



はじめに
こんにちは。SRE部フロントSREブロックの三品です。
3月19日から3月22日にかけてKubeCon + CloudNativeCon Europe 2024(以下、KubeCon EUと呼びます)が行われました。今回弊社からはZOZOTOWNのマイクロサービスや基盤に関わるエンジニア、推薦システムに関わるエンジニアの合わせて4人で参加しました。
本記事では現地の様子や弊社エンジニアが気になったセッションや現地の様子について紹介していきます。
目次
KubeCon EU 2024の概要
昨年4月にオランダ アムステルダムで行われたKubeCon EUの様子については昨年の参加レポートをご覧ください。
今年のKubeCon EUはフランスのパリで開催されました。昨年まではコロナ禍の影響もありオフラインとオンラインのハイブリッドで開催されていました。
しかし今年はオフラインに統一され12,000人以上が現地で参加しており、今年もKubeCon EU史上最大の参加人数を更新しました。

KubeCon EUではキーノートやセッション、LTなどを通してKubernetesに関する最新のアップデートの紹介や実際にKubernetesを採用した企業の幅広い運用ノウハウを聞くことができます。
以降では参加してきた社員がそれぞれ気になったセッションや現地の様子について取り上げてご紹介します。
セッションの紹介
- セッションタイトル
- Tutorial: Cloud Native WebAssembly and How to Use It - Brooks Townsend & Michael Yuan
- Cloud-Native LLM Deployments Made Easy Using LangChain
- Strategies for Efficient LLM Deployments in Any Cluster
- Why Is This so HARD? Conveying the Business Value of Open Source
- Kubernetes Maintainers Read Mean Comments
- To Infinity and Beyond: Seamless Autoscaling with in-Place Resource Resize for Kubernetes Pods
- Comparing Sidecar-Less Service Mesh from Cilium and Istio
- Future of Intelligent Cluster Ops: LLM-Azing Kubernetes Controllers
- Is Your Image Really Distroless? - Laurent Goderre, Docker
- Building Confidence in Kubernetes Controllers: Lessons Learned from Using E2e-Framework - Matteo Ruina, Datadog & Philippe Scorsolini, Upbound
Tutorial: Cloud Native WebAssembly and How to Use It - Brooks Townsend & Michael Yuan
ML・データ部MLOpsブロックの松岡です。
私の所属するMLOpsブロックではMLを使用した様々なサービスのプラットフォームを運用しています。MLにおいて近年話題になっているのがLLM(大規模言語モデル)とLLMを使った生成AIです。KubeCon EUでもLLMについてのセッションが多くありました。
その中でも特に興味深かったのがWasmを紹介した次のセッションです。
Wasmについての概要
LLMを実用化するにあたって重要な懸念点の1つがサービスがスケールする際のコストの問題です。
それを解決するためにユーザーのCPUやGPUで高速にプログラムを動かすことができるWebAssembly(Wasm)が注目されています。
このセッションでは、Wasmの概要から入り、実際にWasmを使ってLLMを動かしChatbotを構築する方法を紹介していました。説明が幅広く網羅的でかつ具体的でわかりやすかったです。
Wasmはブラウザ上で高速にプログラムを動かすために登場したバイナリコード形式のプログラミング言語です。
アセンブリと言う名前ですが、コーディングにあたってアセンブラ言語を記載する必要はなく、C言語やRustなど様々な高級言語からWasmバイナリにコンパイルできます。
コンパイル済みのコードは純粋な機械語ではなく抽象化された機械語となっており、Wasm Runtimeが各環境に応じた形へ変換し実行します。この仕組みによりJavaのように単一のコードで異なるOSやCPUアーキテクチャをサポートします。
当初この技術は3D処理などをブラウザ上で実行する用途として注目されていましたが、最近ではMLの推論をエッジで実行する用途にも注目されています。そしてWasmが小さなVMのようなものであることを応用しサーバーサイドにおけるDockerの置き換えとしても注目されているようです。

「Cloud Native Wasm And How To Use It」より引用
WASIでWasmの利用用途が広がる
このセッションではWASI(WebAssembly System Interface)0.2.0についても説明されていました。
WASIは、Wasmが直接サポートしていない標準入出力への読み書きや、ファイルシステム、ソケットへのアクセスなどアプリケーションに必要な機能をWasmから使用するのに使われています。これによりWasmはブラウザだけでなくサーバーサイドでの利用も可能になりました。
これらのインタフェースを標準化し、各Wasm Runtimeにてサポートすることで、実行環境が抽象化されコンテナ標準のように使用できるようになることがアナウンスされていました。
Wasmをコンポーネントとして扱い、コンポーネントを統合して新たなコンポーネントを作るアイデアが紹介されていました。それぞれのコンポーネントはGoやJavaなど様々な言語で記載可能です。コンパイラーがWasmのバイナリに変換します。コンポーネント間の入出力はWASIによるインタフェースで定義されます。
WASIはWIT(Wasm Interface Types)に基づく高度な型システムを利用できます。セッションではWITの型を一瞥できるwit-cheat-sheetが紹介されていました。
各コンポーネントはメモリー空間が独立しておりWASI以外には依存しないことで高い独立性を保ちます。そして、これらのコンポーネント間の呼び出しはナノ秒で行うことができるとのことです。WASIにより入出力が定義されているため、コンポーネント間は言語を揃える必要すらありません。Rustで書いたコンポーネントとGoで書いたコンポーネントを組み合わせて新しいコンポーネントを作るといったことが可能なようです。これはコードの再利用性を高め、システム構築の言語選定時に大きな自由度を与えてくれることになります。

「Cloud Native Wasm And How To Use It」より引用
Wasm Edge Runtimeにより多くの環境でバイナリを高速に動かすことができる
Wasm Edge Runtimeでの実行速度についての説明では、Wasmがネイティブの速度を超える事例について紹介していました。

