




はじめまして、ECプラットフォーム部 API基盤チームに2021年新卒入社した山添です。普段はAPI GatewayやID基盤の開発に携わっています。
データベースを運用していると、ビジネスロジックの変更やクエリ最適化のためにデータベーススキーマを変更することがあります。その際にデータベースマイグレーションツールを使うことで、運用の過程で変更されるスキーマの管理を楽にできます。
しかし、データベースマイグレーションツールであるsqldefが便利なのですが、弊社で使われているSQL Serverには対応していませんでした。そのため、何かしらの対策が必要でした。
本記事では、それらに関連した以下の内容を紹介します。
- データベースマイグレーションツールとしてsqldefを採用していること
- sqldefでSQL Serverサポートをするためにコントリビュートしていること
- sqldefの開発のために必要な基礎知識と具体的な実装について
目次
前提知識
はじめに、本記事で扱うデータベースマイグレーションとマイグレーションツールについて紹介します。ご存じの方は、sqldefを採用した背景の章からご覧ください。
データベースマイグレーション
アプリケーションの変更に伴い、データベースのスキーマ情報の変更を必要とする場合があります。例えば以下のケースです。
- 新機能の実装に必要となるカラムを追加したい
- ビジネスロジックの変更に伴いカラムの制約を変更したい
- パフォーマンスチューニングのためにインデックスを追加したい
データベースに保存されているデータを保持したままスキーマ情報を変更することをデータベースマイグレーションと呼びます。そのデータベースマイグレーションにより、仕様変更や機能追加でスキーマ情報の変更が発生しても柔軟に適応できます。しかし、環境ごとのスキーマ管理や更新のためのDDL文を実行する手間など、新たな課題が浮上します。
データベースマイグレーションツール
上記の課題を解決する手段の1つとして、データベースマイグレーションツールがあります。データベースマイグレーションツールは、スキーマ情報の変更に伴うDDL文の実行を管理するためのツールです。
多くのデータベースマイグレーションツールは、現時点と最新のスキーマ情報の差分から実行が必要なDDL文だけを実行してくれます。そのため、開発環境や本番環境ごとにスキーマ情報を管理し、更新に必要なDDL文を1つ1つ手動で実行するという手間を省くことができます。
また、データベースマイグレーションツールは、アプリケーションフレームワークに組み込まれているものから独立したツールとして実行可能なものなど、様々な選択肢が存在します。本記事では現在弊社で採用しているFlyway、sqldefの2つを紹介します。この2つはどちらも独立したツールとして実行可能です。
Flyway
FlywayはJava製のデータベースマイグレーションツールです。Apache License 2.0で配布されているコミュニティ版と有償のチーム版が存在しており、サポートや機能に違いがあります。 flywaydb.org
Flywayの特徴は、利用における選択肢の多さです。更新操作の記述はDDL文またはJavaコードが選択できます。実行方法はコマンドラインクライアント、Java APIやMaven plugin、Gradle pluginが用意されています。特にマイグレーション可能なデータベースの数は群を抜いています。詳しくはこちらをご覧ください。
また、Flywayはファイル名でスキーマ情報のバージョン管理を行い、必要な更新操作を検出して実行します。そのため、現在のデータベースを更新するために「どのDDL文を実行する必要があるのか」を考える必要がありません。データベースマイグレーションに必要な作業は、データベースを任意のバージョンから次のバージョンに移行するためのDDL文を定義するだけです。
例えば、以下のDDL文で定義したテーブルがあるとします。
-- ファイル名:V1_20210901_create_users.sql CREATE TABLE users ( id BIGINT PRIMARY KEY, name VARCHAR(20) )
このテーブルにemailカラムを追加したい場合は、以下の様なDDL文を新たなマイグレーションファイルに定義してFlywayを実行します。そうすることで、Flywayが未実行のマイグレーションファイルを検出し実行してくれます。
