applekccncjpn2025.sched.com
このセッションでは、マルチクラスターやマルチクラウドにより複雑化するKubernetes環境を、運用担当者がどのように管理していくかが解説されていました。セッションの冒頭では、プラットフォームエンジニアとエンドユーザーの両視点から、Kubernetes環境の複雑性とそれに伴う課題が紹介されていました。
Infra / Platform Team目線
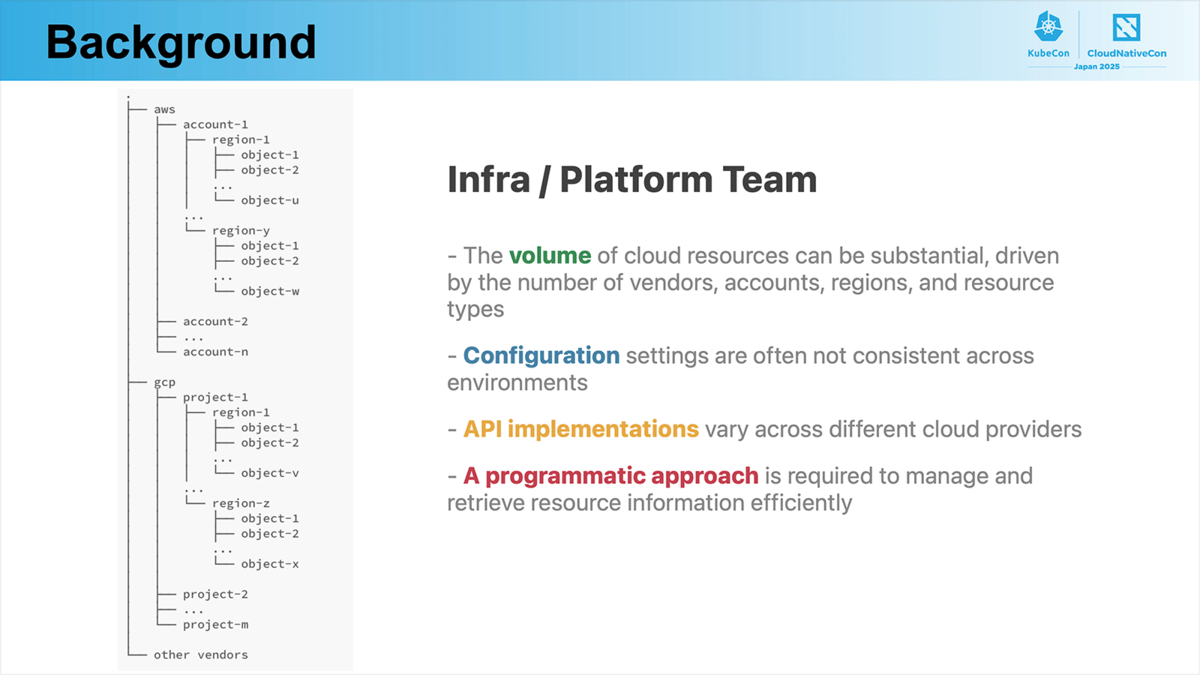
マルチクラウド・マルチリージョン環境では、管理すべきリソースの数の急増が指摘されました。加えて、クラウドプロバイダーごとにAPIや構成方法が異なるため、統一的な管理が難しいという課題も挙げられました。これらを背景に、効率的なリソース管理には、プログラマブルなアプローチが不可欠であると説明されています。
End use 目線
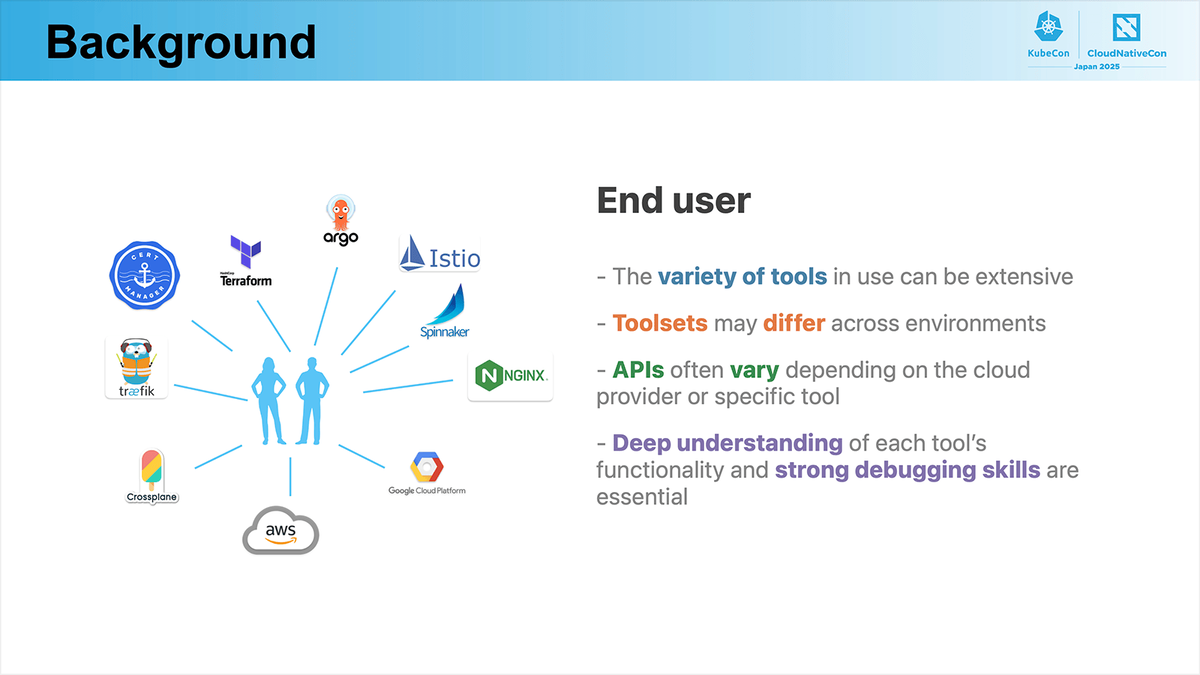
一方でエンドユーザー側では、マルチクラウドやマルチクラスター構成の影響で、利用するツールが多様化しています。ツールやクラウドごとに操作方法やAPI仕様が異なるため、それぞれのツールに関する深い理解と、高度なデバッグ能力が必要であると述べられていました。これらの問題に対してセッションでは、以下のようなゴールが設定されます。
- ツールやクラウドプロバイダーの違いを吸収する抽象化レイヤー
- コード生成や設定ファンアウトを含む、リソースのプログラム的テンプレート化
- 一貫性と拡張性を両立したAPI駆動型プラットフォーム
- スキーマに基づいてリソース定義と構成を管理する自動化と制御の仕組み
スライドのようなアーキテクチャが説明されていました。
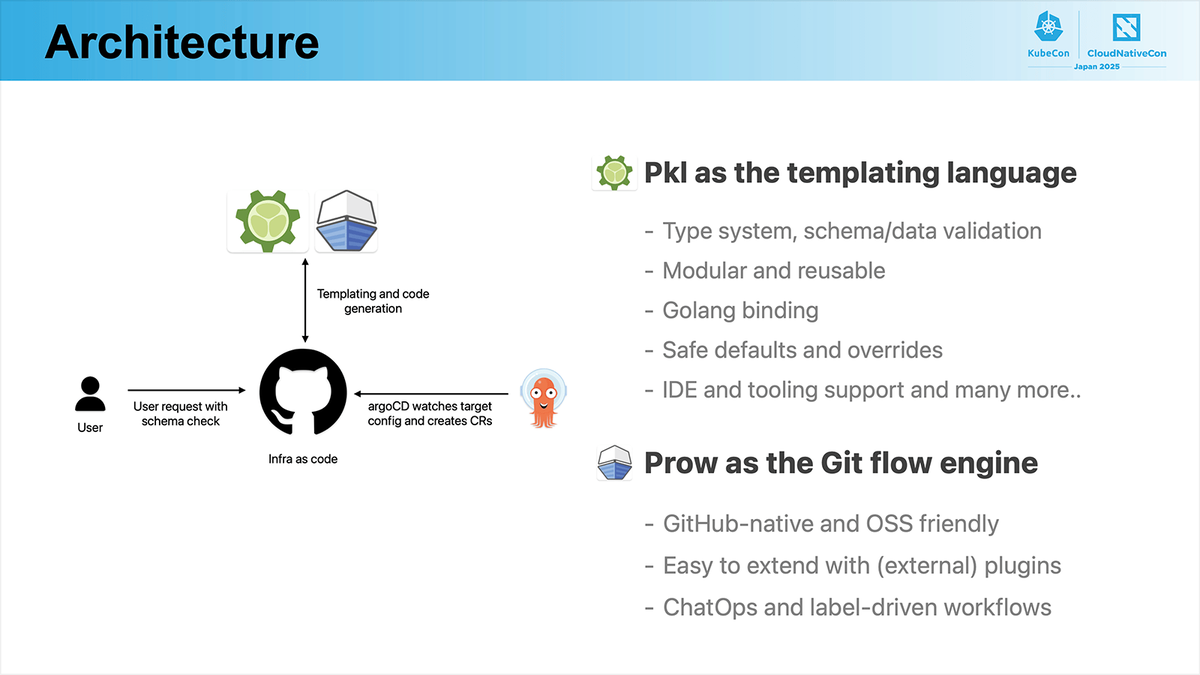
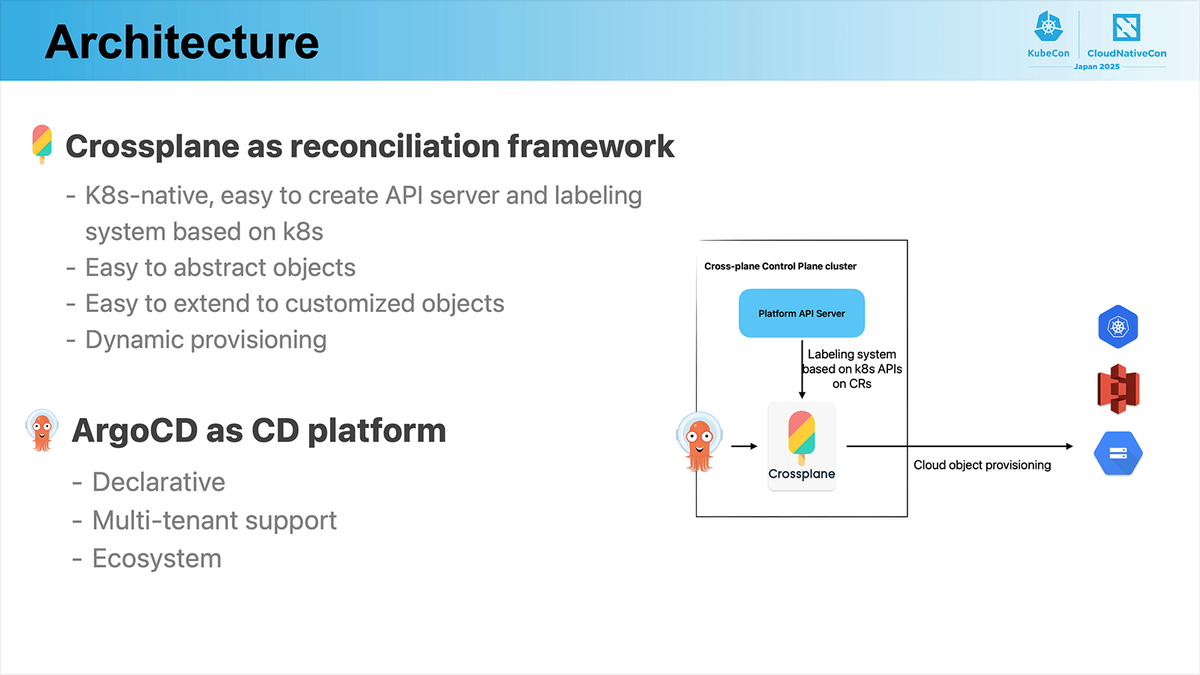
また、アーキテクチャの説明が行われたのち、達成順序についても述べられていました。

個人的に興味深かった点は、Pklを採用している点とマルチクラスタ構成そのものについてです。