「Cloud Native Wasm And How To Use It」より引用
これは、特定の環境に最適化されていないネイティブバイナリーコードよりは、実行環境ごとに最適化されたWasmのほうが高速になりえるという話です。特定の環境に最適化されたネイティブバイナリーコードよりWasmのほうが速いというわけではないので注意してください。WasmはWasm Runtimeにより実行環境に応じて最適化されて実行できる利点がここでは主張されています。
また、プラグインにより機能を提供することで最小の機能を保ちながら必要な機能を追加していく事が可能であること、一例としてガベージコレクションをプラグインで提供したことが紹介されていました。
このガベージコレクションはKotlinからの強い要望があったそうですが、Kotlinの実行環境としてJVMだけでなくWasmという新しい選択肢が出てくることは大変興味深いです。
Cloud NativeにおけるWasiの有用性
WasmをKubernetes上で動かし、Linuxコンテナーを置き換えるものとするアイディアも紹介されていました。
マイクロサービス化において、オーバーヘッドとなるLinux部分をWasmのモジュールへ置き換えることでコストの削減とスループットの向上につながる可能性があります。Wasmのモジュールはミリ秒で起動します。これはLinuxコンテナを起動するよりはるかに高速です。またWasmのモジュールが必要なメモリー量はLinuxコンテナよりも少ないです。そのため、Linuxコンテナの代わりにWasnのモジュールを用いることでコスト・運用ともに大幅な改善が期待できるとのことです。
また、Wasmはアーキテクチャに依存しないことも魅力的です。例えば私は普段Apple SiliconのMacBook Proで作業していますが、これにはArmをサポートするCPUとMetalをサポートするGPUが採用されています。ところがサーバーサイドでは一般的にx86をサポートするCPUとCUDAをサポートするGPUを使用することが多く、両環境でコンテナイメージを共有できませんでした。
Linuxコンテナイメージに変わって、Wasmコンポーネントを使用することでこの差は抽象化され両環境で一貫したバイナリを実行できるのはとても魅力的に感じます。フロントエンド寄りの技術だと思っていたWasmがCloud Nativeで大きな変革を起こす可能性があることは今回のセッションでの良い発見でした。
Wasmについて深く調べてみたくなりました。
LLMをエッジで動かすチュートリアル
セッション後半では実際にWasmを使用して簡単なHello World!を作成した後、より実践的なデモとして端末のGPUを使ってLLMモデルを動かしChatbotを実行するハンズオンが行われました。
LLMを使った生成AIは大量のコンピュータリソースを使用することがネックとなっています。WasmによりユーザーサイドのGPUを使用することでこの問題を解決できるかもしれません。このハンズオンのユースケースもまたWasmが今後大きく注目される部分だと思います。
WasmはCloud Native Wasm Day Hosted by CNCFにおいても詳しく紹介されているためそちらも合わせて見られることをおすすめします。
この他にもさまざまな魅力的なセッションがあり、全てを紹介できないので、いくつかをピックアップします。
Cloud-Native LLM Deployments Made Easy Using LangChain
このセッションではLangChainを使用したクラウドネイティブなLLMのデプロイ方法について段階を追って説明されていました。モデルをデプロイするための手順として使用するモデルの定義、モデルの実行方法についての検討、LLMのパッキング、モデルのコンテナ化、複数モデルの統合の5段階で説明されていました。ML、特にLLMについてはモデルの作成だけでなく生成もコストが大きいこと、その結果に曖昧性が残ることなどから多くの項目を検討する必要があることを考えさせられました。
Strategies for Efficient LLM Deployments in Any Cluster
利用用途に応じたモデル選定について解説したセッションです。コストの大きなLLMsだけでなく必要に応じてSMLs(Small Language Models)=小規模言語モデルを選ぶメリットなどを紹介しています。
モデルの得手不得手を理解して、複数モデルの使い分けを意識したいと思います。
Why Is This so HARD? Conveying the Business Value of Open Source
オープンソースプロジェクトの価値をいかに示すか解説したセッションです。GitHubのIssueやPull Requestへラベルを付けて進捗を可視化する方法など、オープンソースに限らずプロジェクト管理で幅広く活用出来そうなアイデアが紹介されていました。
Kubernetes Maintainers Read Mean Comments
KubernetesのIssueに投げられた意地悪なコメントについて紹介されていました。技術的な情報ではありませんが、コミュニティーがどのように機能しているかを理解し、円滑なコミュニケーションを推進する方法について示唆がありました。
To Infinity and Beyond: Seamless Autoscaling with in-Place Resource Resize for Kubernetes Pods
KubernetesでPodsを運用するうえで悩みの種であるスケーリングについて、スケーリングがどのように機能するか、新しいin-Place Pod Resizingについて紹介されていました。
スケーリングにおける副作用についての学びが大きかったです。
Comparing Sidecar-Less Service Mesh from Cilium and Istio
ML・データ部MLOpsブロックの岡本です。
Solo.ioのChristian Posta氏による、CiliumとIstio Ambient Meshを使ったサイドカーレスなサービスメッシュ構成の比較についてのセッションをご紹介します。本セッションのメインテーマでは、サイドカーレスなサービスメッシュについて、CiliumとIstio Ambient Meshを使ったそれぞれの構成を次の観点で比較していました。
- コントロールプレーン
- データプレーン
- 相互認証 / mTLS
- 可観測性
- トラフィック制御
サイドカーとは、Kubernetes Pod内のアプリケーションコンテナに対し補助的な役割を持つコンテナです。サービスメッシュを構成する場合に、従来はKubernetesの各Pod内でアプリケーションコンテナとEnvoyコンテナを稼働するサイドカーモデルが取られていました。
サイドカーモデルで構成するサービスメッシュには、サービスメッシュを透過的に構成できることや他のワークロードにリソースが占有されてしまう(ノイジーネイバー問題)を回避できるなどの利点がありました。