-- ファイル名:V1_20210903_add_email.sql ALTER TABLE users ADD email VARCHAR(100) NOT NULL
また、コミュニティ版とチーム版の一番大きな違いは、各種データベースのサポート期間です。コミュニティ版ではデータベースの特定のバージョンがリリースされてから5年がサポート対象期間ですが、チーム版ではサポート期間が10年になります。例えば、データベースにSQL Server 2017を利用している場合、コミュニティ版のサポート期間は2022年までです。
sqldef
sqldefはGo言語製のデータベースマイグレーションツールで、MITライセンスで配布されています。 github.com
Go言語製のツールなので、ビルドしたバイナリから実行できます。2021年9月時点でサポートしているデータベースはMySQL、PostgreSQL、SQLite3、SQL Serverです。各データベースごとにサポートしている機能が異なるので、詳しくはこちらをご覧ください。
sqldefの特徴は、更新操作の定義が必要ない点です。多くのデータベースマイグレーションツールでは、ALTER TABLE ...などの更新操作を定義し、データベースのマイグレーションとバージョン管理を実現します。しかし、sqldefでは最新のスキーマ情報を定義したDDL文さえあれば、自動的に必要な更新操作を生成し実行してくれます。バージョン管理はGitなど他のツールに任せることで、更新操作を実行する度にファイルが増えていき管理が煩雑になるのを防ぐことができます。
Flywayの例と同様に、以下の定義をしたテーブルがあるとします。
CREATE TABLE users ( id BIGINT PRIMARY KEY, name VARCHAR(20) )
このテーブルにemailカラムを追加したい場合は、上記のファイルを以下の様に編集します。
CREATE TABLE users ( id BIGINT PRIMARY KEY, name VARCHAR(20), email VARCHAR(100) NOT NULL )
このDDL文を使ってsqldefを実行することで、自動でALTER TABLE users ADD email ...文を生成し、実行してくれます。
sqldefを利用する際には、Flywayと比較してサポートしているデータベースが少ない点に注意が必要です。また、基本的なDDL構文はサポートされていますが、サポートされていない構文を使いたい場合は適宜修正が必要です。
sqldefを採用した背景
チーム内で採用するマイグレーションツールを検討した結果、以下の3点からsqldefを高く評価しました。
- マイグレーションファイルの管理から解放される
- バイナリだけで動かせるため、Flywayと比較して実行が容易である1
- 機能がシンプルなため、自分たちの手でメンテナンスが可能である
ところが、弊社ではMySQLとSQL Serverをメインで使っていますが、マイグレーションツールを検討していた2021年6月時点でsqldefはSQL Serverに対応していませんでした。それでも、sqldefは魅力的であり、最終的に自分たちでsqldefにコントリビュートしてSQL Server対応をしていくという決断を下しました。
その後、コントリビュートの成果として、2021年9月時点でSQL Serverでも以下のDDL文がsqldefによって生成できるよう対応が進みました。
Table: CREATE TABLE, DROP TABLE Column: ADD COLUMN, DROP COLUMN, DROP CONSTRAINT Index: ADD INDEX, DROP INDEX Primary key: ADD PRIMARY KEY, DROP PRIMARY KEY VIEW: CREATE VIEW, DROP VIEW
以降の章では、SQL Serverサポートを進める上で得られたsqldefの開発に必要な知識から実装までの流れを紹介します。
sqldefと言語アプリケーション
本章では、sqldefがどの様にマイグレーションを実現しているのか、全体像とそれを実現するための基礎知識を紹介します。sqldefの全体像から内部実装を知ることで、現在サポートされていないSQL構文を管理したくなった際に、自分でサポート構文の追加をしたりbugfixをするのに役立ちます。
sqldefの処理の流れ
sqldefでデータベースマイグレーションを実行すると、以下の順序で処理が実行されます。
- 既存のデータベースからDDL文を書き出す
