



はじめに
こんにちは、推薦基盤ブロック、新卒1年目の住安宏介です。普段は推薦システムの開発・運用を担当しています。
2024年6月に開催されたコンピュータビジョン・パターン認識分野において世界最高峰の国際会議の1つであるCVPR(Conference on Computer Vision and Pattern Recognition)2024に参加しました。参加レポートとして発表内容や参加した感想を紹介いたします。また、最後にZOZO NEXTが行っているワークショップのスポンサー活動についてZOZO Researchの清水から紹介いたします。
目次
- はじめに
- 目次
- CVPR とは
- 開催地のシアトルについて
- 学会のスケジュール
- 企業展示ブースの様子
- ポスターセッションの雰囲気
- 採択数増加に伴うポスターセッションの懸念とその実際
- 特に、印象に残った研究発表
- SLICE: Stabilized LIME for Consistent Explanations for Image Classification [Highlight]
- CAM Back Again: Large Kernel CNNs from a Weakly Supervised Object Localization Perspective
- Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods [Award Candidate]
- Learning to Rank Patches for Unbiased Image Redundancy Reduction
- Identifying Important Group of Pixels using Interactions
- CVFAD におけるスポンサーの取り組み
- さいごに
CVPR とは
先述の通り、CVPRはコンピュータビジョン・パターン認識分野における世界最高峰の国際会議の1つです。近年、CVPRはそのプレゼンスを大きく高めており、採択された論文の影響力も著しく向上しています。Google Scholarのh5-indexによる全分野の学術誌・国際会議のランキングで、Nature、New England Journal of Medicine、Scienceに次いで4位にランクインしています。このことは、CVPRにおける研究成果が、量だけでなく質においても非常に高く評価されていることを示しています。CVPRは、そのプレゼンスの高まりとともに、コンピュータビジョンとパターン認識の分野における最新の研究成果を発表する場として、世界中の研究者や開発者から高い注目を集めています。
開催地のシアトルについて
開催地となったシアトルは、美しい自然環境に恵まれた都市として有名です。例えば、日本で人気のコーヒーの名前の由来となったマウント・レーニアや、ユネスコ世界遺産に登録されているオリンピック国立公園があります。また、シアトルは世界的に有名なテック企業が集まる都市でもあります。そのため、CVPRに参加された研究者の間では、これらの企業のオフィスツアーに参加する動きも見られ、活発な交流が行われていました。


学会のスケジュール
学会のスケジュールは以下のように構成されています。
- 1日目から2日目
- ワークショップ
- チュートリアル
- 3日目から5日目(本会議)
- キーノート
- パネルディスカッション
- オーラル発表
- ポスター発表
- 企業展示
- AIアートギャラリー
この中で特に興味深かった企業展示ブースの様子、ポスターセッションの雰囲気、そして私が予期していた採択数増加に伴うポスターセッションの懸念とその実際について紹介します。
企業展示ブースの様子
