



はじめに
こんにちは。2020年5月に入社しましたMA基盤チームの辻岡です。
MA基盤チームでは、マーケティングに関わる様々なプロダクトやシステムの施策開発・運用を行っています。その中の1つにリアルタイムマーケティングシステムというものがあります。
これまでこのシステムには検証環境が存在しませんでした。そこで、検証環境を新たに作る事でシステムの開発や運用の効率化並びに品質の担保に貢献した事について紹介します。
また、検証フェーズの効率化手段としてDigdagを利用したデータ転送機能は使ってみると想像以上に便利だったので、実装方法について詳しく紹介します。効率化手段の1つとして参考にして頂けたら幸いです。
目次
- はじめに
- 目次
- リアルタイムマーケティングシステムの概要
- バッチ配信システムの処理の流れ
- 検証環境が導入される前
- 検証環境を導入した後の効率問題
- データ転送機能の実装方法
- 改善した検証環境で検証を行うメリット
- まとめ
- おわりに
リアルタイムマーケティングシステムの概要
これから紹介するシステムについて、いくつかの登場人物を説明します。
- リアルタイムマーケティングシステム
- バッチ配信システム
- analyzer
リアルタイムマーケティングシステム
以下の判定(最適化)を行った上で対象のお客様(ユーザ)に対しておすすめの商品(コンテンツ)を配信しているのがリアルタイムマーケティングシステムです。
- よく見るチャネル(LINE、メール等)に配信する
- よく見る時間帯に配信する
- n日に1通の頻度で配信する
分かりやすいように具体例を1つあげます。ランキング急上昇中のアイテムのうち、おすすめ商品を紹介したい場合、お客様に合わせた適切なチャネル・時間帯・頻度を判定して送る事で、よりコンテンツを見て頂けるようになります。以下が実際のメールでの配信例です。

リアルタイムマーケティングシステムという名前ですが、リアルタイムの配信だけでなくバッチでの配信も行っています。今回はそのバッチ配信システムのキャンペーン実装について取り上げます。
バッチ配信システム
特定条件のユーザを特定時間に抽出し、最適化した上でコンテンツを配信する仕組みをバッチ配信システムと呼んでいます。
analyzer
最適化を高速で行うシステムのコアとなるアプリケーションをanalyzerと呼んでいます。