「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
一方でサイドカーモデルにはいくつかの課題もありました。例えば、アプリケーションコンテナとサイドカーコンテナの競合によるPodの起動・終了シーケンスの複雑化や、サイドカーのアップグレード時にアプリケーションの再起動が必要になることなどです。

「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
サイドカーレスなサービスメッシュはこのようなサイドカーモデルでの課題を解決するために提案されました。
次にセッションのメインテーマであるCiliumとIstio Ambient Meshを使ったサイドカーレスなサービスメッシュ構成の比較のうち、データプレーン部分の違いについて簡単にご紹介します。
サービスメッシュのアーキテクチャは大きくコントロールプレーンとデータプレーンに分かれています。データプレーンでは、主にPod間の通信を制御するプロキシの役割を担っており、コントロールプレーンではデータプレーンを管理しています。
データプレーンにおける構成の主な違いは、CiliumではOSI参照モデルのL4処理をeBPFで実装しているのに対し、Istio Ambient MeshではZtunnelで実装しているという点です。eBPFとはextended Berkeley Packet Filterの略であり、Linuxカーネルのコードを変更することなく、動的にカーネルの機能拡張を行う技術です。CiliumではeBPFを利用することでネットワーク処理を効率化しています。一方でZtunnelとはzero trust tunnelの略であり、Istio Ambient Meshのために実装されたNodeごとのプロキシです。Istio Ambient MeshではZtunnelを利用することでwaypoint proxy(L7処理を行うコンポーネント)へ効率的かつ安全にトラフィックを転送できます。
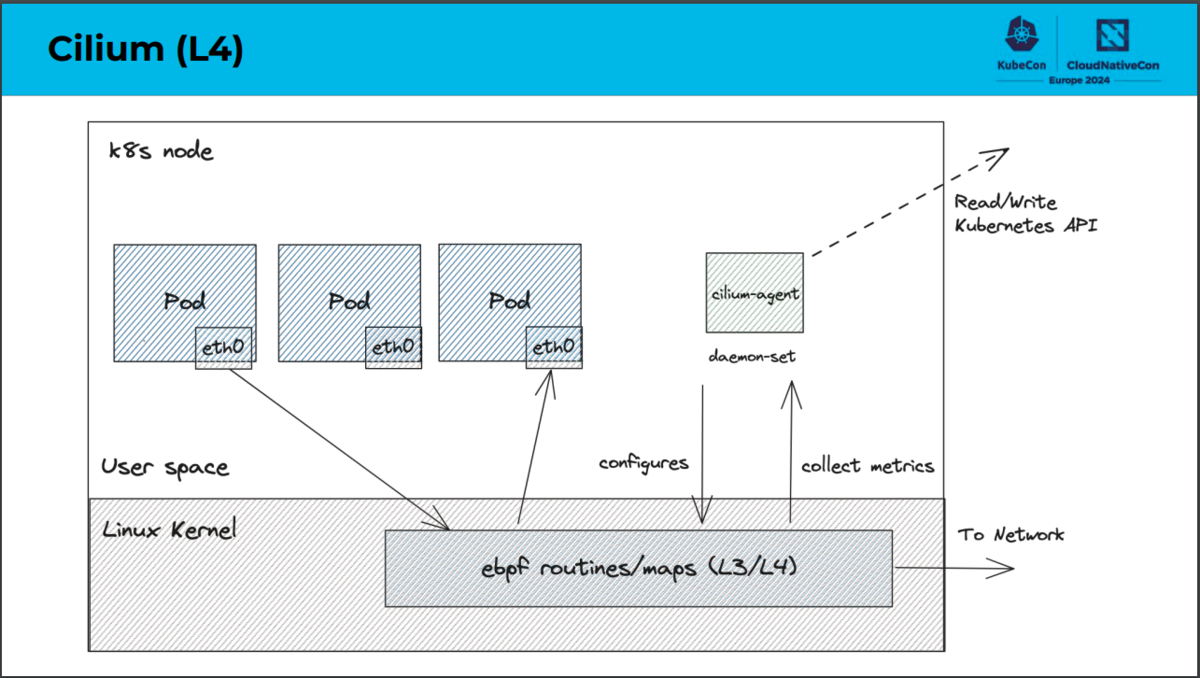
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
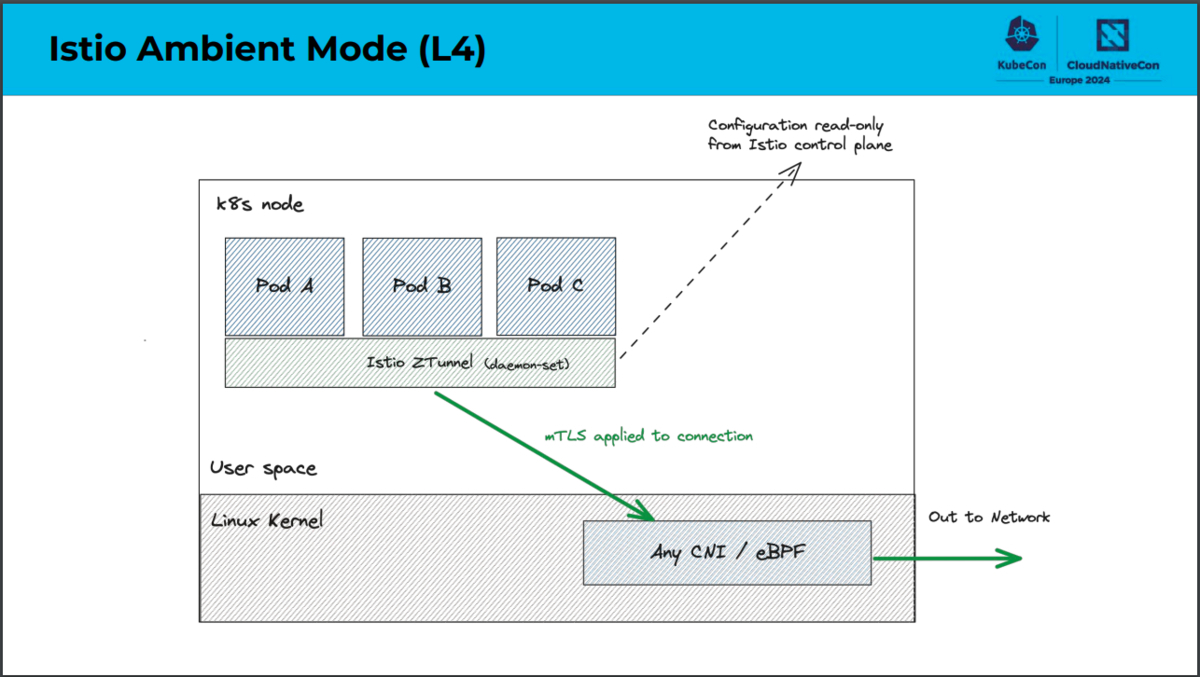
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
サービスメッシュの機能をどのネットワークレイヤで実現し、どこで実装しているのか、CiliumとIstio Ambient Meshでのそれぞれの構成の比較は次のスライドをご参照ください。
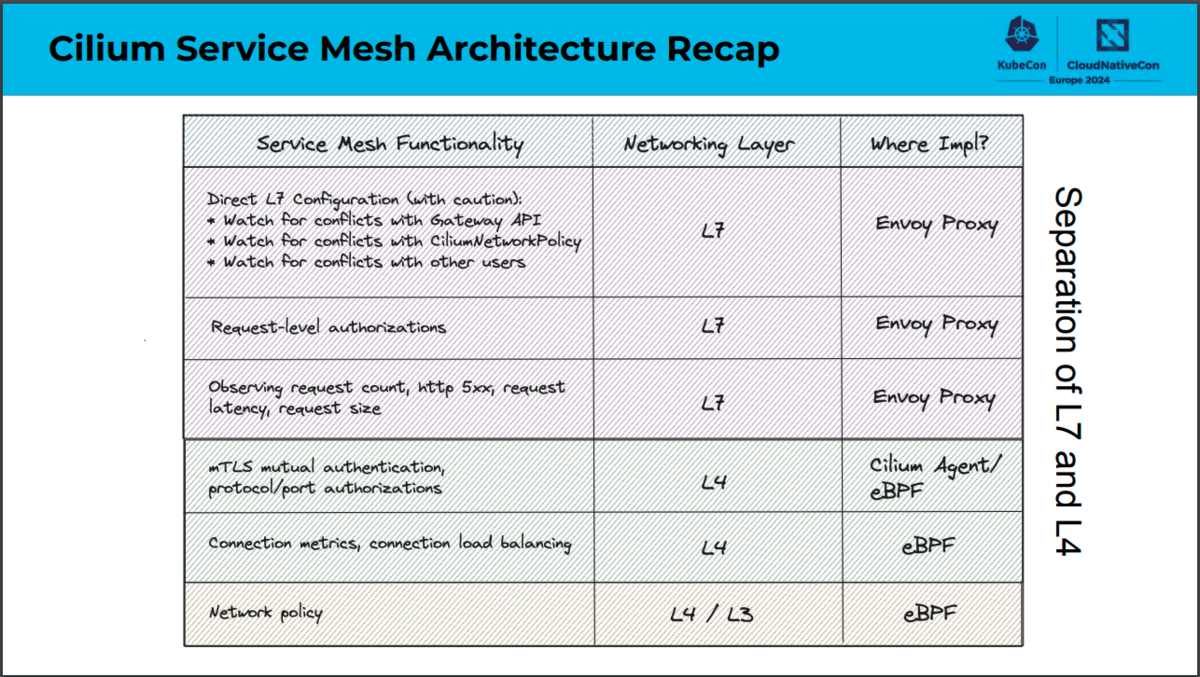
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
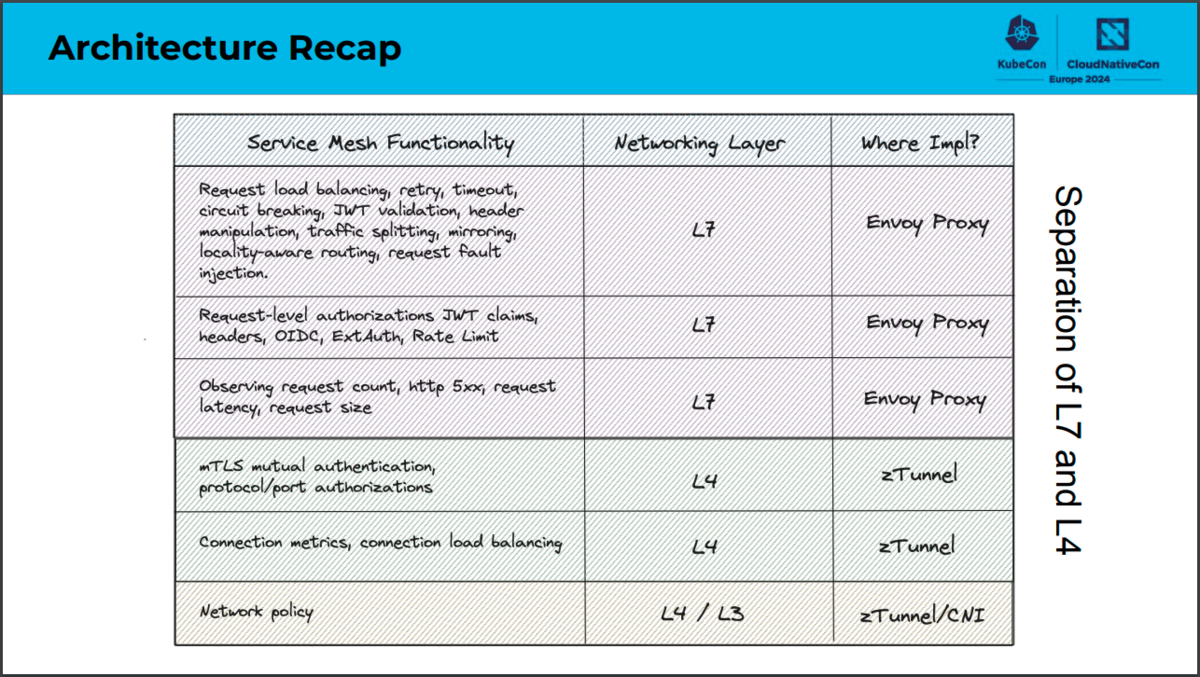
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
発表の最後の部分では、次の観点についてそれぞれのサービスメッシュ構成が適しているかそうでないかについて述べられていました。
- リソースのオーバーヘッド
- 機能の分離
- セキュリティの粒度
