



はじめに
技術評論社様より発刊されているSoftware Designの2024年5月号より「レガシーシステム攻略のプロセス」と題した全8回の連載が始まりました。
ZOZOTOWNリプレイスプロジェクトで採用したマイクロサービス化のアプローチでは、安全かつ整合性のとれたデータ移行が必須となりました。第4回では、このマスタDBの移行について紹介します。
目次
はじめに
はじめまして。株式会社ZOZO技術本部ECプラットフォーム部の渋谷と裵です。
ZOZOTOWNは運営開始から10年以上の間オンプレミス環境で構築されたシステムを、アーキテクチャを変えずに拡大してきました。レガシーなシステムは、スケーラビリティや保守コストの問題など多くの課題が存在しています。それらを解決すべく弊社は2017年からZOZOTOWNのマイクロサービス化を進めています。
第3回でもお伝えしたとおり、ZOZOTOWNリプレイスプロジェクトは、ストラングラーフィグパターンを採用したマイクロサービス化を進めています(図1)。ストラングラーフィグパターンとは、古いシステムの機能を徐々に新しいマイクロサービスに移行し、最終的にはすべての機能が新しいシステムに置き換えられた段階で、旧システムを停止するという戦略です。段階的にシステムを移行していくには、旧システムからマイクロサービスが使用するデータを安全に移行し、リプレイスプロジェクトが完了するまでの期間、新旧システムが整合性を保ちながら共存させる必要があります。

そのため第4回では、安全かつ新旧システムで整合性を保証したうえでマスタDBの移行を行った方法を紹介します。
マスタDB移行
マスタDBの移行の説明に入る前に、本記事で使用する各用語について定義しておきます。
| 用語 | 定義 |
|---|---|
| 移行元DB | 移行対象のデータが格納されているSQL Serverのテーブル |
| 移行先DB | 恒常的な本番運用を想定しているMySQLのテーブル |
| 一時DB | 移行元DBからダンプしたデータを格納する一時的なMySQLのテーブル |
| 削除用一時DB | 移行元DBと移行先DBの不整合を解消するために、削除対象となるデータを格納する一時的なMySQLのテーブル |
| Bulkload | 移行元DBから一時DBにデータをロードすること |
| Backfill | 一時DBと移行先DBの差異を埋める処理のこと |
マスタDB移行について
今回のテーマである「DBの移行」は、オンプレ環境で使用していたSQL Serverから、マイクロサービスアーキテクチャに合わせたクラウド環境のAurora MySQLへ移行することを指します。
ZOZOTOWNは、各マイクロサービスが専用のDBを持っており、DB移行の際にはそれぞれのマイクロサービスが使用するデータを、オンプレ環境のSQL Serverからコピーする必要があります。しかし、ただSQL ServerからAurora MySQLへデータをコピーするだけでは済みません。レガシーな設計をモダンに再構築することや、「事業を止めない」というZOZOTOWNリプレイスプロジェクトのポリシーに則し、ダウンタイムなしでデータ移行を実施する必要がありました。
ここでは、ユーザーに影響を与えず安全にデータ移行を実施するための要件、およびそれに伴う課題や実際に採用した移行戦略について紹介します。
要件と課題
データ移行を実施するにあたって、次のような要件を満たす必要がありました。
- テーブル構成を再設計したうえでデータ移行を実施する
- ダウンタイムなしでデータ移行を実施する
テーブル構成を再設計したうえでデータ移行を実施する
冒頭でも言及しましたが、DB移行はただ単純にデータをコピーするだけでなく、既存のレガシーな設計をモダンなものに再設計することも重要な目的の1つです。SQL Serverに存在する主要なテーブルは2006年前後に設計されたものが多く、長い歴史を経たことで最適とは言えない状態にありました。
マスタDBの移行に伴い、移行元DBに存在していた不要カラムの整理、データ型やテーブル間の関係の見直しをするためにテーブル構成を再設計する必要がありました。また、オンプレ側とクラウド側でDBの種類やテーブルスキーマが異なり、レプリケーション等の手法を用いてデータ移行を実施できないため、スキーマ変更の実現手段を検討する必要もありました。
ダウンタイムなしでデータ移行を実施する