これはJBoss Enterprise Application Platform(JBoss EAP)上で動いており、関連機能も複数利用しています。例えば、Excelでルール判定を行うためのDecision Managerを最適化に利用し、分散キャッシュストアであるJBoss Data Grid(JDG)を処理の高速化のために利用しています。
バッチ配信システムの処理の流れ
バッチ配信は以下のような流れで行われます。
データの流れは以下のようになっています。
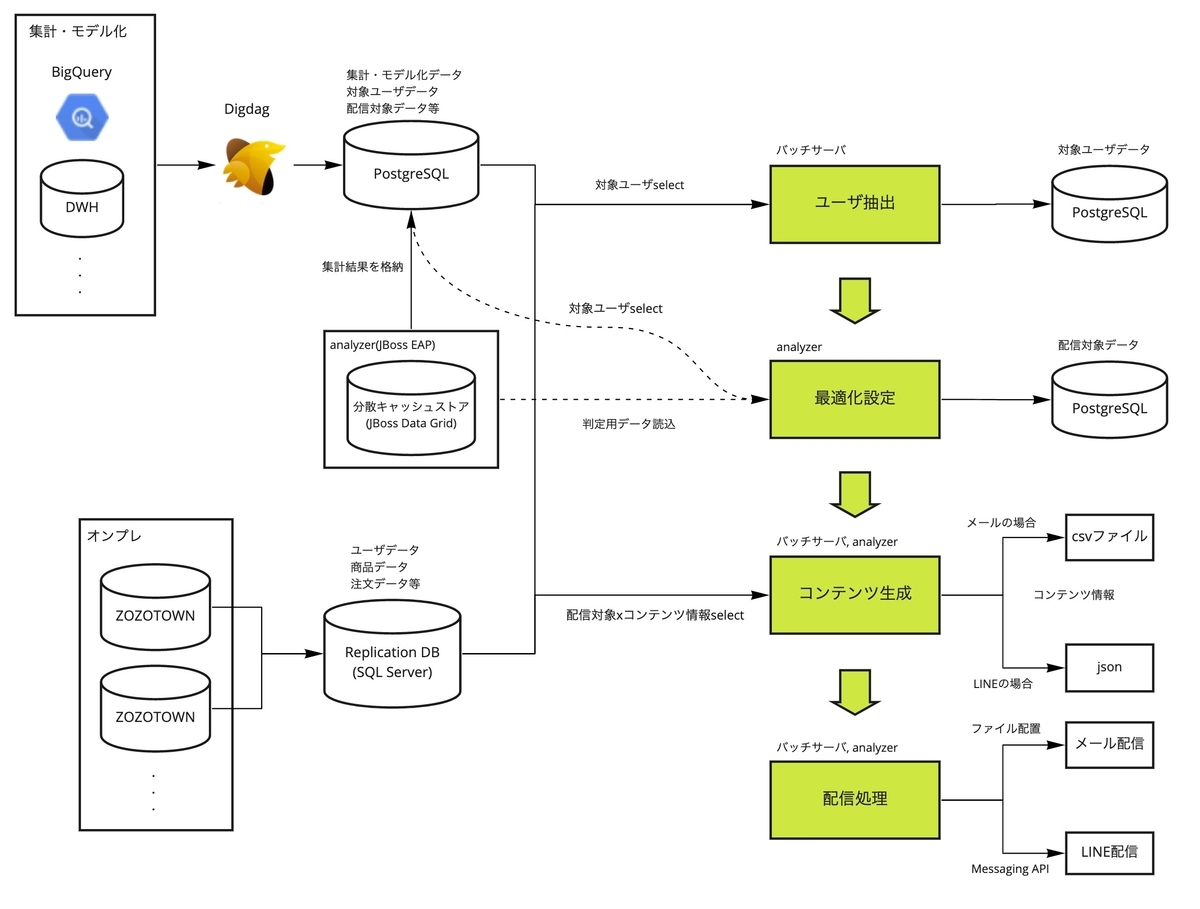
処理の中でSQL ServerとPostgreSQLの2種類のDBを利用しています。処理の説明前にこの2つの用途について記載します。
SQL Serverは、ZOZOTOWNの各DBをレプリケーションしたDBです。ユーザ、商品、注文情報等ZOZOTOWNに関するデータを格納しています。
PostgreSQLは、リアルタイムマーケティングシステム専用のDBです。後続処理で利用するデータ、JDGに格納した実績や集計結果、BigQueryやDWH等外部で生成したデータを格納しています。外部データの連携にはDigdagを利用しています。
では処理の流れを説明していきます。
ユーザ抽出は、配信したい対象のユーザのリストを取得する処理です。リアルタイムマーケティングシステムではMyBatisを採用しているため、MyBatisのMapper XMLを利用してSQL Server経由でデータ抽出を行うためのSQL文を追加していきます。データ抽出後、結果を対象ユーザテーブル(PostgreSQL)に格納します。後続処理がこのデータを読み込みます。
最適化設定はanalyzer上で行われます。実装はDecision Managerを利用しているためExcelに設定値を追記します。今回の利用用途では、恩恵はあまり受けないので詳細は割愛します。この機能により、最適な時間帯に配信対象テーブル(PostgreSQL)へ対象ユーザIDや配信キャンペーンID等を書き込み、コンテンツ生成を行う処理がこのデータを読み込みます。
