



こんにちは、バックエンドエンジニアの近です!
2023/5/11〜13に長野県にて開催されたRubyKaigi 2023でプラチナスポンサーとして協賛し、スポンサーブースを出展しました。
また、今年は我々が運営しているファッションコーディネートアプリ「WEAR」のサービス紹介CMを作成し、RubyKaigiの会場にて放映させていただきました。
実際に放映されたCMは以下になります!
我々が運営・開発しているファッションコーディネートアプリ「WEAR」のバックエンドはRuby on Railsで開発しています。2013年にVBScriptで作られたシステムですが、2020年頃からVBScriptのシステムをコードフリーズし、リプレイスをはじめました。現在もリプレイスを進めながら、新規の機能もRubyで開発しています。
次に、セッションの紹介とブースでの取り組み、その他RubyKaigiの様子をお届けします。
今年はバックエンドエンジニア9人の参加となったため、盛り沢山の内容となっております!
エンジニアによるセッション紹介
Multiverse Ruby
@tsuwatchです! Multiverse Rubyを紹介しようと思います。このタイトルだけ見るとなにかよくわからず、もしかしたら候補から外れていた方もいるかもしれません。
内容としては、グローバルなネームスペースを利用せずにコードを共有できるIm(イム)というGemの紹介です。Isolated Module Loaderと紹介されています。Rubyはグローバルな名前空間を利用するしかなく、名前の衝突が問題になります。
解決策として、Rubyの匿名モジュールという特徴を利用して名前空間を作り出し、利用したいモジュールをロードできるというものです。
mod = Module.new mod.name #=> nil mod::Foo = Module.new mod::Foo.name #=> "#<Module:0x0…>::Foo" MyFoo = mod::Foo mod::Foo.name #=> "MyFoo"
実装としては Kernel#load の wrap オプションにモジュールを指定することで、そのモジュール配下に load できる機能の活用をしていました。また、 Module#const_added を prepend することで、匿名モジュールを命名したタイミングで処理を挟むことなどをしていました。
::Module.prepend(Im::ModuleConstAdded)
こういう感じで使えます。
require ‘im’ loader = Im::Loader.for_gem loader.setup loader::MyGem # my_gem.rbが自動的に読み込まれる
こういったRubyの特徴を活かしてハックできるのがRubyの楽しいところで、こういうGemが大好きなので最高でした。
Power up your REPL life with types
天春です。去年はオンライン参加でしたが、今年は初めての会場参加でした。思った以上に楽しかったです。 Power up your REPL life with types を紹介しようと思います。
内容としては、irb1ではできない型分析に基づいたオートコンプリートを提供するkatakata_irb というGemの紹介でした。
katakata_irbをインストールしてrequireを書くだけですぐ使えます。
gem install katakata_irb
% irb irb(main):001:0> require 'katakata_irb' => true
.irbrcに以下の内容を追加しておくと毎回requireしなくても利用できます。
require 'katakata_irb' rescue nil
今までのirbではメソッドチェーンやブロックパラメーターなどのオートコンプリートは表示されていませんでした。
katakata_irbを使うことで型に合わせてオートコンプリートが表示されるので便利ですね。
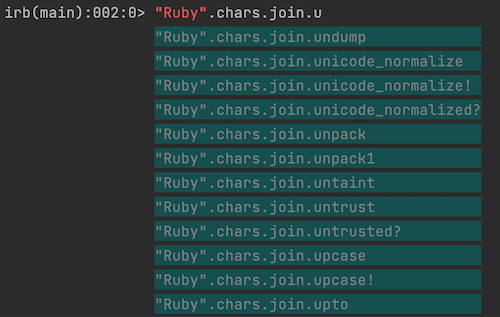
メソッドチェーンやブロックパラメーターにオートコンプリートを実現するため、何をしたかの説明もありましたが、難しくて理解はできませんでした。
簡単に説明するとRipper を使って以下の3段階で実装したとのことでした。
1. 不完全なコードの構文ツリーを取得する 2. RBSを使用してメソッドチェーンを評価する 3. IRBの完了ロジックをオーバーライドする
今回をきっかけにパーサーについて興味が湧いたのでもっと理解できるように勉強したいと思います!
Developing Chrome Extension with ruby.wasm
近です! 自分からはYuma Sawai氏の「Developing Chrome Extension with ruby.wasm」というセッションの紹介をしたいと思います。
このセッションではYuma Sawai氏が作成した、ruby.wasmを使って簡単にChrome拡張機能の開発ができるunloosenというフレームワークの紹介をしていました。