企業展示ブースでは、各会社が最新の研究成果や実際の活用事例を紹介していました。50を超える企業が参加しており、どのブースも大変賑わっていました。また、展示内容も非常に興味深くワクワクするものばかりで、とても楽しい時間を過ごせました。特に興味深かったのはZooxの無人運転車両です。この車両は運転席が不要であるため、興味深いことに座席が対面で配置されていました。私はペーパードライバーであるため、導入されることを楽しみに待っています。


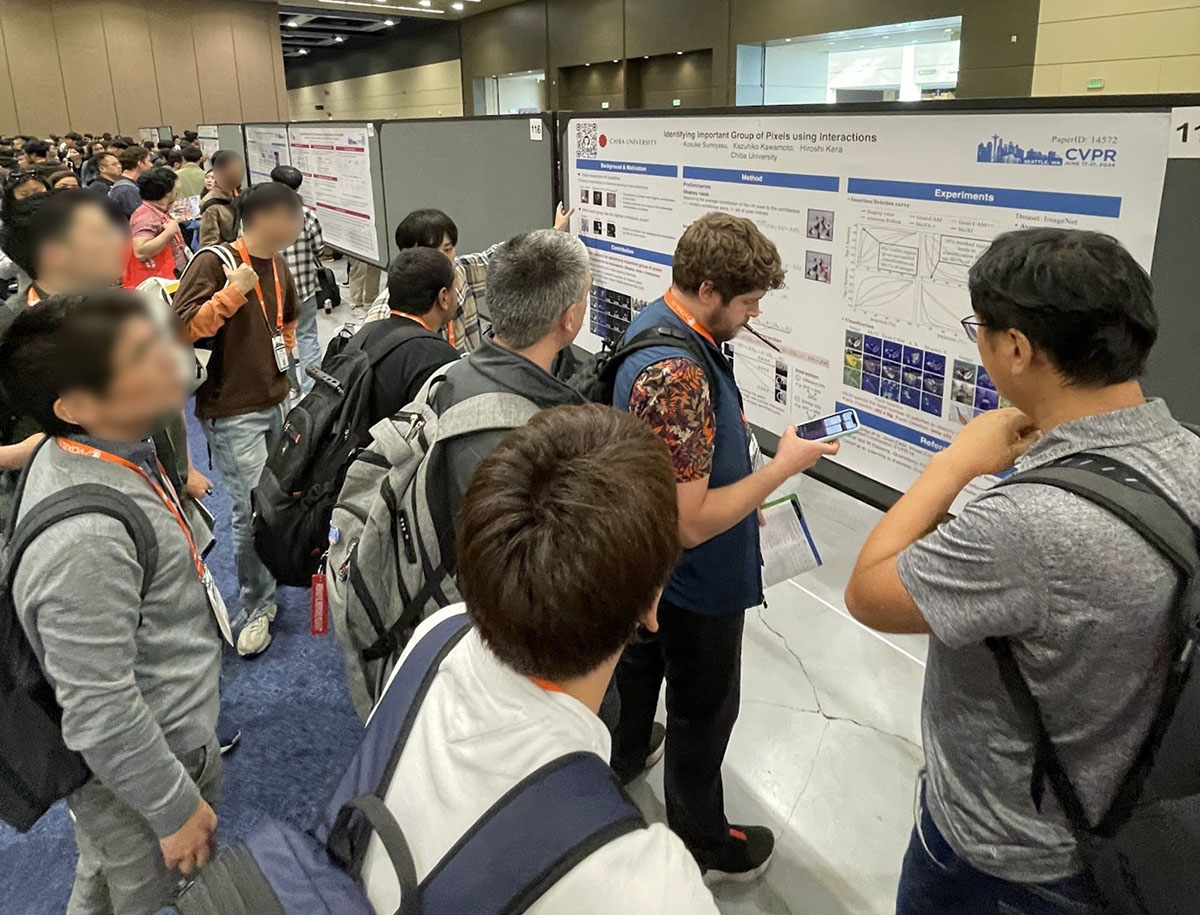
ポスターセッションの雰囲気
ポスターセッションとは、発表者が研究内容をポスター形式で展示し、聴講者と直接対話しながら説明と議論をする発表形式です。最も権威のある国際会議の1つであるため、参加者の熱気がとても感じられました。また、発表された研究の多くが魅力的であり、一人の発表者に多くの聴講者が集まる場面も多々見られました。多数の聴講者に対応するため、チームで発表するケースも見られました。
国内の学会では最初から最後まで説明し終えた後に質問を受ける流れが多いですが、今回は概要を話してから適宜聴講者の質問を元に会話するという形が主流でした。私もこの形で大学院時代の研究内容を発表しました。
採択数増加に伴うポスターセッションの懸念とその実際
本会議での論文採択数は年々増加しており、すべての興味のある論文を把握しきれない、またはすべての興味のあるポスターを聴講できない可能性が懸念されました。今年のポスターセッションは各90分で、約450件のポスターが展示されていたため、単純計算で1つのポスターにかけられる時間は約12秒しかありません。このため、事前に聴講するポスターを決めておくなどの工夫が必要でした。
しかし、この懸念にもかかわらず、ポスターセッションは予想以上に効率よく回れました。その理由の1つに、CVPRが提供する採択論文の推薦システムを活用することで、事前に興味のある論文を特定できたことが挙げられます。このシステムにより、興味のある論文を事前にチェックするのが非常に容易になりました。
また、興味のあるポスターが会場内で分散していると移動や探索が大変になる可能性がありました。ですが、分野ごとにポスターが配置されていたため、関連する研究を効率的に回れ、思ったよりも負担ではありませんでした。実際に、私はセッション内で大体6から9件ほどの研究を聴講でき、満足感が高かったです。

特に、印象に残った研究発表
以上では、会議中の様子を紹介しました。ここからは、私が興味を持っているコンピュータビジョン分野の深層学習モデルの説明可能性について紹介いたします。
SLICE: Stabilized LIME for Consistent Explanations for Image Classification [Highlight]
Revoti Prasad Bora、Kiran Raja、Philipp Terhörst、Raymond Veldhuis、Raghavendra Ramachandra
深層学習モデルの説明可能性を高めるための有名な手法の1つとして、LIME(Local Interpretable Model-agnostic Explanations)という手法があります。LIMEとは、Deep Neural Networkなどの複雑なモデルを線形モデルのような簡単なモデルで局所的に近似することによって、各特徴量の貢献度を測定します。しかし、LIMEの説明には一貫性がないという問題があります。例えば、同じ入力データに対してLIMEを複数回適用した場合でも、適用ごとに特徴量の貢献度のランキングが異なったり、貢献度の符号の正負が逆転したりすることがあります。
この論文では、LIMEの手法を改善し、一貫した説明を提供できるように、SLICE(Stabilized LIME for Consistent Explanations)という手法を提案しました。この手法では、LIMEの説明において貢献度が正と負に変動する特徴を除去することにより、説明の安定性を向上させています。具体的には、符号エントロピーに基づいて不安定な特徴を特定し、それらを除去することで、一貫性のある貢献度を求めています。