- 1.で書き出されたDDL文と新しいDDL文を構文解析し、それぞれの抽象構文木を生成する
- 2つの抽象構文木を比較し、実行すべき更新操作のDDL文を生成する
- 生成されたDDL文を実行する
上記の処理を図にまとめると以下の様になります。
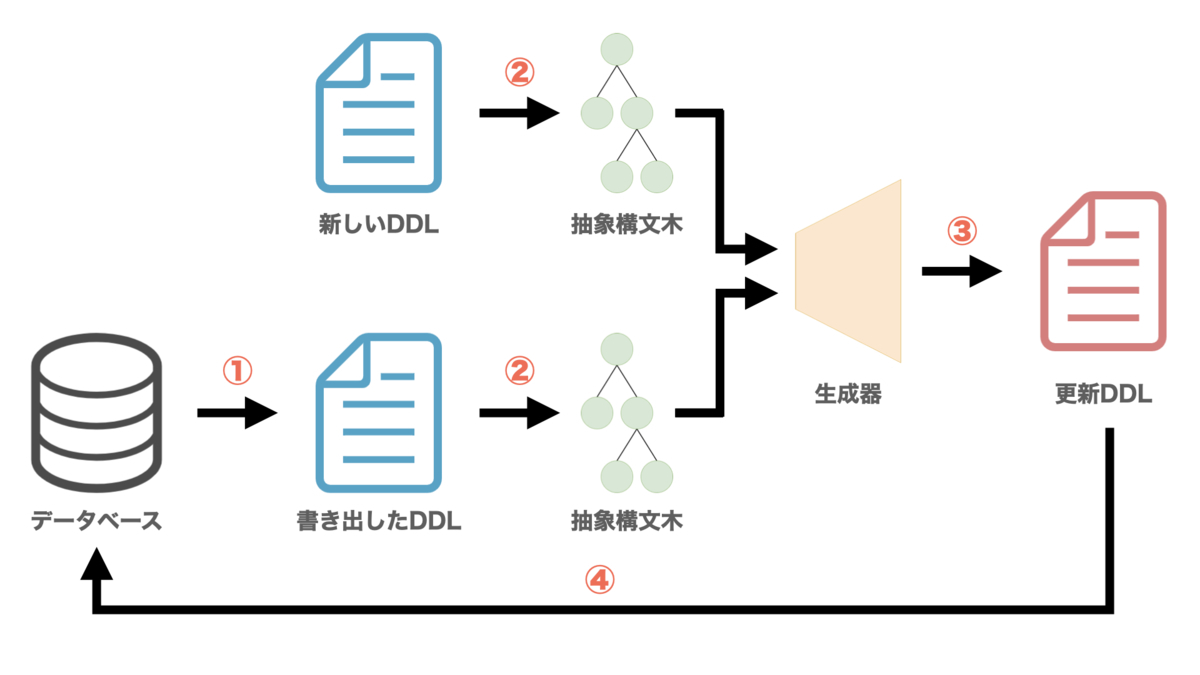
この様に、文字列を構文解析して何らかの処理を実行するツールを「言語アプリケーション」と呼びます2。代表的な言語アプリケーションにはインタプリタやコンパイラがあげられます。
言語アプリケーションは汎用性が高いツールです。言語アプリケーションの開発手法を学ぶことで、デバッグツールや静的解析ツール、言語翻訳ツールなど開発・運用効率を向上するツールの開発ができる様になります。次の節では、sqldefの実装に必要な言語アプリケーションの基礎要素の知識を紹介します。
言語アプリケーションの基礎要素
この節では言語アプリケーションの開発に必要な基礎要素として字句解析器、構文解析器、抽象構文木を説明します。これらの基礎要素は数ある言語アプリケーションに共通して使われる要素であり、インタプリタやコンパイラの実装にも必要な要素です。sqldefでも中心に添えられている要素なので、これらの仕組みを知ることがsqldefの実装の理解に役立ちます。
字句解析器
字句解析器は、与えられた文字列を事前に定義したトークンの配列に変換する字句解析と呼ばれる処理をします。
そして、字句解析器はlexer、tokenizer、scannerなど様々な呼び方をされることがありますが、sqldefではtokenizerとして実装されています。トークンとは、解析する対象言語の文法中で1つの単位として扱うことができるものを指します。字句解析器は識別子(テーブル名など)や整数値の様に意味値を持つトークンに対しては、トークン型に加えて値の情報も出力します。DDL文の場合、トークンは文字列を空白によって分割した単語単位で表現されます。例えば、CREATEやTABLEの他、(や識別子、整数値が1つのトークンとして定義され、トークン型が識別子や整数値の場合は、「users」や「10」の様な値も加えて出力します。
以下の様なDDL文を字句解析した場合を例にあげます。
CREATE TABLE users (name CHAR(10))
この場合、字句解析器には以下の様なトークン列を出力されることが期待されます。
[
CREATE,
TABLE,
IDENTIFIER("users"),
LPAREN,
IDENTIFIER("name"),
CHAR,
LPAREN,
INTEGER(10),
RPAREN,
RPAREN,
SEMICOLON
]
sqldefではgoyaccというパーサージェネレータが使われています。パーサージェネレータについては後述しますが、構文解析器を自動生成するためのツールです。パーサージェネレータにgoyaccを使う場合、goyaccに定められた仕様で字句解析器を実装しなければなりません。 pkg.go.dev
goyaccで使える字句解析器は以下のインタフェースで定義されています。
type yyLexer interface { Lex(lval *yySymType) int Error(e string) }
Lexが字句解析の処理ですが、引数として受け取ったlvalにトークンの意味値を入れ、トークンの種類をint型で返す様に実装します。このインタフェースを満たす様に字句解析器を実装した場合、上記のDDL文を入力した際のlvalと戻り値は以下の様に遷移することが期待されます。
type tokenType int const ( CREATE tokenType = iota TABLE CHAR IDENT // 識別子 NUMBER LPAREN RPAREN SEMICOLON ) var tokens = []struct { tokenType tokenType // Lex()の戻り値 lval string }{ {CREATE, "create"}, {TABLE, "table"}, {IDENT, "users"}, {LPAREN, "("}, {IDENT, "name"}, {CHAR, "char"}, {LPAREN, "("}, {NUMBER, "10"}, {RPAREN, ")"}, {RPAREN, ")"}, {SEMICOLON, ";"}, }