- 更新時の影響
これらの観点について各構成はそれぞれ次のスライドで評価されています。
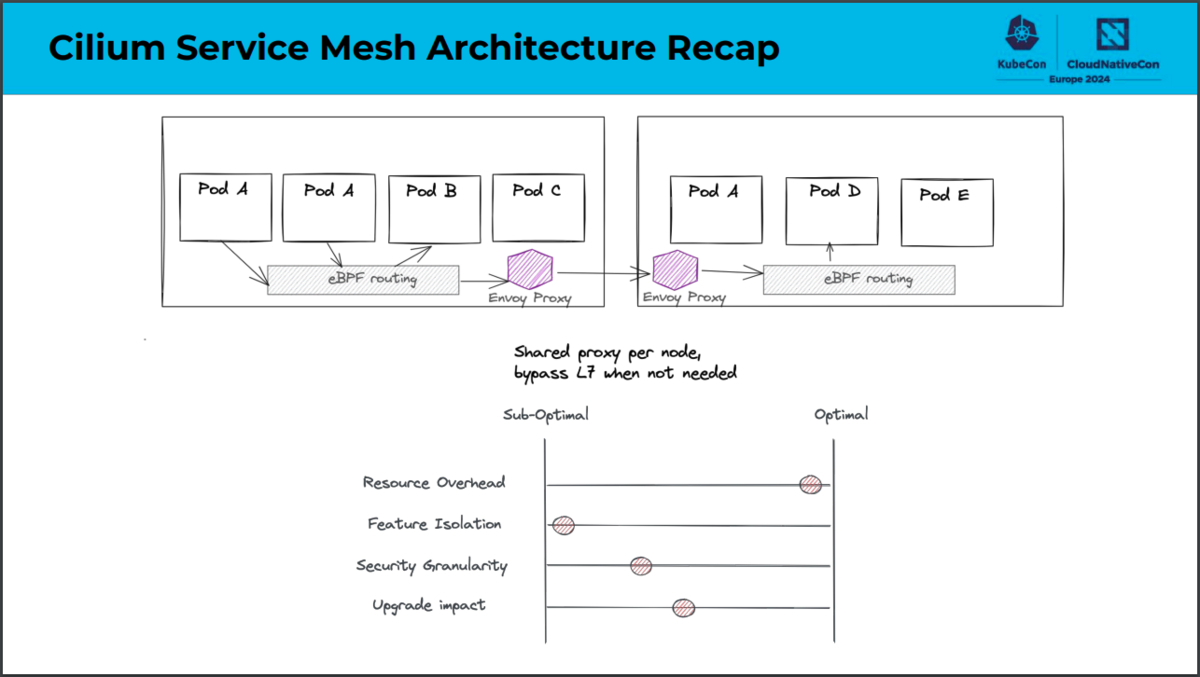
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
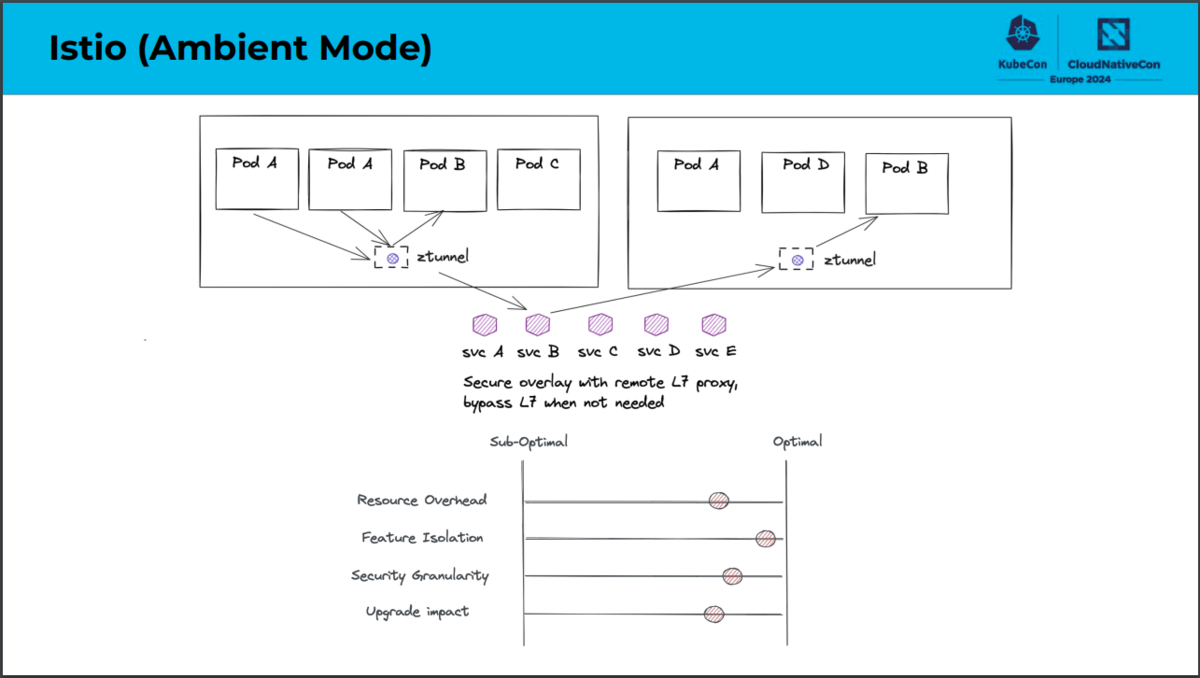
「Comparing Sidecar-less Service Mesh from Cilium and Istio」より引用
Ciliumでは特にリソースオーバーヘッドを小さくしたいケースに適しており、機能の分離という観点ではあまり適していないことがわかります。Istio Ambient Meshでは特に機能の分離という観点で適している一方で、リソースオーバーヘッドについてはCiliumでの構成にやや劣ることがわかります。このようにサイドカーレスなサービスメッシュにおいてはいくつかの構成が考えられます。またそれぞれの構成にはトレードオフがあるとわかりました。
サイドカーレスなサービスメッシュはサイドカーモデルでの課題解決のために提案されているとご紹介しましたが、サイドカーモデル自体についても日々改善されています。Kubernetesのv1.29ではSidecar Containersの機能がbetaで提供され、明示的にアプリケーションコンテナとサイドカーコンテナが区別できるようになります。これによりサイドカーモデルでのサービスメッシュでは、セッション内で挙げられていたいくつかの課題の改善が見込まれています。
今後のサービスメッシュにおいてはサイドカーモデルまたはサイドカーレス、CiliumまたはIstio Ambient Meshなどユースケースに応じてどの構成を取るべきか判断が必要だと感じました。
Future of Intelligent Cluster Ops: LLM-Azing Kubernetes Controllers
SRE部ECプラットフォーム基盤SREブロックの織田です。
1日目のKyenoteは、すべてがMLやAI、LLMに関するものでした。今回紹介するセッションもLLMを利用してマニフェストに記述したコマンドや文章を理解し、効率的に実行するLLMNETESの紹介です。
LLMNETESは、OpenAIのGPT-3を含む、複数のLLMをサポートしておりローカルのモデルもデータセットとして使用できます。また、独自のインタフェースを実装することで独自のLLMも使用できます。
次にマニフェスト例とそれらをApplyすることでどのようなことができるのか4つほど紹介します。
1つ目は、ポート80を公開したnginx Podを3台作成する例です。
spec.inputに実行したいことを記述するとそれ通りにリソースの作成などを実施できます。複雑でマニフェストの作成に時間がかかりそうな場合やPodをすぐに用意したい場合などに役立ちそうに感じました。
apiVersion: llmnetes.dev/v1alpha1 kind: CommandExec metadata: name: command1 spec: input: Create 3 nginx pods that will serve traffic on port 80.
2つ目にデプロイされているPodとDeploymentのイメージをスキャンする例です。