結果を見ると、このSLICEという手法は平均実行時間が通常のLIMEの約4倍かかります。LIMEより安定した説明ができるため、今後の説明手法の選択肢の1つになると考えています。
CAM Back Again: Large Kernel CNNs from a Weakly Supervised Object Localization Perspective
Shunsuke Yasuki、Masato Taki
近年、CNN(Convolutional Neural Network)の性能向上を目指してカーネルサイズを拡大したラージカーネルCNNが注目されています。先行研究による分析では、性能向上の理由としてCNNのカーネルサイズの拡大により、CNNが広範囲の特徴から情報を集めるようになり、そのような有効受容野の拡大が原因だと述べられていました。
この研究では、実際にラージカーネルCNNの性能向上の理由が有効受容野の拡大であるのか検証し、その妥当性を弱教師ありオブジェクトローカリゼーション(WSOL)の観点から網羅的に評価しました。実験結果から、ラージカーネルCNNの精度向上の理由が有効受容野の拡大だけで説明することは難しいことがわかりました。代わりに、著者らはその理由として、特徴マップの改善が原因であることを示唆しました。具体的には、古典的なモデルの判断根拠の可視化手法のCAM(Class Activation Mapping)を使用して通常のCNNとラージカーネルCNNを比較していました。その結果、通常のCNNは局所領域のみを活性化するのに対し、ラージカーネルCNNはオブジェクト全体を活性化することがわかりました。さらに、この傾向を活かしラージカーネルCNNとCAMを単純に組み合わせた手法でWSOLの精度を検証した結果、複雑な構成を持つ最先端のCNNベースのWSOL手法に匹敵する性能を持つことを示しました。
個人的には、古典的な可視化手法であるCAMが、最新のCNNの性能向上の理由を説明していることから、同様に他の説明手法を最新のCNNやViT(Vision Transformer)に対して適用した際に新たな説明が得られるのかが気になります。
Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods [Award Candidate]
Mingqi Jiang、Saeed Khorram、Li Fuxin
多くの研究で、TransformerとCNNの判断根拠の違いが議論されています。特に、TransformerはCNNよりも形状に着目して判断するという知見があります。この研究では、そのような新たな知見を得るために「sub-explanation counting」と「cross-testing」と呼ばれる評価指標を提案しました。
1つ目の指標のsub-explanation countingは、モデルが画像内の複数の画像パッチを構成的に見て判断しているのか、それとも一部の重要な画像パッチに強く依存しているのかを調べる手法です。まず、MSEs(Minimally Sufficient Explanations)と呼ばれる、完全な画像と同程度の予測確率を持つ最小限の画像パッチセットを取得します。次にそのMSEsの一部の画像パッチを削除して予測確率を計算し、完全な画像の予測確率との尤度比を求めます。もし、尤度比が高ければ、その画像パッチの組み合わせが重要であり、モデルは複数の画像パッチを同時に着目しているため「構成的」と判断されます。逆に、重要な画像パッチを削除すると予測結果が大きく変わるものを「分離的」と判断されます。この手法によると、Transformerは構成的であり、CNNは分離的であることが示されていました。