このフレームワークを作成した背景として、以下のように語っていました。
- 昨年発表されたruby.wasmだが、それを使って作られたアプリケーションが少ない
- ruby.wasmにgemsを使った記事はない
- ruby.wasmを使った開発環境がまだ万全ではない
- 開発のしやすさは、開発者の増加に繋がるのではないか
次に、unloosenのメリットとして、以下が紹介されていました。
- Simple Syntax
- フレームワークのTopLevelにdocumentやalertなどのエイリアスを読み込んでいるため、JavaScriptの機能が簡単に使用できる
- Live Reload
- コードの変更があった際に拡張機能の再読み込みをしなくてよい
- Chrome拡張機能の実装に必要なファイルの管理が少なくなる
Simple Syntaxについてですが、通常ruby.wasmを使ってJSライブラリを呼び出す場合、以下のように記述します。
JS.global[:document][:body][:style][:backgroundoColor] = JS.try_convert('red')
unloosenではRuby上でJavaScriptのようにコードを書くことが可能となっています。
document.body.style.backgroundColor = 'red'
また、unloosenの使い方も簡単で、以下の手順にてインストール・実装が可能となっています。
- unloosen-ruby-loaderという起動用スクリプトをnpm installする
- インストールした起動用スクリプトをChrome拡張機能用の設定ファイルであるmanifest.jsonにて指定
- これにより、ruby.wasmとunloosen本体が読み込まれる
- メインの処理を記述するapp.rbファイルを作成し、実装する
- あとは、app.rbをunloosenが読み込み、ruby.wasmにて実装される
自分も実際にunloosenにてChrome拡張機能を実装してみましたが、ruby.wasmを使った実装周りで躓いた箇所は少しあったものの、比較的簡単に作成できました。
皆さんも是非試してみてください!
今回紹介したスライドは以下になります。
Learn Ractor
笹沢(@sasamuku)です。趣味はポケモンカードです。私からはMasatoshi Seki氏によるLearn Ractorをご紹介します2。恐らくはRubyKaigiでポケモンカードに触れていた唯一の発表でした。
発表は「Ractorの紹介」と「ケーススタディ」の2部構成でした。前半ではサンプルコードとともにRactorの次のような特徴が取り上げられました。
Ractor.newに渡すブロック内では外部の変数(グローバル変数含む)にアクセスできないRactor.newの引数経由であれば外部の変数を渡せるがディープコピーになるRactor.make_shareableで外部の変数を同一オブジェクトとしてRactor.newの引数に渡せる3
つまりRactor間でのオブジェクトの共有は基本的にできません。これはRactorがスレッドセーフな並列処理を簡単に書くことを志向しているためです。
手元でも動作を確認してみました。
# `Ractor.new`に渡すブロック内では外部の変数(グローバル変数含む)にアクセスできない a = "hoge" #=> "hoge" Ractor.new { puts a } #=> <internal:ractor>:267:in `new': can not isolate a Proc because it accesses outer variables (a). (ArgumentError) ... # `Ractor.new`の引数経由であれば外部の変数を渡せるがディープコピーになる Ractor.new(a) { |x| puts x } #=> hoge a.object_id #=> 1587220 Ractor.new(a) {|x| puts x.object_id } #=> 1668420 # `Ractor.make_shareable`で外部の変数を同一オブジェクトとして`Ractor.new`の引数に渡せる Ractor.make_shareable(a) #=> "hoge" a.object_id #=> 1587220 Ractor.new(a) {|x| puts x.object_id } #=> 1587220 # 当然ではありますがSymbolなどのイミュータブルなオブジェクトは例外でした b = :hoge #=> :hoge b.object_id #=> 3036508 Ractor.new(b) {|x| puts x.object_id } #=> 3036508
後半ではRactorを活用した高速化事例としてSeki氏が運営されるポケモンカードのデッキ解析サイトが紹介されました。サイトの機能の1つに、デッキの類似度を計算してクラスタリングすることで、ある週のデッキの分布、つまり流行っているデッキを可視化できるというものがありました。デッキの類似度を週ごとに計算する処理をRactor化することで40%ほど処理速度を改善していました。