iotaはGo言語特有の記法で、定数に対して整数の連番を振ってくれます。goyaccを使う場合、goyaccがトークンタイプの整数値を定数として生成してくれます。上記の様に、事前に定義したトークンタイプを見つけて入力文字列を分割していくのが字句解析器の役割です。そして、字句解析器から出力されたトークン列が構文解析器に入力されます。
構文解析器
構文解析器は入力データを受け取り、何かしらのデータ構造を出力する処理をします。入力データは上述した字句解析器から出力されるトークン列です。出力するデータ構造には、構文解析木や抽象構文木など、後段の解析処理に適切なデータ構造を選択します。テキストを入力として受け取り、何かしらのデータ構造を出力するという意味では、多くの人が馴染み深いであろうJSONパーサーと考え方は同じです。ただし、言語アプリケーションで利用するのに適したデータ構造を出力するという点が異なります。
構文解析器は言語アプリケーションの中で重要な役割を担いますが、パーサージェネレータと呼ばれるツールを使って自動生成できます。そのため、言語アプリケーションを開発する場合は学習目的の場合を除いて、パーサージェネレータを使うのが良いでしょう。パーサージェネレータとして有名なツールにはyaccやbison、ANTLRがあります。sqldefはパーサージェネレータにyaccのGo実装であるgoyaccを採用しています。
goyaccは本家yaccと同じ様にバッカスナウア(BNF)記法に似た構文規則を与えることで、コンパイル可能なGo言語のコードを出力します。goyaccの入門にはこちらの記事が非常に参考になります。
抽象構文木
構文解析器の出力から得られるデータ構造を中間表現と呼びます。中間表現の中でも言語アプリケーションに良く用いられるデータ構造が抽象構文木です。
抽象構文木は入力列から不要な字句を省き、重要な字句の文法上の関連を記録したデータ構造です。抽象構文木を構築することで入力列の走査が容易になり、構文解析器の後段に置く処理を簡潔にできます。
なお、抽象構文木に含める情報は開発したいアプリケーションによって都度選択する必要がありますが、sqldefの場合はDDLの変更を検知するための情報が必要です。例えば、sqldefではchar型の文字列長の変更を検知して更新操作がされる様に実装されているので、char(n)の文字列長を示すnも抽象構文木の情報に含める必要があります。
実際に以下の様なDDL文が与えられた場合を例にあげます。
CREATE TABLE users ( id INT, name CHAR(20) )
sqldefの構文解析器が構築する抽象構文木は以下の様になります。

テーブル名や型情報、文字列長など必要な情報だけが抽出され、DDL文を木構造で表現できていることが分かります。
この抽象構文木からインタプリタやコンパイラでは言語変換や評価をしたり、静的解析ツールでは木を走査して特定の文字列を見つけたりしています。
次章ではsqldefが抽象構文木をどの様に使ってデータベースマイグレーションを実現するのかを紹介します。
sqldefの実装
本章ではsqldefの実装について、マイグレーション処理の流れとサポートする構文の追加方法を例に紹介します。
マイグレーション処理の流れ
DDL文を解析するために必要な抽象構文木は、実際の実装を見ると理解が容易になります。そのため、以下にGo言語のstructでDDL文のデータ構造の実装例を示します。
type DDL interface { Statement() } type CreateTable struct { table Table } func (c *CreateTable) Statement() {} type Table struct { name string columns []Column indexes []Index foreignKeys []ForeignKey } type Column struct { name string typeName string notNull *bool length int keyOption ColumnKeyOption } type ColumnKeyOption int const ( ColumnKeyNone ColumnKeyOption = iota ColumnKeyPrimary ColumnKeyUnique )
上記はsqldefの実装から一部を抜粋したものです。テーブルは、テーブル名の他にカラムやインデックス、外部キーの情報をリスト構造で保持しています。カラムは、カラム名や型情報の他に制約などカラムを表現するために必要な情報を保持します。カラムの中にデフォルト制約やチェック制約の構造体が埋め込まれており、DDLが木構造で表現されていることが分かります。