2つ目の指標のcross-testingは、モデル間の判断根拠の類似性を評価するための指標です。もし、2つのモデルが同様の視覚的特徴に依存している場合、cross-testingの高いスコアを獲得します。その結果、類似したタイプのアーキテクチャや学習法のモデルでは、予測に使用する特徴が似ていることが確かめられていました。
個人的には、実際にアプリケーションに応用する際には、どちらかのアーキテクチャのモデルがベースとなるのか、それともケースバイケースでアーキテクチャを使い分けるべきかが気になります。
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Yang Luo、Zhineng Chen、Peng Zhou、Zuxuan Wu、Xieping Gao、Yu-Gang Jiang
深層学習モデルの説明可能性の文脈ではないのですが、類似した研究の方向性として冗長な情報の削減というものがあり、興味深い考え方をしていたので紹介いたします。画像において、近くにあるピクセルがしばしば似た色や明るさを持つことがあり、このような類似した情報を冗長な情報といいます。推論の高速化や効果的な伝送のためには、この冗長性を削減することが重要です。
この研究は、冗長な情報を削減するためにMAE(Masked Auto Encoder)を用いた自己教師あり学習フレームワークLTRP(Learning to Rank Patches)を提案しました。MAEとは、画像パッチをマスクした入力に対して元の入力画像を出力するように再構成することで特徴表現を学習する手法です。この手法は、画像再構成の難易度に差を持つことを知られています。例えば、犬の胴体をマスクしても元々の犬とほとんど同様な再構成は容易ですが、尻尾をマスクすると再構成は難しくなることがあります。著者らはこのような難易度の差に目をつけ、その画像パッチの情報量を測定する指標として再構成の難易度を使用しました。つまり、再構成が難しい画像パッチは重要な情報を含むと考えられ、再構成が容易な画像パッチは冗長な情報と見なすということです。LTRPの具体的な手法は、まず事前学習されたMAEを利用して画像パッチの擬似スコア(再構成画像の崩れ具合のスコア)を生成します。そして、このスコアを疑似ラベルとした教師データにより、各パッチの重要度のランク付けを推論する代理モデルを学習します。この代理モデルにより、任意の入力画像に対し重要な画像パッチを特定でき、特定されなかった画像パッチは冗長な情報として削減できます。
再構成が難しいというネガティブな要素に直面した場合、それを改善する方向で研究が行われると思うのですが、それに情報量を結びつけることでポジティブな効果を生み出そうとした発想がとても興味深いと思いました。
Identifying Important Group of Pixels using Interactions
Kosuke Sumiyasu、Kazuhiko Kawamoto、Hiroshi Kera
私が発表した論文を簡単に紹介したいと思います。
画像分類モデルの振る舞いを理解するために、画像内のピクセルが推論に与える影響を貢献度として測定し、可視化することがよく行われています。既存の手法であるGradCAMやAttention rolloutでは、画像内の各ピクセルが推論に与える影響を測定して可視化しています。しかし、貢献度の高いピクセルを集めたピクセル群が必ずしも高い貢献度を持たないことがあります。例えば、海辺にいる鴨の画像分類を考えると、単純には主に鴨の部分にフォーカスすれば良いと考えられます。ですが、鴨は海の上に生息する傾向があるため、背景に写っている海辺の情報を鳥の情報と一緒にモデルに入力した方が分類を補助するために役立つ可能性が高いことが考えられます。実際に従来手法では、鴨の体や嘴といった情報のみを集めていたのですが、確信度が低く、一方で鴨の体だけでなく海などの情報も含めた方がより高い確信度を持つことがわかりました。