笹田氏による"Ractor" reconsideredでは、Ractorの普及状況が嘆かれていましたが、こうした実例が増えていくことで利用者が増え性能向上のサイクルが回り始めるのだと理解しました。私もこれからはRactorを使った高速化ができないか常に目を光らせていこうと思います。
発表の最後にSeki氏が「今日はデッキを持ってきています」と話されていたのですが、生憎私は持ってきておらず後悔しました。来年は持っていこうと思います!
Revisiting TypeProf - IDE support as a primary feature
小島です。私からは「Revisiting TypeProf - IDE support as a primary feature」の発表を紹介します。
TypeProfは型注釈のないRubyのコードを型解析してくれます。今回の発表ではこのTypeProfのv2の紹介でした。
発表では、初めに現在のTypeProf v1の課題として型推論だけでは開発者体験の向上に不十分であったとし、TypeProf v2ではIDEサポートをゴールとして開発していると述べていました。TypeProf v1はIDEサポートを考えて作られていなかったこともあり、型解析の速度が遅く、TypeProf v1でそのままIDEサポートを実現することが難しかったようです。そこで、大幅なパフォーマンス改善をすることで、IDEサポートを目標としてTypeProf v2を開発しているとのことでした。
パフォーマンスの改善度合いは数値でも示されていました。TypeProf v1では解析に約3sec掛かっていたところを、v2では初回の解析で約1.003sec、コード編集ごとの追加解析では約0.029secで解析が完了するようでした。
発表ではデモがあり、メソッドに入れる引数の値によって即時に型が推論されVSCode上に表示されるところや、型が間違っている値を代入しようとした場合に警告が出るところなどをデモで見ることができました。
デモを見た感想としては、タイムラグなく型が推論されて表示されておりとてもストレスなく開発できそうでした。
最後に、今回紹介したTypeProf v2はRuby 3.3までに利用可能にすることを目指しているようです。楽しみですね!
今回紹介した発表資料のリンクは以下になります。
speakerdeck.com
Ruby + ADBC - A single API between Ruby and DBs
伊藤です。私は今年初めてRubyKaigiに参加しましたが、内容が幅広く、興味深いセッションばかりでした!
私からはSutou Kouhei氏によるRuby + ADBC - A single API between Ruby and DBsを紹介させていただきます!
このセッションでは、Arrow Database Connectivity (ADBC) を用いてRubyでも大量のデータを読み書きしようという試みを紹介されていました。
既にEmbulkがあるのではと考えた方もいらっしゃるかと思いますが、Embulkは(J)Rubyのサポートを徐々に縮小していく計画だと発表しています。そこで、Embulkとは異なるアプローチとして、ADBCを用いてみようとのことです。
ADBCは、以下の特徴を持っています。
- 各種DBにアクセスするための共通API
- ActiveRecordやSequelも同様
- 多言語対応
- ActiveRecordではRubyでAdapterを実装する必要があるが、ADBCでは他の言語で実装されたAdapterも使える
- 大きな列指向データに最適化
- 高速で大量のデータを処理できるApache Arrowデータフォーマットに特化
- 並列処理が可能
ADBCは大量のデータの読み書きが得意とのことですが、実際どのくらい早いのか気になりますよね? セッション内で紹介されていました!
Sutou氏の実測によると、整数値カラム1つだけのテーブルからレコードをSELECTする場合、1000万レコードを参照する際にlibpqの2倍の速度が出るようです。
ただし、libpqの2倍の速度が出るのはApache Arrow Flight SQLというプロトコルを用いた場合で、libpqをドライバーとして用いた場合はADBCの方が現時点では遅くなるようです。
Apache Arrow Flight SQLとは、Apache Arrow Flight上でSQLを使えるようにしたもので、以下の特徴を持っています。
- Arrowフォーマットを使った高速RPCフレームワーク
- データ交換コストが低い
- 並列転送
- ストリーム処理
Apache Arrow Flight SQLを用いれば、ADBCが高速になるとのことでした。
Apache Arrow Flight SQLを用いると高速になることはわかりましたが、PostgeSQLはApache Arrow Flight SQLを使えるのでしょうか?