まず、Pklについてですが、ZOZOではKubernetesマニフェストをKustomizeを使い base/ + env/ 構成で管理しています。ただし、この構成では各環境の値(例えば、JVMのパラメーターなど)を静的に定義する必要があり、条件分岐やデフォルト値の設定などをロジックベースで扱うことが難しいという課題があります。
一方で、Pklを用いることでこうした条件分岐やデフォルトの共通化をプログラマブルに表現できるため、より柔軟な構成管理が可能になると感じました。ただし、Kustomizeを使った純粋なYAMLを使った書き方に比べると、学習コストが増えることが予想され、新規メンバーがJoinした際に必ず学習期間を設ける必要があります。そういった点で利便性と学習コストが採用する際の天秤として難しいなと個人的には感じました。
次に、マルチクラスタについてです。ZOZOTOWNでは、EKS上でシングルリージョン・シングルクラスタのマルチテナント方式でKubernetesを運用しています。
これまで私は、マルチクラスタ構成について「クラスタ内の構成は簡素になっても、マニフェストの管理やアップデート時の運用負荷が増えるのではないか」と考え、あまり前向きに検討してきませんでした。しかし今回のセッションを通じて、もし各クラスタに対してリソースを自動でApplyできるような環境(例:Crossplane + ArgoCDなど)を整備できるのであれば、要件的にマルチクラスタ構成が必要ない場合でもクラスタ間の責務を明確に分離することで、個々の構成をシンプルに保ちつつ安全性や柔軟性の高い運用ができる可能性あると感じました。
一方で、マルチクラスタ化が進むと、それぞれのクラスタにインストールされるカスタムオペレータ(CRDやコントローラ)の数も増えていきます。その場合、各オペレータのアップデート対応や互換性の確認など、新たな運用コストが発生する懸念もあります。これまで私はマルチクラスタについて深く考える機会があまりなかったのですが、今回のセッションを通じて、改めてそのメリット・デメリットを整理し、今後の構成設計に活かしていきたいと感じました。
Cloud Native Scalability for Internal Developer Platforms