入力を抽象構文木にするまでの処理は、どの言語アプリケーションにも大方共通しますが、抽象構文木をどう使うかが肝になってきます。sqldefの場合、新DDL文の抽象構文木と既存データベースから出力される旧DDL文の抽象構文木の2つを比較し、更新用のDDL文を生成します。
例として、テーブル定義が変更された際に、どの様な処理が行われるかを見てみます。
旧テーブル、新テーブルとして以下のDDLが定義されているとします。旧テーブルと新テーブルの差分は、idカラムのデータ型の変更とnameカラムの追加です。
-- 旧テーブル CREATE TABLE users ( id INT PRIMARY KEY ) -- 新テーブル CREATE TABLE users ( id BIGINT PRIMARY KEY, name CHAR(20) )
この場合、sqldefの構文解析器から出力される抽象構文木は以下の様になります。
// 旧テーブルの抽象構文木 var currentTables = []Table{ { name: "users", columns: []Column{ { name: "id", typeName: "int", keyOption: ColumnKeyPrimary, }, }, }, } // 新DDLの抽象構文木 var desiredDDLs = []DDL{ &CreateTable{ table: Table{ name: "users", columns: []Column{ { name: "id", typeName: "bigint", keyOption: ColumnKeyPrimary, }, { name: "name", typeName: "char", length: 20, }, }, }, }, }
上記の2つの抽象構文木を元にsqldefはschema/generator.goにある処理で更新DDL文を生成します。
sqldefがテーブルを比較し、更新DDL文を生成する処理を簡略化したコードで表すと以下の様に実装できます。
type Generator struct { mode GeneratorMode currentTables []*Table } func (g *Generator) generateDDLs(desiredDDLs []DDL) []string { ddls := []string{} for _, ddl := range desiredDDLs { // 旧テーブルの取得 currentTable := findTableByName(g.currentTables, desired.table.name) if currentTable != nil { tableDDLs := g.generateDDLsForCreateTable(*currentTable, *desired) ddls = append(ddls, tableDDLs...) } else { ddls = append(ddls, "テーブルの追加処理") } } return ddls } func (g *Generator) generateDDLsForCreateTable(currentTable Table, desired CreateTable) []string { ddls := []string{} for i, desiredColumn := range desired.table.columns { currentColumn := findColumnByName(currentTable.columns, desiredColumn.name) if currentColumn == nil { ddls = append(ddls, "カラムの追加処理") } else { // データ型のチェック if !g.haveSameDataType(*currentColumn, desiredColumn) { ddls = append(ddls, "データ型の変更処理") } // デフォルト制約のチェック if !areSameDefaultValue(currentColumn.defaultDef, desiredColumn.defaultDef) { if desiredColumn.defaultDef == nil { ddls = append(ddls, "デフォルト制約の削除処理") } else { ddls = append(ddls, "デフォルト制約の追加処理") } } // primary key, check制約, ...などのチェックとDDL生成 } } return ddls }