spec.typeにScanImages、spec.resourcesにスキャンしたいリソースを記述すると対象のリソースのイメージをスキャンできます。
CIからツールを使って定期的にスキャンする場合は、CIでツールのセットアップなどを行う必要があるため、マニフェストをApplyするだけでスキャンできるのは便利そうに感じました。
apiVersion: llmnetes.dev/v1alpha1 kind: ClusterAudit metadata: name: cluster-audit-cves spec: type: ScanImages resources: - Pods - Deployments
3つ目にカオスエンジニアリングのシミュレーションをトリガーする例です。
spec.commandに実行したいことを記述します。以下は、default namespaceのPodを削除する例となります。
apiVersion: llmnetes.dev/v1alpha1 kind: ChaosSimulation metadata: name: chaos-simulation-cr spec: level: 10 command: break my cluster networking layer (or at least try to)
最後は、クラスタ内の非推奨APIを検出する例です。
spec.typeにClusterUpgradeCheckを指定します。現在、非推奨APIを検出する方法は多く存在しますが、マニフェストをApplyするだけで検出できるのはとても魅力的に感じました。
apiVersion: llmnetes.dev/v1alpha1 kind: ClusterUpgradeCheck metadata: name: cluster-upgrade-check spec: type: ClusterUpgradeCheck
1つのツールでイメージのスキャン、カオスエンジニアリング、非推奨APIの検出など様々なことができます。そのため、実施したいことごとにツールをインストールせずシンプルな構成になることで、アップグレードなどの運用コストが下がるというメリットがありそうに思いました。
LLMNETESは、開発中でありまだ本番で利用するまでには至っていませんが、検証などを行いながら導入を検討していきたいと考えています。
Is Your Image Really Distroless? - Laurent Goderre, Docker
SRE部フロントSREブロックの三品です。
私が所属するSRE部フロントSREブロックでは、ZOZOTOWNが持つAPIの中でもクライアントに近い、frontendレイヤーのサービスを運用しており、言わばEmbedded SRE的な業務を行っています。
今回KubeCon EUに参加して私が業務の中で活かせそうだなと思ったセッションをいくつか紹介します。
このセッションでは、私たちが使っているDocker ImageはDistributionの影響を受けない状態にできていますか?と言うことを投げかけていました。
セッションの内容を説明すると、最初にDocker Imageを作成するのに必要なLinuxのDistributionやセキュリティとユーザビリティのジレンマについて説明していました。