ZOZOTOWNは年間1,100万人以上(2024年3月時点)の方々にご利用いただいています。アクセスが非常に多く、サービスを停止することによる機会損失が大きいため、複雑なプロセスを経てもダウンタイムなしでデータ移行を実施する必要がありました。
サービスを停止せずにデータ移行を実施するということは、データ移行実施中も移行元のDBに変更が頻繁に発生します。データ移行が完了したときは、当然ですがオンプレ側とクラウド側でデータの不整合が発生していないことが要求されるため、データ移行中に発生した変更も含めて完全に移行先DBに反映されている必要がありました。
方針
先に記載した要件と課題に対して、次の方針を立てました。
- 異なるDBおよびデータスキーマ間で移行を実施するためにEmbulkを使用する
- ダブルライトをリリースし、データ移行中に発生するDBへの書き込みを両DBにアトミックに実施する
- データを一時DBに格納し、一時DBから移行先DBにデータを移行する
- BulkloadとBackfillを複数回実施する
異なるDBおよびデータスキーマ間で移行を実施するためEmbulkを使用する
Embulkは、異なるデータベース間でのデータ移行を容易にするオープンソースのETL*1ツールです。並列処理をサポートしているため、大量のデータを効率的に移行できます。
Embulkを採用することで、SQL Server とAurora MySQLのような異なるDBおよびデータスキーマ間でのデータ移行を効率的かつ正確に行えます。
ダブルライトをリリースし、データ移行中に発生するDBへの書き込みを両DBにアトミックに実施する
データ移行実施中に正しくデータが書き込まれるように、先にダブルライト処理を実装しました。ダブルライト処理とは、DBへのINSERT/UPDATE/DELETEの書き込み処理が発生した際に、移行元DBおよび移行先DBの両DBに書き込むことを指します。
ただ、ダブルライトするそれぞれのDBは、異なるDBインスタンス・異なるDB管理システムです。オンプレへの更新リクエストとクラウドへの連携の両方が成功した時点で更新をコミットする必要があります。そのため、オンプレで成功していてもクラウド側で失敗したらオンプレ側をロールバックするように、オンプレ側でトランザクションを開始する形でアプリケーションコードを実装しました。
このようにアプリケーションレベルでトランザクションを管理することにより、データ移行中のDBへの書き込みを移行元と移行先のそれぞれ異なるDB間でアトミックに実施できるようになりました。
データを一時DBに格納し、一時DBから移行先DBにデータを移行する
次の2つの要因で、移行先DBにEmubulkで直接ロードするのではなくクラウド側の一時DBを挟む方法を採用しました。
1つは、移行元DBと移行先DBはそれぞれ別のチームが管理しており、一度自分たちの管理するクラウド側にデータを持ってきたほうが操作しやすいためです。
もう1つは、データ移行実行中のデータ読み込み(クエリ実行)と該当データの書き込みの間でレコード削除が実行されると、本来削除されるはずのレコードが後から挿入されることになり差異が発生するにもかかわらず、Embulkではこれらの条件を判別するなどの細かい制御ができないためです。
自作ツールを使用して一時DBから移行先DBへデータを格納することで、SQLだけでは実装が困難な変換が可能になりました。また、ダブルライトの影響を受けることなくダウンタイムなしかつデータ整合性を確保しつつデータ移行を実施できます。
BulkloadとBackfillを複数回実施する
ダブルライトが実装されていたとしても、その後のデータ移行で同様にデータ不整合が発生する可能性があるため、BulkloadとBackfillを複数回実施することにしました。
データ移行の手順
前節でも説明したとおり、データ移行実施中にもダブルライトは実行され続けており、その差異を埋めるためにBackfillを複数回実行します。本節ではレコードを一意に特定できるサロゲートキーを持つテーブルを前提として紹介していきます。
今回のDB移行は次のステップで行いました。
- ダブルライト処理の実装
- データ移行の実施(1回目のBulkload&Backfill)
- 削除データの対応(2回目のBulkload&Backfill)
1. ダブルライト処理の実装