こんにちは、Platform SREブロックの石井です。Cloud Native Scalability for Internal Developer Platforms - Hiroshi Hayakawa, LY Corporationをご紹介します。
https://kccncjpn2025.sched.com/event/1x71O/cloud-native-scalability-for-internal-developer-platforms-hiroshi-hayakawa-ly-corporationkccncjpn2025.sched.com
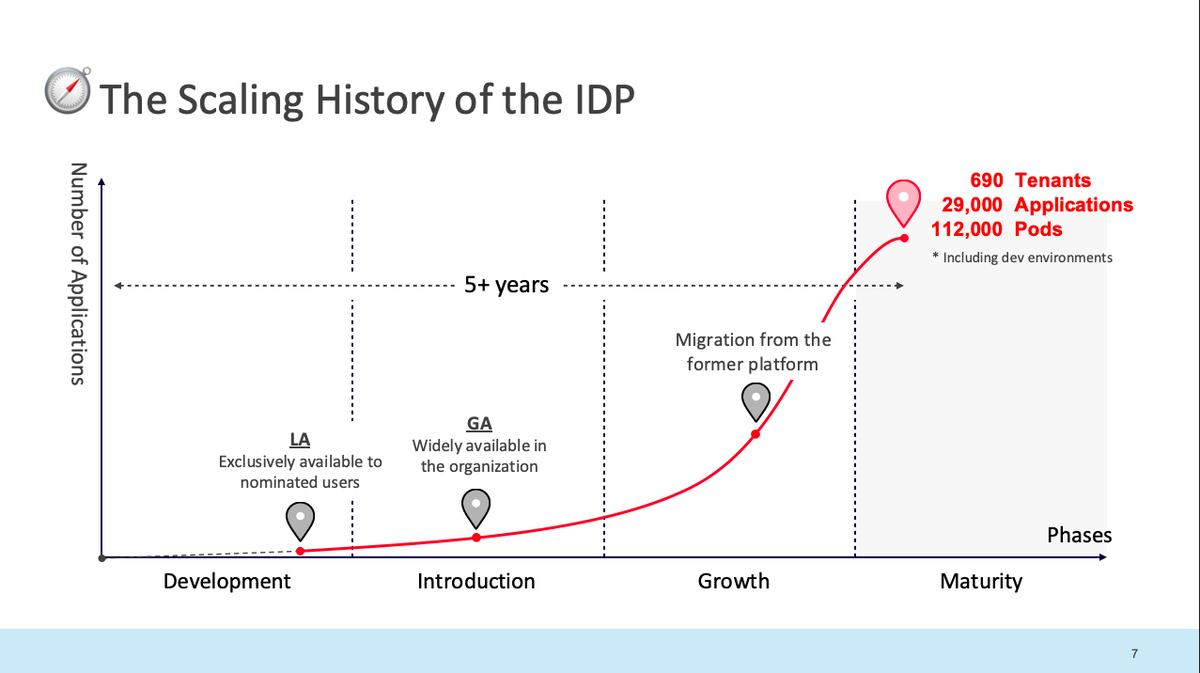
自分はプラットフォームエンジニアとして活動しており、「Kubernetesにはスケールの限界があるのか・大きなスケールのチームは何か特別な扱い方をしているのか」という疑問がありました。本セッションでは 690 テナント / 29,000 アプリ / 112,000 Pods という国内最大級の規模を約5年間で実現した実践例および現状の課題が紹介されました。まさに自分達が現在直面している課題や、“数年後の自分たち”に直結する何かが得られると考え、セッションを拝見しました。
セッション概要
以下のような内容が本セッションでは紹介されていました。
- 背景:シンプルなコマンドでアプリケーションを実行できるHerokuのようなPaaS(IDP:Internal Developer Platform)を構築し、全社開発者へ提供。
- 5年のスケーラビリティの旅:スケールする中でさまざまばクラスタ設計・運用自動化・メトリクス基盤・コントローラ性能の壁を順に突破。
- 現在直面している課題:Control Planeの限界とController Shardingへの挑戦。
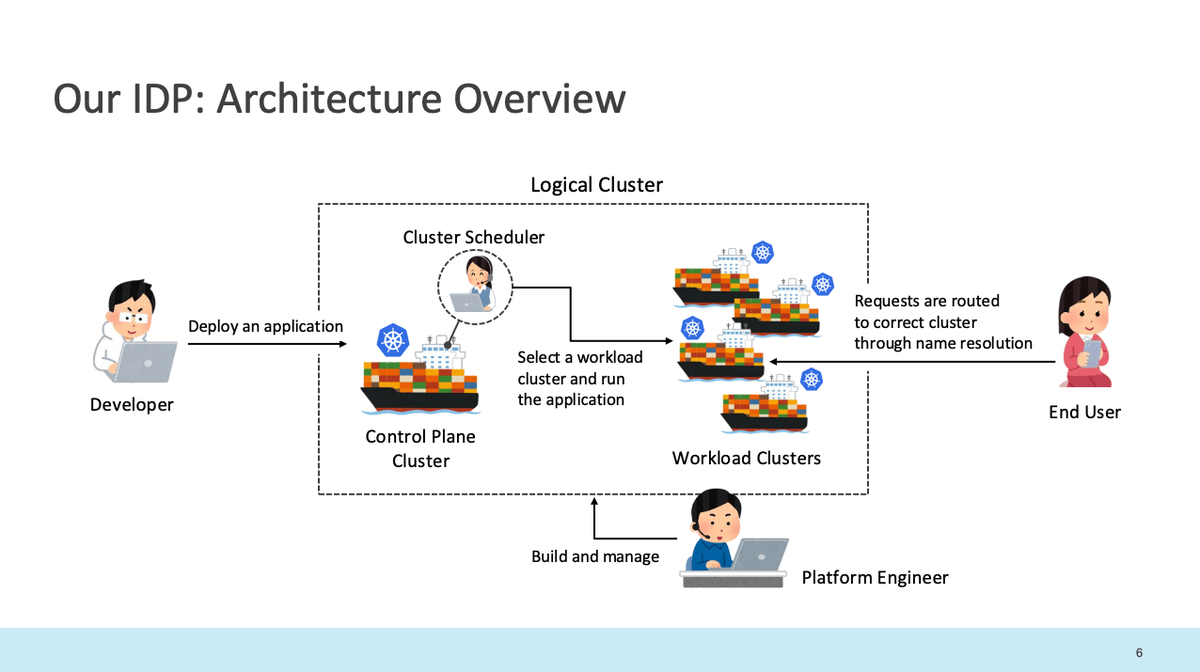
1. Internal Developer Platform(IDP)の全体像
まずは、IDPの全体像が紹介されており、規模の大きさに非常に感銘を受けました。
- 構成:
- 特徴:単一Control Plane Clusterで複数Workload Clustersを制御し、「論理的な一つのクラスタ」として扱う設計
- Control Plane Cluster : ユーザーからの支持を受け付け、アプリケーションのデプロイに必要な処理を行うクラスタ。どのWorkload Clusterにスケジュールするか・アプリケーションを外部に公開する準備を行う
- Workload Clusters : アプリケーションを実際に実行するクラスタ群
スケールの変遷
2. スケーラビリティの旅と直面した壁 (Scalability Journey in Our Internal Developer Platform)
この大きくスケールした5年間で直面した課題やそれに対する決定などが紹介されていました。一部を紹介します。
2-1. クラスタ設計:Single vs Multi
非常に多くのアプリケーションをホストする要件があったため、どのようにしてKubernetes Clusterをスケールするかは非常に重要な事項であった。主に2つの選択肢があった。
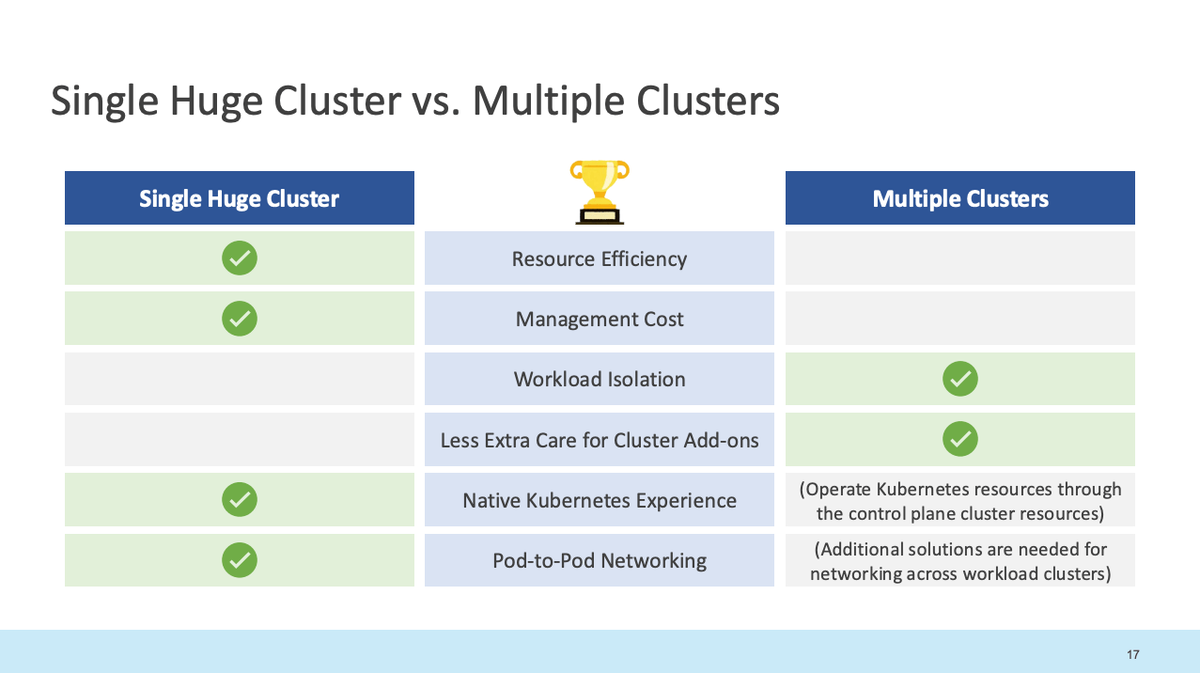
結果:マルチクラスタを選定
決め手:組織的に複数クラスタ運用ノウハウがあり、社内の要件に則った。これは絶対的な正解ではなくチームのスキルセットや組織の要件によってことなる。
マルチクラスタ設計
CPU / メモリを大きく消費するアプリケーションだけを Silo Cluster に隔離、残りは Pool Cluster で共有するハイブリッド方式を採用。これによりNoisy Neighborの問題を最小限にできる。
- Silo Cluster : 特定ワークロードのリソース消費が大きいなどの理由によりシングルテナントで利用されているクラスタ
- Pool Cluster : マルチテナントでリソースが共有されているマルチテナントのクラスタ
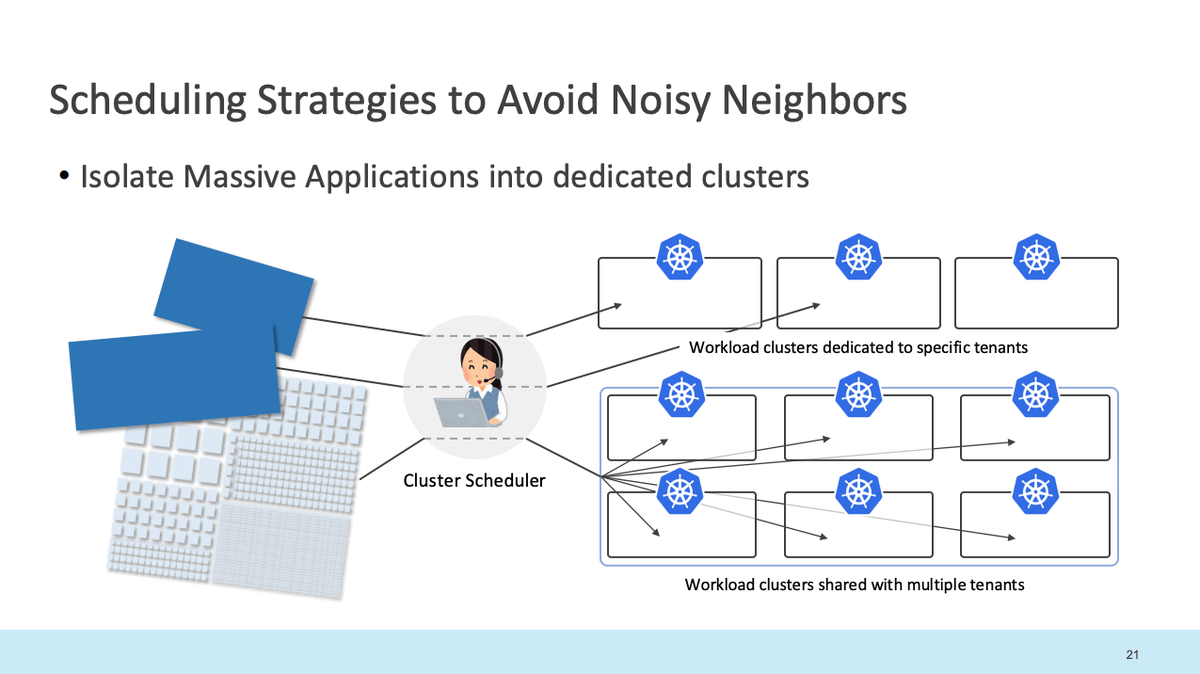
2-2. オペレーショナルスケーラビリティ
DeveloperチームがPlatform利用開始する、オンボーディング関連作業を少数のPlatformチームメンバーのみで行っていた。しかし、組織にプラットフォームを公開する必要があり、この作業をスケーラブルにする必要があった。