なんと、Sutou氏はApache Arrow Flight SQL adapter for PostgreSQLを開発されていました! PostgreSQLでApache Arrow Flight SQLを使用するためのAdapterです。このプロダクトが実用的になると、ADBCを使ってPostgreSQLから高速に大量データを取り込んだり取り出したりできるようになるとのことです。
また、RubyからADBCにアクセスするためのAPIはありますが、ActiveRecord用のAdapter(Active Record ADBC adapter)の開発も始められたとのことです! Ruby on Railsを使用している身としては非常にありがたいです。
まとめますと、以下のような内容でした。
- ADBCを使うとRubyで高速に大量データを読み書きできる
- PostgreSQLでApache Arrow Flight SQLを使えるようにするApache Arrow Flight SQL adapter for PostgreSQLを開発中
- ActiveRecord経由でADBCを使えるようにするActive Record ADBC adapterを開発中
私達が開発しているWEARは今年で10周年を迎え、大量のデータが蓄積されています。それらのデータをRuby on Rails上で高速処理できるようになるかもしれないとのことで、非常に夢の広がるお話だと思いました。
Sutou氏は開発メンバーを募集されていたので、興味のある方は是非参加してみてはいかがでしょうか? 私もこれを機にADBCやApache Arrow Flight周りについてもっと勉強してみようと思います!
Gradual typing for Ruby: comparing RBS and RBI/Sorbet
小山です。私からはGradual typing for Ruby: comparing RBS and RBI/Sorbetのセッションを紹介します。
このセッションではまずはじめに型定義のエコシステムの誕生を時系列で振り返りました。その後、型定義に使われる言語(RBS, RBI)、Type Checker(Steep, Sorbet)といった複数の手段で型定義にアプローチができるものに対する各特徴が解説されました。
個人的に、Rubyの型定義は言語やツールが複数存在していてそれぞれの役割を把握できていなかったのですが、このセッションのおかげで整理されてとても感謝しています。
話者がSorbetを開発しているShopifyで働いていることもあって、セッション中Shopify社内におけるSorbetや型定義に関するサマリーとアンケートが発表され、その内容も興味深かったです。
- Shopifyのモノリスのうち98%のファイルに対して型付けがされており61%のメソッドに対してsigが付与されている
- Shopifyの400を超えるプロジェクトがSorbetを採用している
- より多くのコードに型付けされていることを望むかという質問に対して、Shopifyのエンジニアが2019年7月時点では57%がyesだったが、2022年9月時点では79%がyesと回答している
- Sorbetを他のShopifyのプロジェクトに導入することを望むかという質問に対して、2019年7月時点では39%がyesだったが、2022年9月時点では70%がyesと回答している
これらからRubyの型定義を積極的に現場に導入していて、その結果ポジティブな反応が得られていることがわかりました。
また、発表の中で一番印象的だったのが、SteepとSorbetでType Checkingの速度を比較してみた結果でした。大規模なShopifyの本体のアプリケーションに対してそれぞれでType CheckをしたところSteepは完了に45分要したのに対し、Sorbetは10分で完了したとのことでした。
実際に運用しているアプリケーションでType Checkをしてみたベンチマーク結果が聞けたのは貴重でした。
Steepは型定義にRBSを使い、Sorbetは型定義にRBIを使うのですが、RBS, RBIそれぞれで、現状どのRubyの文法に対応できているかの対応表もとてもわかりやすかったです。
このセッションはRubyの型定義をキャッチアップできていなかった自分にとってとても良い学びになりました。今回の学びを足がかりにして、プロダクトに導入できるように調査を進めていきたいと思います!
Implementing "++" operator, stepping into parse.y
三浦です。 今年のRubyKaigiはパーサーに関するセッションがたくさんありました。 その中でも印象に残ったShioiさんのセッション「Implementing "++" operator, stepping into parse.y」についてご紹介します。
Rubyで実装するとき「なぜインクリメント演算子が使えないのか?」という疑問を持ったことがあるのではないでしょうか。
このセッションではMRIの字句解析器(スキャナ)と構文解析器(パーサー)で i++ はどのように解釈されているのかを探り、試行錯誤しながらインクリメントの実装をしていました。