SQL Server の移行元DBでINSERT/UPDATE/DELETEが発生した際、MySQLの移行先DBでも同様の処理を行うように実装します。この時点で移行先DBは空の状態なので、存在しないデータをUPDATEしないように移行先DBではUPSERT(データが存在すればUPDATE、しなければINSERT)する必要があります。
2. データの移行の実施(1回目のBulkload&Backfill)
1回目のBulkload
Embulkで1回目のBulkloadを行い、移行元DBのデータをMySQLの一時DBに転送します。Embulkでは転送元・転送先DBの情報や、転送対象のデータを抽出するためのクエリをリスト1のように指定します。
in: type: sqlserver host: '{{env.SQLSERVER_HOST}}' port: '{{env.SQLSERVER_PORT}}' user: '{{env.SQLSERVER_USER}}' password: '{{env.SQLSERVER_PASSWORD}}' database: '{{env.SQLSERVER_DB}}' query: ¦ SELECT sqlserver_id as mysql_id, sqlserver_name as mysql_name, sqlserver_password as mysql_password FROM sqlserver_table out: type: mysql host: '{{env.MYSQL_HOST}}' user: '{{env.MYSQL_USER}}' password: '{{env.MYSQL_PASSWORD}}' database: '{{env.MYSQL_DB}}' table: mysql_table
リスト1 1回目のBulkload
inフィールドで移行元DBを、outフィールドで一時DBを定義します。移行元DBと移行先DBでカラム名が異なるので、対応するカラムをas句で変換しています。outフィールドではcolumn_optionsを使用すればカラムごとの制約も設定できますが、今回は移行先DBがテーブル定義に基づいてすでに作成されており、一時DBからのBackfill時に違反検知が可能なので使用しませんでした。
1回目のBackfill
次に、一時DBのデータをダブルライト中の移行先DBにBackfillします。ここで、BulklaodしてからBackfillするまでの間に、移行先DBにダブルライトで先にINSERTされるデータを想定し、Duplicate entryエラーを処理する必要があります。
ほかにも、Backfillする際には保存するデータを正しく取捨選択する必要があります。次のケースを考えてみます。
- Aさんの情報が移行先DBにダブルライトでINSERTされる
- Bulkloadを実行する
- Backfillする前にダブルライトで移行先DB上のAさんのデータがUPDATEされる
- Backfillを実行し、Duplicate entryエラーが発生する
この場合、ダブルライトでUPDATEされたほうが正の会員データなので、Duplicate entryエラーが発生した古い会員データは破棄する必要があります。
Backfillが完了したら、想定どおりBackfillされているかを確認するために一時DBと移行先DBの会員データを1つずつ突合して整合性を確認します。ダブルライトが続いている移行先DBは一時DBの会員を包含しているので、一時DBの会員がすべて移行先DBに存在するかを確認することになります。
ダブルライト中に1回目のBulkload&Backfillを実行した際、データは図2のように遷移していきます。最後の移行元DBと移行先DBのデータを比較すると、この段階ではまだデータが一致していない可能性があることがわかります。
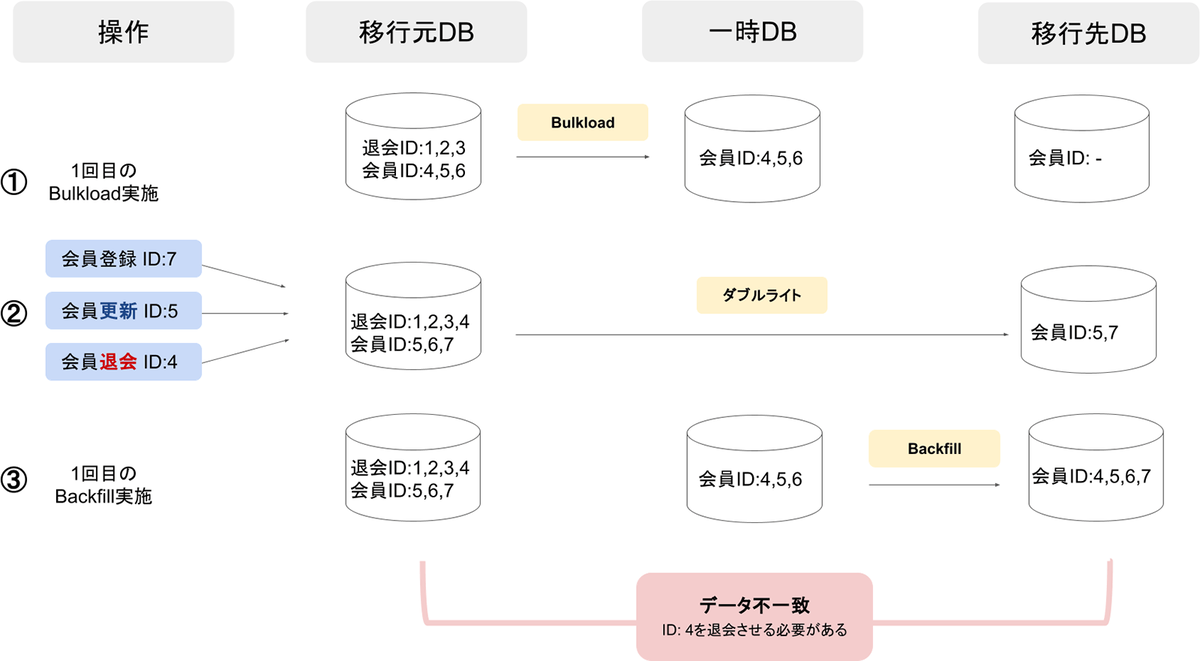
3. 削除データの対応(2回目のBulkload&Backfill)
図2のように1回目のBulkloadを行った後、移行元DBで会員の退会が発生したケースを考えてみます。
移行元DBの会員は削除されますが、Bulkloadを行った時点では存在していた会員なので、1回目のBackfillにより移行元DB上で存在しない会員を移行先DBにINSERTすることになり不整合が生じてしまいます。これを解消するためには、一時DBの作成と同時に削除対象の会員を保存する削除用一時DBを作成し、DELETEした会員を削除用一時DBにINSERTした後、Backfill完了後に削除用一時DBの会員を移行先DBからDELETEする、といった手法が考えられます。