自動化前:
- 開発者がチケット経由でテナントをリクエスト
- プラットフォームエンジニアが対応:
- Athenzに認可ポリシーを登録
- Git上にNamespaceを作成(GitOpsにより管理)
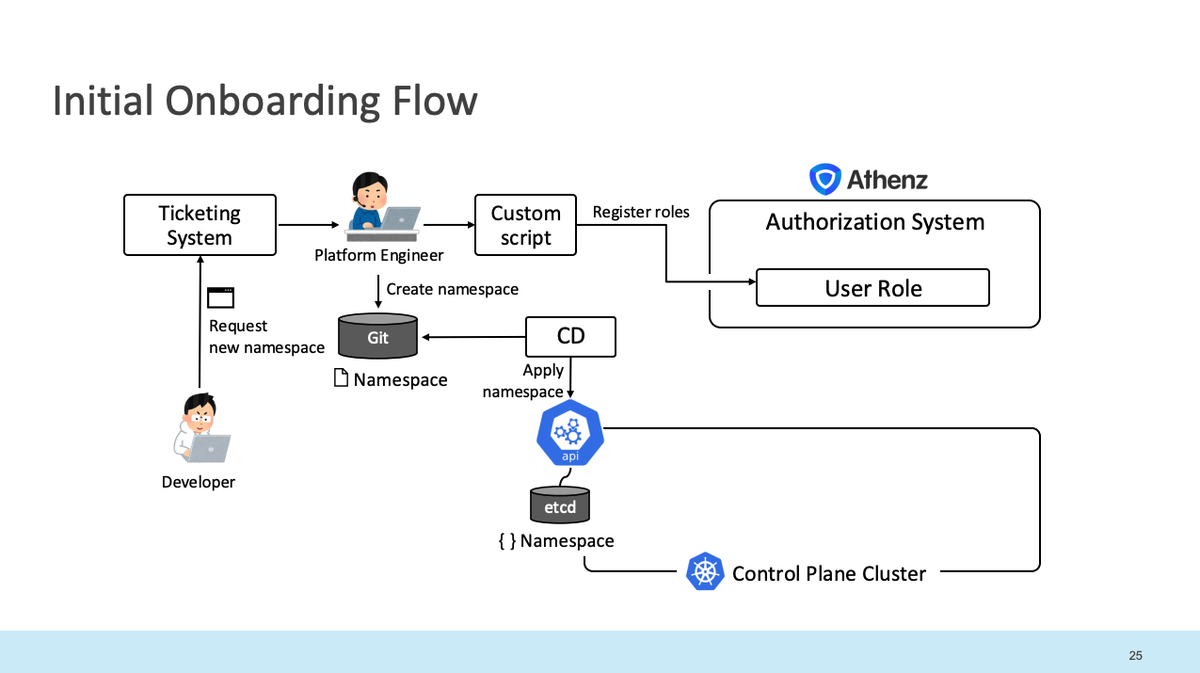
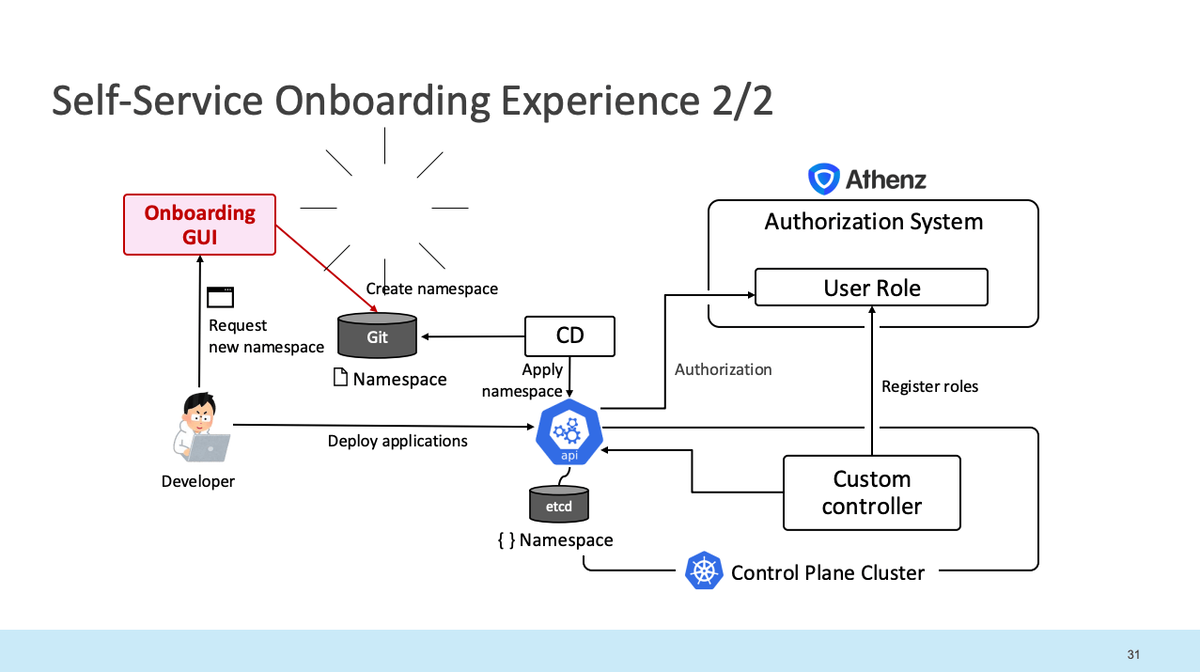
自動化後:
- カスタムコントローラを作成し、ポリシー登録を自動化
- チケットシステムをオンボーディングアプリに置き換え
- 現在は完全セルフサービス化。開発者自身でオンボーディング可能に
2-3. カスタムコントローラ性能
カスタムコントローラーはリコンサイル処理で競合を起こさないように単一のインスタンスで動作する必要がある。しかし、クラスタの規模が大きくなると単一インスタンスのスケールアップだけでは、様々な問題に直面するようになった。
- 現状:単一Podでスケールアップ
- 現在挑戦中:CNCF Sandboxtimebertt/kubernetes-controller-shardingへコントリビュートし水平分割(Shard)による Scale-Out を検証中
3. いま直面している3つのControl Planeの課題
Platformが成長しスケールするにあたり、生じたControl Planeに関する複数の課題が紹介されていました。
- リソース数増加により、kube-apiserverの消費メモリが増大する問題
- v1.33からデフォルトONの Streaming List で解消見込み
- etcd サイズ肥大
- Aggregation Layer経由で一部のCRDをWorkload Clusterへ移譲
- Controllerがスケールアップしかできない
- Kubernetes Controller Shardingをへ会社としてコントリビュートしている。
おわりに