この研究では、モデルにピクセル群を入力したときに推論へ大きく影響を与えるピクセル群を特定する手法MoXI(Model eXplanation by Interactions)を提案しています。具体的には、ゲーム理論で用いられるShapley Valueと相互作用値という2つの量を計算することで、個々のピクセルの貢献度に加えて、ピクセル間の協調による貢献度を考慮できる手法となっています。
CVFAD におけるスポンサーの取り組み
ZOZO Researchの清水良太郎です。最後に、CVPRで毎年開催されているファッションやアートに関するワークショップ Workshop on Computer Vision for Fashion, Art, and Design(CVFAD)について紹介いたします。CVFADは今年で7回目の開催であり、毎年様々な大学や企業からファッション関連の最新の研究が発表されています。
ファッション関連のAI技術の研究者にとっては毎年欠かすことのできないイベントであり、ZOZO NEXTも今年はスポンサーとして関わりました。今年の採択率は38%と、ワークショップながら厳しい査読プロセスを経て、8件の研究が発表されました。なお、採択された論文は、毎年CVPR WorkshopsのProceedingsに掲載されています。
私個人としても、今年は「A Fashion Item Recommendation Model in Hyperbolic Space」が採択され、現地で発表してきました。この研究は、画像情報を用いた推薦モデルの学習に、双曲空間における距離尺度を導入し、優れた精度を達成したという内容です。双曲空間は、我々の生活しているユークリッド空間と呼ばれる平坦な空間と異なり、曲がった空間の一種です。原点から離れるほど空間が広くなるという特徴から、階層的な構造を有したデータの埋め込みと相性が良いとされています。推薦のデータにおいては、わかりやすい階層構造だけでも、例えばユーザとアイテム。また、アイテム間の人気度から生じる階層構造が存在します。

本研究では、双曲空間においてファッション画像特徴量を用いた推薦モデルを学習し、その精度や学習されたユーザ・アイテム空間に関する多角的な考察をしました。詳しくは、論文をご一読いただけると幸いです。
CVPRはコンピュータビジョン・パターン認識分野において世界最高峰の国際会議であるため、そのワークショップに対する採択の難易度も年々向上しております。特に、一部のワークショップは、一流の国際会議やジャーナルに匹敵するような評価を受けています。実際にGoogle Scholarが発表しているh5-indexを基準にしたランキングでは、(2024年7月5日現在)Computer Vision & Pattern Recognition分野の全学術誌・国際会議を通して7番目の評価をされています。会社の企業理念である「世界中をカッコよく、世界中に笑顔を」を叶えるべく、世界中のファッションに関わるAI研究者や技術者から認知をしてもらうことはとても重要な一歩です。このような場で継続的に研究成果を発表するだけでなく、スポンサー企業として積極的に参加することにより、ZOZO/ZOZO NEXTのプレゼンスの向上に大きく貢献すると考えています。
さいごに
今回は、CVPRに参加した感想や内容の一片をお伝えしました。特に経験して良かったことは、トップ層の研究者や開発者たちが持つ知的好奇心の強さと行動力を直接感じることができたことです。このような熱意に触れられたことは、将来の糧になると感じています。ここで得られた知見や経験を今後の開発に取り入れ、より良いサービス開発をしていきたいと思っています。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。