今回移行元DBでは退会した会員をDBからDELETEする物理削除ではなく、退会したことをフラグとしてカラムで管理する論理削除を採用していたので、この情報を基に削除対象会員を抽出しました。
2回目のBulkloadの実行内容の例はリスト2のとおりです。移行元DBの削除フラグを基に削除対象会員を取得しています。また、Bulkloadされた後の会員が削除対象なので、FIRST_BULKLOAD_START_AT以降の会員を取得するようにしています。
in: type: sqlserver host: '{{env.SQLSERVER_HOST}}' port: '{{env.SQLSERVER_PORT}}' user: '{{env.SQLSERVER_USER}}' password: '{{env.SQLSERVER_PASSWORD}}' database: '{{env.SQLSERVER_DB}}' query: ¦ SELECT DISTINCT sqlserver_id as mysql_deleted_id FROM sqlserver_table WHERE sqlserver_delete_flag = 1 AND sqlserver_deleted_at >= '{{env.FIRST_BULKLOAD_START_AT}}' out: type: mysql host: '{{env.MYSQL_HOST}}' port: '{{env.MYSQL_PORT}}' user: '{{env.MYSQL_USER}}' password: '{{env.MYSQL_PASSWORD}}' database: '{{env.MYSQL_DB}}' table: mysql_deleted_table
リスト2 2回目のBulkload
2回目のBackfillでは、移行先DBから削除用一時DBの会員をDELETEします。その後、1回目と同様に想定通り会員が削除されているか、削除用一時DBの会員が移行先DBに含まれていないかを検証します。
ダブルライトしながら2回目のBulkloadとBackfillを行った場合、データは図3のように遷移します。1回目のBulkload&Backfillで発生していたデータの不一致が解消されていることがわかります。

Column: Backfillの効率化
Backfillを行う際、1レコードずつINSERTするのは非常に時間がかかります。そのため、リストAのように1回の実行で大量のデータをまとめて取り込む(BulkInsert)ようにしました。
INSERT INTO mysql_table(name, email, password) VALUES ('鈴木太郎', 'tanaka@example.com', 'xxxx'), ('佐藤花子', 'suzuki@example.com', 'xxxx'), ('田中一郎', 'tanaka@example.com', 'xxxx');
リストA BulkInsertの例
しかし、これだけだとDuplicate entryエラー発生時、どのレコードが原因だったのかを特定できません。そのため、BulkInsert中にいずれかがDuplicate entryエラーになった場合は、1件ずつINSERTしなおすように実装する必要があります。
今回Bulkloadするレコード数の単位は1,000件としました。これは、BulkInsert中はテーブルロックがかかってしまうため件数を多過ぎないようにしたいという意図と、少な過ぎると速度向上が期待できなくなるという懸念を加味して経験則から設定された値です。
データ移行の実施
DB移行の実施
いきなり本番DBで移行を試みるわけにはいかないので、先に検証用の環境で素振りを行います。素振りの結果、メールアドレスと旧ID(メールアドレス以前にログインIDとして使用していたもの)を管理するそれぞれのカラムで次の問題が発生しました。
- 移行元DBでは重複を許可していたが、移行先DBではユニークキーとして定義されている
- 文字コードが移行元DBと移行先DBで異なるため、全角文字が「???」になってしまう
データの重複に関しては、移行元DBで最後にアクセスした日時を保存しているので、メールアドレスを管理するカラム・旧IDを管理するカラムともに、一番新しいデータを正として移行するようにしました(同じメールアドレス・旧IDを使用しているが利用者は別の会員がいた場合、カスタマーサポートでの問い合わせで対応するようにしました)。