本セッションで最も印象に残ったのは、「スケールの旅に終わりなし。その旅を楽しめ」 という姿勢でした。大規模運用を支える構成や技術選定はもちろん、負荷の特性に応じたクラスタ分離戦略(Silo / Poolモデルの併用)、無理なく自動化を進める段階的アプローチ、といったひとつひとつの設計思想に、深く感銘を受けました。そして、Controller Shardingのようなまだ未成熟な領域にも、「必要だから、自分たちで積極的にコントリビュートする」という姿勢が垣間見えた点も非常に刺激的でした。このセッションには多くの刺激を受け、また、学びを得ることができました。これを自社のプラットフォームの発展にも役立てていきます。
ZOZOブースの紹介

ZOZOのスポンサーブースでは、ZOZOTOWNのアーキテクチャとOSSデモをメインコンテンツとして展示しました。また、各プロダクトのステッカーやZOZOの計測テクノロジーを生かしたZOZOGLASSとZOZOMATを配布しました。


ZOZOTOWNのアーキテクチャ
展示コンテンツの1つであるZOZOTOWNのアーキテクチャについて、プラットフォームSREの酒部と、検索基盤SREの徳山から紹介いたします。2人とも25年度新卒として入社しました。
ZOZOTOWNでは長らくオンプレミスからクラウドへの移行とマイクロサービス化を進めています。
まだ移行過渡期であるものの、日本で初めて開催される「KubeCon + CloudNativeCon Japan 2025」というクラウドネイティブの世界的なカンファレンスで展示することで、社外からの疑問や意見を交換できる機会になると考え、このコンテンツ制作に至りました。会期中に展示していたスライドの一部を掲載いたします。
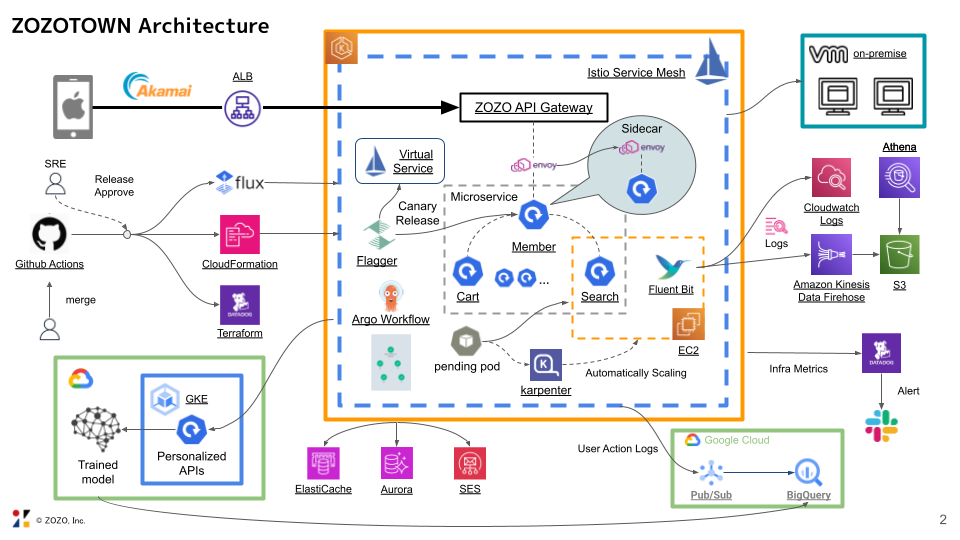
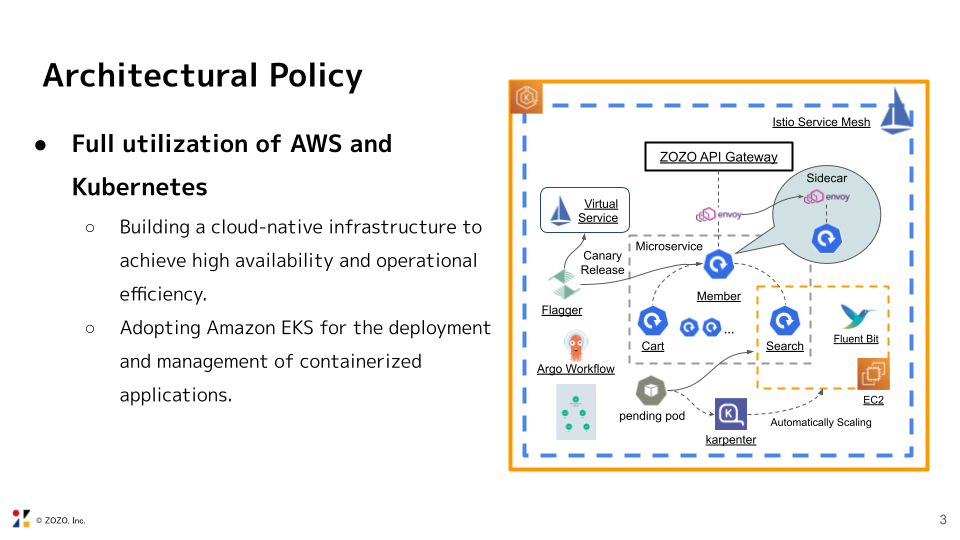
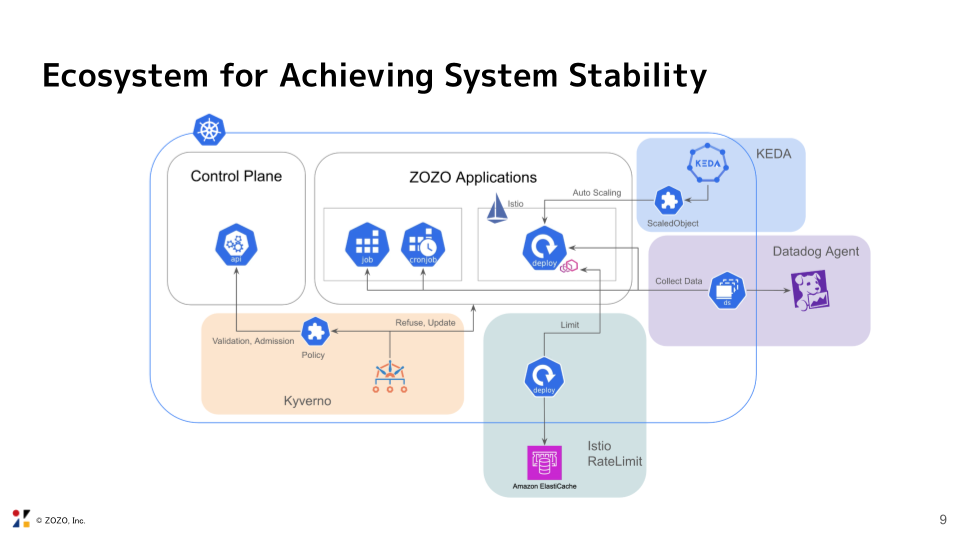
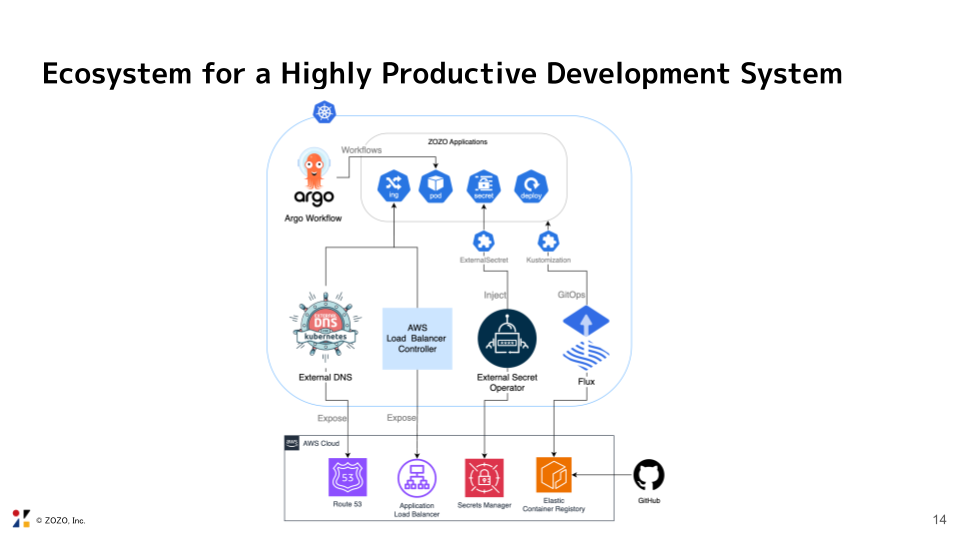
「クラウドをどのように使い分けている?」、「プラットフォームが多機能で運用が大変そう」といった質問や感想を頂きました。
僕たちはZOZOTOWNの新卒SREと言う立場で今回のイベントに参加し、アーキテクチャ図の制作からブース対応をする中で多くの気づきがありました。