DDLの生成処理は、テーブルやカラムの存在チェックや等価判定を駆使して愚直に実装されています。
上記のusersテーブルの定義の場合、以下の順に処理が実行されるでしょう。
findTableByName()が呼ばれ、currentTableに既存のusersテーブルが入るcurrentTable != nilが真になり、generateDDLsForCreateTable()が呼ばれる- 既存テーブルからid列を探す
- id列のデータ型が変更されているので、
!haveSameDataType()が真になり、ddlsにデータ型の変更処理が追加される - 既存テーブルからname列を探す
currentColumn == nilが真になるので、ddlsにカラムの追加処理が追加される
実際にはddlsに追加する処理は、Generator構造体のmodeにしたがって条件分岐し、各DB間の構文の差を吸収しています。例えばカラムの追加の場合、MySQLではALTER TABLE ... ADD ...ですが、SQL ServerではALTER TABLE ... ADD COLUMN ...の様な差分です。
また、テーブルやカラムの他にも外部キー制約やインデックスの比較、更新処理が定義されています。sqldefがどの様なDDL文を生成できるのか気になる方は、schema/generator.goをご覧ください。新たにサポートしたい構文が出てきた時もここに処理を追加していきます。
sqldefがサポートする構文の追加
最後に、sqldefがサポートする構文を追加したい場合の追加手順を、SQL ServerでNOT FOR REPLICATIONオプションを実際に追加対応した際の手順を例に紹介します。
SQL Serverでは制約にNOT FOR REPLICATIONオプションを指定することで、レプリケーションエージェントによるテーブル操作時に制約を無視させることができます。sqldefで、そのNOT FOR REPLICATIONオプションをサポートするために取る手順は以下の通りです。
NOT FOR REPLICATIONオプションを使えることが確認できるテストを追加する- 抽象構文木に
NOT FOR REPLICATIONオプションの情報を追加する NOT FOR REPLICATIONオプションを構文解析できる様にyaccファイルを改修する- 既存データベースのDDL抽出部分で
NOT FOR REPLICATIONオプションも抽出できる様にadapterを改修する - DDL生成部分であるgeneratorを改修する
テストの追加
実装を開始する前に、まずは自分が追加しようとする処理の期待する動作をテストコードに書き起こします。今回のプルリクエストでは、以下の2点を確認するテストコードを追加しています。
- IDENTITYカラムとCHECK制約に
NOT FOR REPLICATIONオプションを使えること - 新たに
NOT FOR REPLICATIONオプションを追加した際に適切な更新DDLが実行されること
sqldefにはテストのためのヘルパーメソッドが用意されており、簡潔にテストコードを書くことができます。assertApplyOutput()を使うことで、定義したDDL文をsqldefに与えた際の出力と期待する出力の比較テストができます。
抽象構文木の改修
次に抽象構文木でNOT FOR REPLICATIONオプションの情報を保持できるよう改修をします。
sqldefは元々Vitessの構文解析器を拡張して開発されたという背景があります。そのため、sqldefにはVitess用の抽象構文木(sqlparser/ast.go)とsqldef用の抽象構文木(schema/ast.go)が存在します。goyaccで生成された構文解析器(sqlparser/parser.go)は、まずsqlparser/ast.goで定義されるデータ構造を出力します。その後、schema/parser.goを使い、schema/ast.goで定義されるデータ構造に変換します。以上のsqldef用の抽象構文木ができるまでの流れを以下の図にまとめました。