「Is Your Image Really Distroless? - Laurent Goderre, Docker」より引用
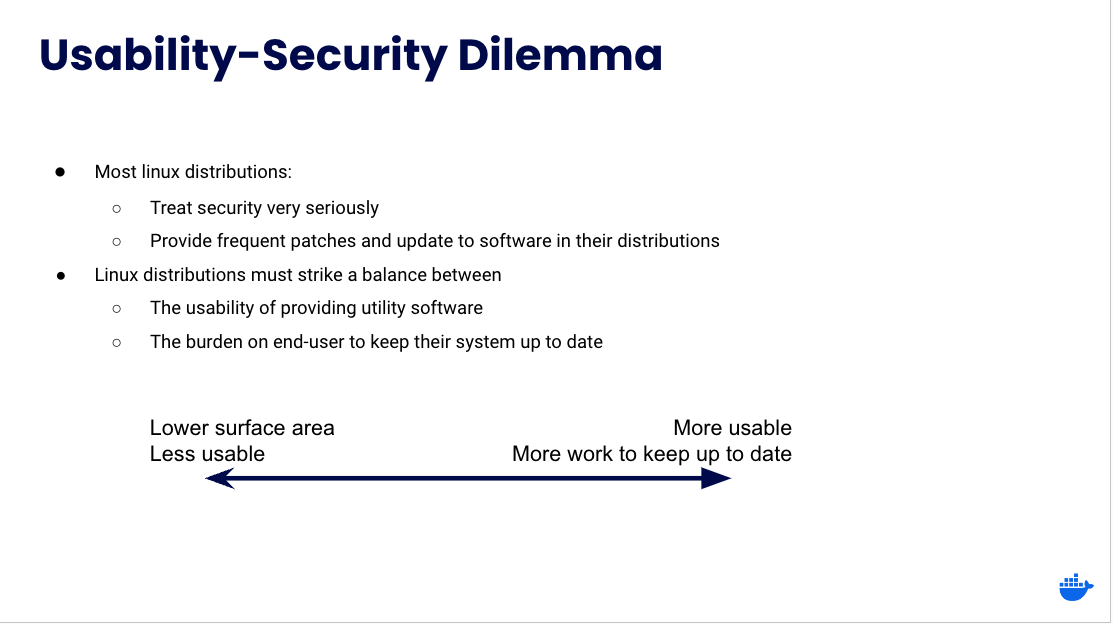
「Is Your Image Really Distroless? - Laurent Goderre, Docker」より引用
次にDistrolessなDocker Imageを生成するためDockerfileを作成しbuildするための方法やツールが説明されていました。