今回、ZOZOTOWNのアーキテクチャとマイクロサービスを自動リリースする手法について先輩社員から学びながらアーキテクチャ図を制作しました。ZOZOTOWNの全体像と安全にリリースするための先進的な仕組みを学ぶことができる貴重な機会になりました。ブース対応をする中で他社のアーキテクチャも聞けましたが、他社さんに比べてZOZOでは独自のAPI Gatewayを作っているなど、オンプレを含むハイブリッドな構成であることを感じました。
参加者の半分くらいは日本人で言語の壁を感じることなく議論ができました。また海外の参加者も日本語で話しかけてくださったりして、英語に苦手意識がある自分でも緊張せずに議論できて、本イベントの参加者の暖かさも感じることができてよかったです。
ブース出展したことで、Kubernetesを中心としたクラウドネイティブ技術の最前線に触れられただけでなく、世界中の情熱的なエンジニアと繋がれる素晴らしい機会になりました。ブースに立ち寄って頂いた皆様、ありがとうございました。
OSS デモ
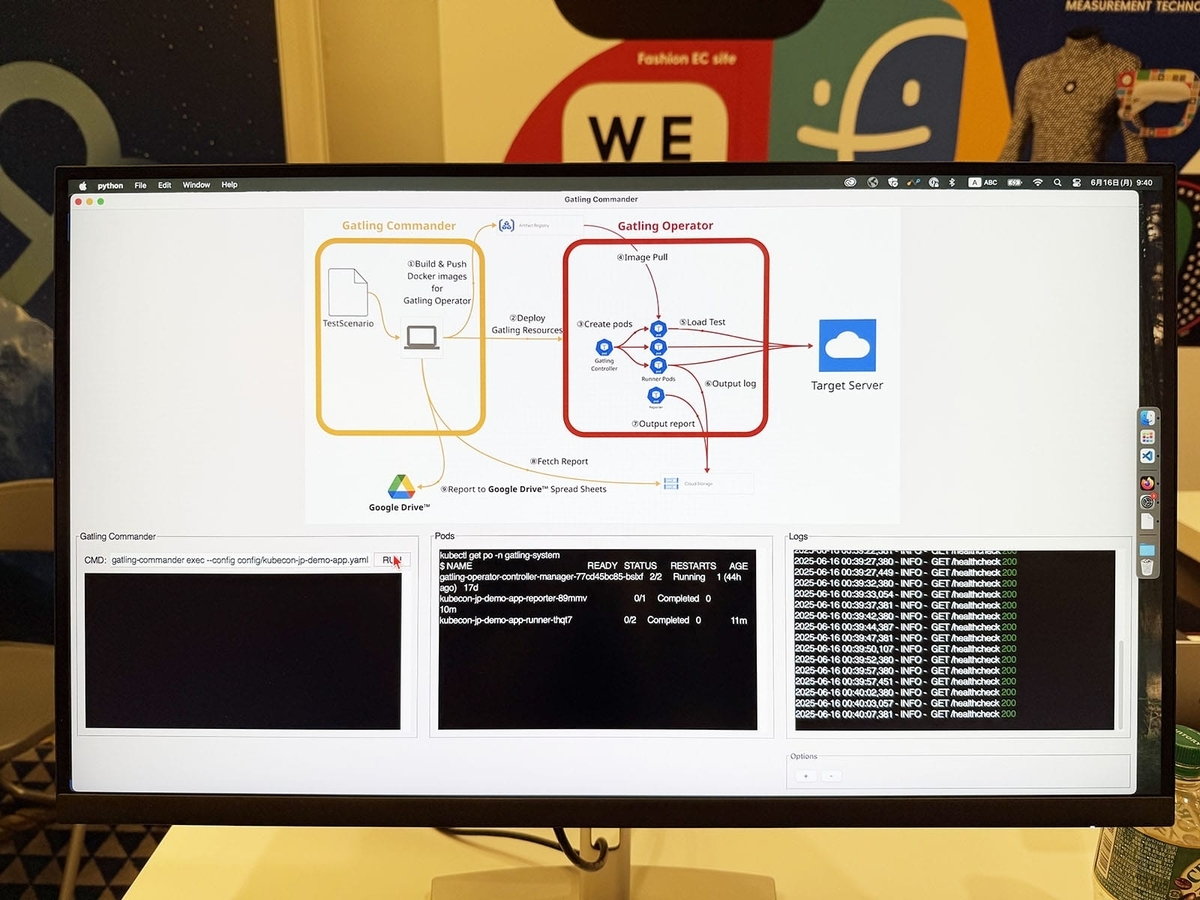
ZOZOにて開発し利用している大規模負荷試験ツール「Gatling Operator」と、複数の負荷試験を省力化して実行可能なCLIツール「Gatling Commander」のデモを行いました。

Gatling Operatorは、Gatlingをベースとした分散負荷試験のライフサイクルを自動化するKubernetes Operatorです。Gatling CommanderはGatling Operaorによる複数の負荷試験を自動的に連続・連携して実行可能とし省力化するCLIツールです。
Gatling Commanderを実行するとGatling Operatorが立ち上って対象サーバーへリクエストが行われ、テスト結果がGoogle スプレッドシートで一覧確認できるデモを行いました。
デモはGatling Commanderを実行するCLI、Gatling Operatorが動作するKubernetesのPodの状態、対象サーバーのアクセス状況を表示するツールを作成しました。