この流れがあるため、sqldefの抽象構文木に改修を加える際には、次の3ファイルの改修が必要です。
今回のプルリクエストでは抽象構文木の対象ノードのstructにNOT FOR REPLICATIONの情報を保持するためのフィールドを追加しています。schema/parser.goには抽象構文木の変換処理を追加しています。
yaccファイルの改修
テストコードに新しい構文を追加すると、テスト実行時にsyntax errorが発生するはずです。これは、構文解析器が新しく追加した構文(今回の場合はNOT FOR REPLICATIONオプションの構文)を解析する手段を持たないため発生します。
構文解析器に新しい構文規則を追加するためにはyaccファイル(sqlparser/parser.y)を修正します。今回の変更では、新しいトークン(REPLICATION)の追加とカラムや制約を定義する構文内でNOT FOR REPLICATIONオプションを読むための規則の追加をしています。
さらに、コールバックには上述した改修で追加したNOT FOR REPLICATIONの情報を保持するためのフィールドに値を代入するための変更をしています。yaccファイルの修正が終わったらgoyaccコマンドを使ってsqlparser/parser.goを生成します。
goyaccは構文解析器を生成する際にshift/reduce conflictやreduce/reduce conflictを発生させる場合があります。具体的には、新しく追加した規則が他の規則と重複してしまった際に発生します。conflictが発生してしまった場合は、既存の規則の中で流用できるものを探してみたり、省略記法を使えない様にするなどの対応で解決する場合があります。conflictに関して詳しくは「速習yacc3」をご覧ください。
adapterの改修
sqldefでは既存データベースから取得できる旧DDLと入力される新DDLを比較して更新DDLを生成します。
既存データベースから旧DDLを取得するための実装はadapter/配下にある各データベース用のパッケージに実装されています。例えば、MySQLではSHOW CREATE TABLE構文などを使って既存データベースのDDL文を取得できます。しかしSQL Serverにはその様な構文がないため、システムテーブルの情報を使ってDDL文を生成しています。
今回比較したいのは旧DDL文と新DDL文のNOT FOR REPLICATIONの値です。そのためsys.check_constraintsなどのシステムテーブルからis_not_for_replication列の値を読み込み、DDL文に追加する様に改修しています。
generatorの改修
抽象構文木とadapterの改修ができたら、最後に更新DDLの生成処理を改修します。
1つ目のステップで追加したテストのTestMssqldefCreateTableAddNotForReplication()を見れば、今回generatorに期待する動作が確認できます。期待する動作は、カラムと制約のNOT FOR REPLICATIONオプションを確認し、旧テーブルと新テーブルに差分があれば更新DDL文としてALTER TABLE ...を生成することです。IDENTITY要素の生成処理を追うと分かりやすいですが、generatorは初めにareSameIdentityDefinition()で旧DDL文と新DDL文のIDENTITY要素を比較します。そして2つのDDL文に差分があった場合、カラムの削除とカラムの追加処理を更新DDL文のリストに追加しています。
この様に2つのDDL文の要素を簡単に比較できるのも、構文解析器を使ってDDL文を構造化したことの恩恵です。
以上がsqldefへのサポート構文追加の一例です。全ての変更がこのパターンに則しているわけではありませんが、各コンポーネントの役割を把握することが開発する際の手助けになるかと思います。
おわりに
本記事ではsqldefへの機能実装と言語アプリケーションの実装に必要な基礎知識をご紹介しました。
普段利用するツールの実装を理解することは、自分自身がそのツールをメンテナンスできる様になる点で有意義です。本記事が少しでもsqldefのユーザー増加に貢献し、開発がさらに活発になることを願っています。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
-
Terence Parr, 「言語実装パターン コンパイラ技術によるテキスト処理から言語実装まで」, 2011。↩