ruby コマンドでは -y のオプションをつけることで構文解析のログを出力してくれます。
$ruby -ye 'i=0;i++' ... Next token is token '+' (1.5-1.6: ) Shifting token '+' (1.5-1.6: ) // 1つ目の'+'を解析 ... Next token is token "unary+" (1.6-1.7: ) Shifting token "unary+" (1.6-1.7: ) // 2つ目の'+'を解析 Entering state 48 Stack now 0 2 71 313 88 367 48 Reading a token parser_dispatch_scan_event:9857 (1: 7|1|0) // 2つ目の'+'の後に文字がないかを解析 Now at end of input. -e:1: syntax error, unexpected end-of-input i=0;i++
(※こちらはRuby 3.2.2で実行しました)
このログを見ると、i++ の2つめの + は単行演算子として判断されます。
MRIでは + の後には数字が来ることを期待していますが、実際はここでコードは終了しているためシンタックスエラーが発生してしまいます。
インクリメントを実現するために4つの方法を試していました。
- ++の挙動をInteger#succに置き換える
- ++ 専用の構文ルールを追加し、この構文ルールに一致した場合 Integer#succ を呼ぶようアクションを追加
- ++ を Integer#succ のエイリアスのような感じで扱えるようになる
- しかし Integer#succ はレシーバーの値を+1した結果を返しますがレシーバーに結果の代入はしてくれないので、 i++ としても変数iの値自体は更新されない
++の挙動を自前のメソッドで置き換える
Integer#succに変わる自前メソッドInteger#__plusplus__を作成し、同じ方法で呼び出す- レシーバーの変数名を取得し、その変数名に対して値を代入して返す
- しかし
1++といったレシーバーにリテラルが来るとシンタックスエラーとなってしまう
++をスキャナで+=1に置き換える
- スキャナを改造して、
++が来た時に+=と同じ構文木になるよう記号を返す - しかし
i++ * 2といったインクリメントの後に他の演算子が来た時に演算子の優先度が変わってしまい、iに想定外の値が代入されてしまう
- スキャナを改造して、
++をパーサで+=1に置き換える
i++専用の構文ルールを追加し、この構文ルールに一致した場合i+=1と同じ挙動になるようアクションを追加- しかし既存の構文が1つ壊れてしまい、
i++ 1といった予期しない値が来た場合に本来発生しないシンタックスエラーが発生するように
パーサーの仕組みから試行錯誤しながら実装した流れまで丁寧に説明されており非常に分かりやすかったです。
動いた、しかしこんな問題が〜という流れの繰り返しは笑いを誘い面白かったです。
Shioiさんは鹿児島Ruby会議02の際に構文解析についての詳しい解説をされておりこちらも非常に勉強になりましたので、興味ある方は是非読んでみてください!
たのしいRubyの構文解析ツアー
The Adventure of RedAmber - A data frame library in Ruby
高久です。私からはHirokazu SUZUKIさんの「The Adventure of RedAmber - A data frame library in Ruby」についてご紹介します。
このセッションでは、Rubyでデータフレームを扱うためのライブラリであるRedAmberの機能紹介やどのように開発したかをデモを交えてお話しされていました。
データフレームとは行と列からなる表形式のデータ構造のことで、スプレッドシートやRDBのテーブルの構造に似ています。RedAmberを使うことで、Rubyらしい書き方で様々なデータ処理を行うことができます。
デモでは、RubyKaigiの過去の開催地リストとGeoloniaの住所データをデータソースとして、最終的には日本地図にRubyKaigiの過去の開催地をマッピングするまでの過程を紹介していました。内容としては両データを結合するためにKeyとなるデータを文字列加工したり、両データをleft_joinをして結合させていたり、高校生ぶりに見たtanを使った簡単な計算をしていました。
自分は業務で大規模なデータ処理を行うことが少ないこともあり、こういったデータ処理を行う時は今まではGoogleのスプレッドシート一択でした。ただオンラインでの処理になるため、データ量が多いとデータの受け渡しや描画処理に時間がかかってしまうこともありました。RedAmberを使うことで書き慣れているRubyで、わかりやすくデータ処理の記述ができるので、今後データ処理を行うことがあれば使ってみようと思いました。
以下発表スライドです。
スポンサーブース
今年も去年に続き、スポンサーブースを出展しました。