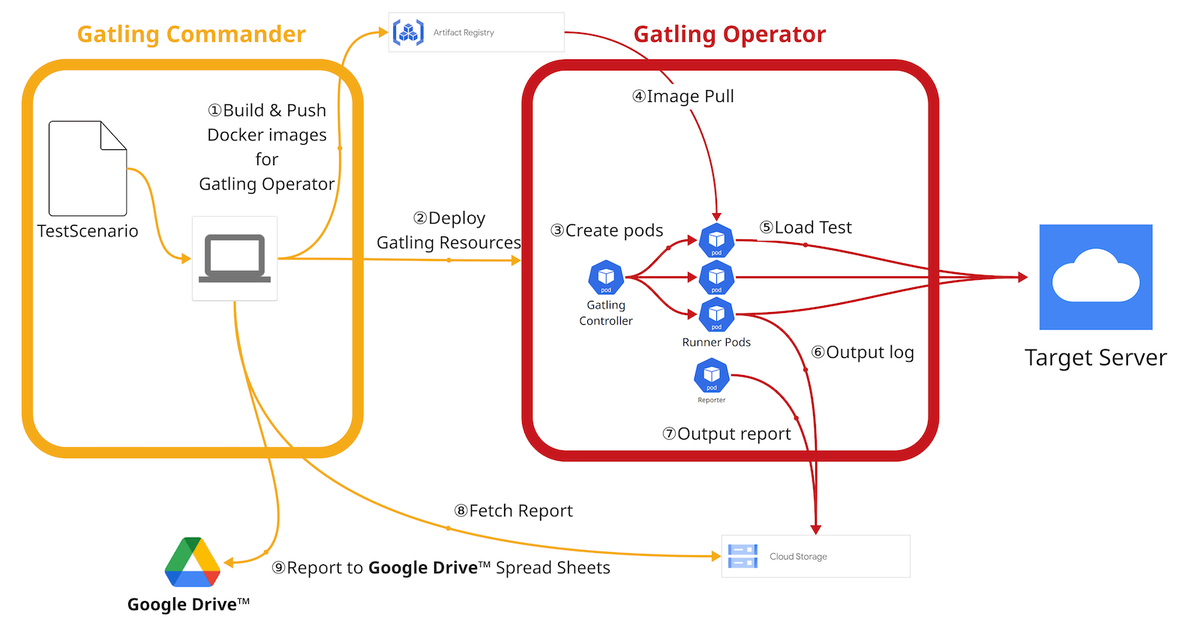
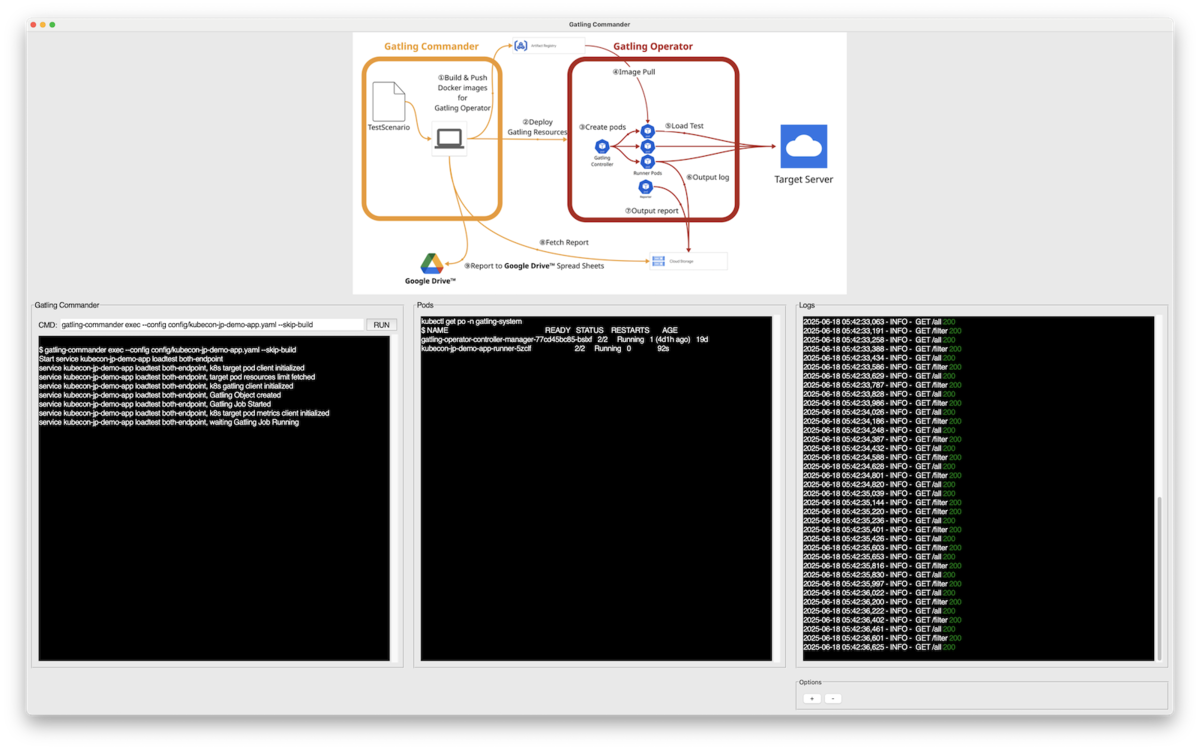
テスト結果はGoogle スプレッドシートで参照可能です。結果はGoogle スプレッドシートに複数のテストを集約する形で表示されます。

Gatling OperatorとGatling CommanderはそれぞれオープンソースとしてGitHubで公開しています。また、過去に公開している関連記事もみていただけると嬉しいです。
協賛企業ブースのコーデまとめ
あっすーです。他カンファレンスと同じように協賛企業ブースを回ってきましたので、各ブースのコーデをお送りします! 各社の雰囲気に合わせたデザイン・着こなしは、やはりZOZOとしても気になるポイント。参加した方は当日の会場の様子を思い出しながらご覧ください。






















お忙しい中ご協力いただいたブースの皆様、本当にありがとうございました!
おわりに
日本初開催のKubeCon + CloudNativeCon Japanに協賛、そしてブースを出展できたことはとても良い経験になりました。改めてブースにお越しいただいた多くの皆さん、ありがとうございました。少しでもZOZOに興味を持ってもらえたら幸いです!

ZOZOでは、一緒に働くSREの仲間を募集しています。ご興味のある方はこちらからご応募ください。
- ZOZOTOWN SRE | 株式会社ZOZO
- https://hrmos.co/pages/zozo/jobs/1809846973241688280
- https://hrmos.co/pages/zozo/jobs/1809846973241688274
- SRE(オープンポジション) | 株式会社ZOZO
また、会期中は混雑していることも多く、じっくりとお話しする時間が取れなかったので、もう少し詳しく話を聞きたい! という方はカジュアル面談も受け付けています。
既に来年開催される「KubeCon + CloudNativeCon Japan 2026」のページも公開されています。来年も素敵なカンファレンスになることを期待しています!
現場からは以上です!