「Is Your Image Really Distroless? - Laurent Goderre, Docker」より引用

「Is Your Image Really Distroless? - Laurent Goderre, Docker」より引用
その後、bashなどがメインコンテナに含まれることによっての危険性を危惧し、initコンテナを利用し安全に依存関係のファイルをインストールする方法についてdemoを交えて説明していました。

「Is Your Image Really Distroless? - Laurent Goderre, Docker」より引用
私は今までDistrolessについてあまり意識を向けたことがありませんでした。
しかし、セッションを通してbashなどがメインコンテナにインストールされていることで実際にコンテナに侵入された場合の危険性について再考できました。
セッション内でinitコンテナの利便性について触れていましたが、initコンテナを利用してmainコンテナに何かを注入する処理を行うと、container起動までに追加の時間を必要とする可能性があります。セキュリティとのトレードオフになるため、initコンテナを利用する際にはこの点を考慮する必要があると感じました。
コンテナをセキュアに扱うと言う意味ですごく意味のあるものだと考えられますので、今回取り上げました。
Building Confidence in Kubernetes Controllers: Lessons Learned from Using E2e-Framework - Matteo Ruina, Datadog & Philippe Scorsolini, Upbound
このセッションでは、Kubernetesコントローラーの信頼性を高める手法としてエンドツーエンドテスト(以降、E2Eテストと呼びます。)を取り上げ、E2Eテストの基礎理念から始まって特に他社2社の実践例について取り上げていました。
本記事ではその中でも自分が個人的に気になった部分を抜粋して紹介します。
本セッションではKubernetesのE2Eテスト(e2e-framework)をベースに説明されていました。
※ e2e-frameworkとは、Kubernetesクラスター内で実行されるコンポーネントのエンドツーエンドテストを行うためのGo製フレームワークです。Kubernetesリポジトリ上にも多くのE2Eテストの例が公開されています。
その後E2Eテストのツールの特徴について述べられていました。