今年は、去年のTシャツに加えてWEARのロゴやQRコードがプリントされているクッキーや、「一合一会」という洒落の効いたお米、加えてZOZOMATやZOZOGLASSなどを配布しました。
中でもTシャツとお米は好評で、「ZOZOさんのTシャツお洒落ですよね!」や「ブースでお米配ってましたよね!」など、色々なところで感想を言っていただきました。

また、今年はブースにて『エンジニアのファッション事情を大調査!』というアンケートを実施しました。
リモートワーク時の服装は?

- 全身部屋着
- 97票
- トップスだけ着替える
- 33票
- 全身着替える
- 47票
- リモートワークをしたことがない
- 3票
個人的には「トップスだけ着替える」が一番多くなると予想していましたが、「全身部屋着」派が一番多く、驚きました。また、意外にもちゃんと「全身着替える」派がけっこうな割合いますね。
春に着たいアウターは?

- コート
- 29票
- ジャケット
- 126票
- パーカー
- 180票
- カーディガン
- 84票
こちらは予想通り、プログラマーの制服とも言われている(※諸説あり)パーカーが一番多いですね! 僕もパーカー派です。
ノベルティで欲しいファッションアイテムは?

- Tシャツ
- 22票
- パーカー
- 51票
- 靴下
- 18票
- その他
- トートバッグ
- キャップ
- ハンカチ
- サコッシュ
- ウィンドブレーカー
- 傘
- ビーチサンダル
- マイクロファイバークリーナー
皆さんに「その他」の項目で様々な回答をいただきました。ありがとうございます!
自分達では出ないようなアイテムもあって面白いですね。次回の参考とさせていただきます。
結果としては、ここでもパーカーがかなりの人気となりました。確かにWEARロゴ入りパーカー欲しいです!
ブース企画も大勢に参加して頂き、ノベルティも全て配布できました。ありがとうございました!
最後に
ZOZOではセミナー・カンファレンスへの参加を支援する福利厚生があり、カンファレンス参加に関わる渡航費・宿泊費などは全て会社に補助してもらっています。ZOZOでは引き続きRubyエンジニアを募集しています。
以下のリンクからぜひご応募ください。
https://hrmos.co/pages/zozo/jobs/0000026hrmos.co
おまけ
ブースを設置し、ラーメン屋のようなポーズで記念撮影している様子。
文化祭みたいで楽しいですね。

WEARポーズで集合写真を撮りました。

OfficialPartyの様子。
大勢が参加していました。いろんな人と交流できて楽しかったです!

今年はコロナも落ち着いて、セッションだけでなくOfficialPartyなど色々な人と交流できる場が多くなっていてとても楽しかったです。
Matzさんとも記念撮影できました!

来年はなんと沖縄開催で、会場は大盛り上がりでした。
自分も既にテンションが上がっています。待ち遠しいですね!

今年はセッションだけでなく、交流会も多くあって色々な人と関わることができたのでとても楽しかったです。また来年沖縄でお会いしましょう!