文字コードに関しては、カラムごとに別の対応を取りました。
メールアドレスを管理しているカラムの場合、重複時の対応と同様に最終アクセス日時が新しいデータを正として移行しました。一方旧IDを管理しているカラムの場合、全角文字を含むカラムはNULLとして保存するようにしました。この方針は、今後の新規会員は旧IDで登録されないこと、旧IDがNULLになることでログインできなくなる会員がごく少数なのでカスタマーサポートへの問い合わせで十分対応できることを考慮して至った結論です。
上記に対応して検証環境で正常に移行できることを確認した後、本番環境でもおおむね想定通りデータ移行を完了できました。約2千万件のデータ移行を完了するまでのBulkload&Backfillの所要時間は、それぞれ1回目が23分と16分、2回目が24秒と9秒でした。
移行後に発生した問題
DBの移行が完了して一件落着かと思いましたが、移行してからしばらく経過した後に新たな問題が発生しました。ZOZOTOWNではPayPayに連携して決済を行えるのですが、この方法で決済ができないというお問い合わせが多発したのです。
調査の結果、原因はPayPay連携解除時のダブルライトができていなかったことでした。
本来であれば、連携解除した際にオンプレ側のDBで解除処理をした後でマイクロサービス側のDBでも解除処理をする必要があります。しかし、その考慮が漏れていたためマイクロサービス側に連携解除済みの会員が残ることでデータ不整合が発生し、その会員が再連携したタイミングで既に連携データが存在するというエラーが返っていたのです。
不整合データ数が少なければ手動やスクリプトでの対応を考えたのですが、想定よりもはるかに多くのデータに不整合が生じていたので、マスタDBと同様にオンプレDBからデータ移行を行うことにしました。
不整合の解消手順と実施
基本的にはマスタDB移行の手順と同じですが、より正確に移行したことを確認するために今回は1、2回目のBulkload&Backfillを完了した後で3回目のBulkloadを行い、抽出したデータとマスタDBのデータを突合しました。
こちらも先に検証環境で素振りを行いました。結果として計4回の素振りを行いましたが、検証環境では次のようにオンプレやクラウドDBのPayPay連携会員テーブルが本番では想定していない状態で運用されていたので、この原因調査や対応を行う必要がありました。
- ZOZOTOWN会員テーブルへの外部参照を持っているPayPay連携会員テーブルのカラムに、ZOZOTOWN会員テーブルに存在しないレコードが登録されていた
- オンプレDBに重複した会員が登録されており、Backfill時に重複エラーが発生した
検証環境での動作確認を終えた後、本番環境で本番データの移行を行いました。一部想定外のデータが存在していたり、移行作業中に想定外の操作をした会員が存在していたりしたので多少エラーは発生したものの、手動でこれらを対応しつつ、無事PayPay連携で決済できない問題を解消できました。
おわりに
連載第4回では、ZOZOTOWNリプレイスに伴うデータ移行について紹介しました。
アクセス数が非常に多い大規模なシステムを、サービス停止することなくリプレイス対象の機能ごとにデータ移行をする必要があるうえに、レガシーなテクノロジーからモダンなテクノロジーへの移行を行うという要求がある中で、手間はかけつつも安全にデータ移行を成功させることができました。
また、本記事で紹介した戦略を用いて、今後ほかのマイクロサービス化プロジェクトにおいても迅速かつ安全にデータ移行を成功させることができると考えています。
大規模なシステムからマイクロサービス化への移行を検討している方々の参考になれば幸いです。
本記事は、技術本部 ECプラットフォーム部 ID基盤ブロックの渋谷 宥仁、裵 城柱によって執筆されました。
本記事の初出は、Software Design 2024年8月号 連載「レガシーシステム攻略のプロセス」の第4回「ZOZOTOWNリプレイスにおけるマスタDBの移行」です。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。
*1:Extract Transform Loadの頭文字を取ったもので、データを転送元から抽出し、適切なフォーマットに変換し、転送先へ出力する処理のこと。