「Building Confidence in Kubernetes Controllers: Lessons Learned from Using E2e-Framework」より引用
日本語で翻訳すると以下のようになります。
- 採用に役立つ文書化されたフレームワーク
- 組み込みGoテストパッケージを使用する
- テストを構成するためのプログラム可能なAPIコンポーネントを提供する
- クライアントの機能を抽象化するヘルパー関数を提供する
- Kubernetesへの依存を避ける
Go E2E Test Framework for Kubernetesでも同じようなことが書かれているのでこちらもご覧ください。
次にプログラムの動きについて説明をしていました。基本的なプログラムの動きについて説明します。
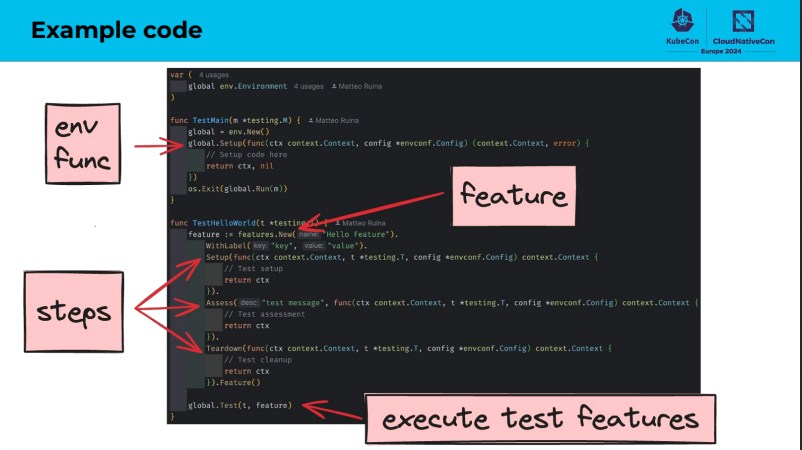
「Building Confidence in Kubernetes Controllers: Lessons Learned from Using E2e-Framework」より引用
- 環境ごとの設定情報を持つ
- 環境ごとの設定情報を元に実際のテストを紐づける
- テストの実行
DatadogやCrossplaneのE2Eテストの事例紹介ではE2Eテストフレームワークの比較や実装方法、問題点が紹介されていました。本記事ではその中でもフレームワークの比較について取り上げたいと思います。
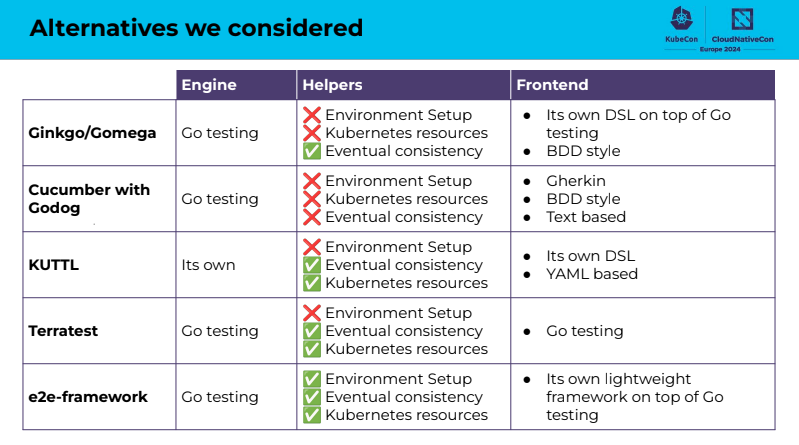
「Building Confidence in Kubernetes Controllers: Lessons Learned from Using E2e-Framework」より引用
セッションの中では、フレームワークがGoで書かれていること、そしてテストの時に環境のセットアップができると言う意味でe2e-frameworkが有効であると結論付けられていました。
セッション内では、実際にe2e-frameworkを実際に使ってみての課題感についても取り上げられていましたが、本記事ではその点については触れないので興味のある方は動画をご確認ください。
私は、Kubernetesのカスタムコントローラーを運用する業務は直接的には実施していませんが、Kubernetesの挙動を簡素化させたい時や機能をカスタムしたい時があります。そういった時にKubernetesのカスタムコントローラーは有効なので、引き続きKubernetesのE2Eテストの分野についてもウォッチしていきたいなと感じました。
現地の様子
今年のKubeCon EUはパリで開催され、日本とは全く違う景色を楽しむことができました。また、オリンピックを控えたこの時期には、オリンピックグッズを扱う店舗も見られ、オリンピックの雰囲気を肌で感じることができました。

会場のParis Expo Porte de Versaillesです。敷地内にはマクドナルドやコンビニも隣接されており、非常に行動しやすい会場でした。


会場周囲にはトラムが走っており、交通の便がよく治安も良い場所のように感じました。地元のグループによる早朝パリ観光マラソンも開催されていました。

続いては、KubeCon EUのランチです。KubeCon EUのランチでは、肉、魚、ビーガン向けの食事などが提供され、参加者の多様な食事ニーズに対して細やかな配慮が施されていました。


また、今回もCloud Native Community Japanさん主催のもと日本人交流会が実施され、各社の参加されているエンジニアの方々と意見交換ができとても楽しい時間を過ごすことができました。

ブースについて
KubeCon EUはCloudNativeConと同時に開催されKubernetesをはじめとする様々なOSSプロジェクトのブースや企業ブースがあり、それらのプロジェクトに参加するメンテナーと身近に話せる機会でもあります。
実際に我々も社内で利用するOSSプロジェクトのブースに出向き機能要望や意見交換を実施できました。
KubeCon EUはOSSプロジェクトのメンテナーとの距離が近く議論できる機会になるなと感じました。


参加に向けてのTips
できるだけ早めに準備する
参加の可否をできるだけ早く決めて、一刻も早く動くことで自由度が広がります。
KubeCon EUのチケットは早い時期に買うほど大幅に割引が効くため、参加コストを大きく抑えられます。
例えば、2023年11月28日までにチケットを購入していた場合$1149で参加できました。しかし、2024年3月17日以降にチケットを購入すると$2229となっておりほぼ倍の金額となっていました。
とくに宿泊する宿については、時間が経つにつれて条件の良い宿が埋まっていくため早めに準備することで現地での移動を便利にできます。
時差ボケに備える
フランスは日本と比べて8時間遅く時間が進みます。フランスの朝8時は日本では深夜のため、朝起きることは簡単でもセッションが進むにつれて眠たくなる状態でした。
そのため意識的に睡眠を取って体内時間をずらす必要がありました。
質問を用意しておく
セッション終了後には質疑応答が用意されていることが多く、登壇者との交流の機会でもあるため、セッションの内容を予習しておき疑問点をまとめておくとより有意義な参加になります。
最後に
今年からKubeCon EUはオフライン形式で統一され、会場は活気にあふれていました。
今回はKubeCon経験者(NAも含む)からKubeCon初参加者まで、幅広いメンバーで参加しましたがオープンソースプロジェクトのメンテナーや発表者との距離が近かったため、Kubernetesおよび、その関連エコシステムについての深い学びを得ることができました。
ZOZOでは一緒に働くエンジニアを募集しています。また、KubernetesやCloudNativeが大好きなエンジニアも大歓迎です。ぜひご応募ください。