コンテンツ生成は、対象ユーザに配信コンテンツを表示・配信するための情報を取得します。例えば氏名、メールアドレス、商品名、画像名、金額等が該当します。配信対象テーブルを読み込み、最適化設定で判定したチャネルに合わせて必要情報を取得します。メールの場合はユーザ抽出と同様、Mapper XML経由でデータ抽出を行い、結果をcsvファイル出力します。LINEの場合はanalyzerから直接SQL文を実行し、結果をjsonに格納します。
配信処理は、ユーザにコンテンツをチャネル別に配信する処理です。メールの場合は、出力したcsvをMPSE(MailPublisher Smart Edition)というメール配信サービスにAPIで送っています。送ったcsvの値をMPSE側に予めセットしたデザインテンプレート(html, txt)へ差込む事で配信します。LINEの場合は、analyzerで格納したjsonをLINEのAPIリクエストに持たせてアクセスする事で配信します。
このシステムの全体的な仕組みの詳細については先のブログをご参照ください。 techblog.zozo.com
このうちMapper XMLを使ったユーザ抽出とメール配信時のコンテンツ生成のSQL文実装は、検証の効率化による恩恵を大きく受けました。イメージがつくよう、詳しく実装方法を説明します。
ユーザ抽出・コンテンツ生成の実装方法
架空のTシャツ訴求キャンペーンのユーザ抽出の実装方法を例に説明します。ユーザ抽出とコンテンツ生成の基本構成は同じで、SQL文だけが異なります。
ユーザ抽出の実装例
仕様
前日のTシャツのアクセスが100回以上の会員が対象。
データの抽出方法について説明しておきます。
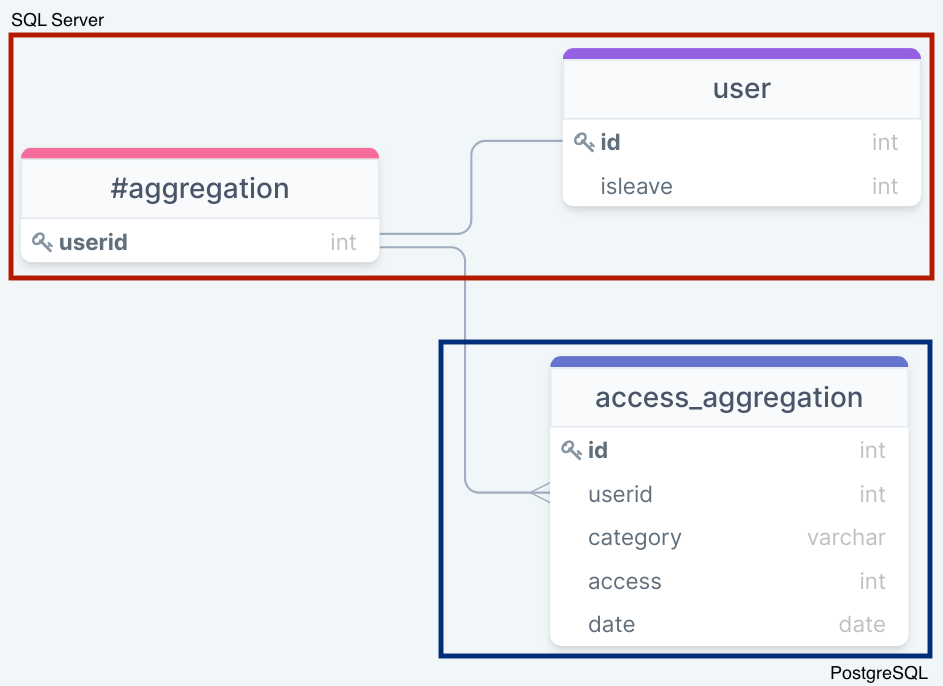
以下の2テーブルを利用します。
- access_aggregation at PostgreSQL
- user at SQL Server
抽出方法の流れは、まずaccess_aggregationテーブルで、categoryがtshirt、accessが100以上のuseridのリストを抽出します。このあと紹介する方法を使って、SQL Serverから該当のPostgreSQLのデータを抽出しtempテーブル(#aggregation)に格納します。そして、userテーブルから退会フラグ(isleave)が0かつ#aggregationに該当するidを抽出します。
このようなテーブル構成イメージです。
実装方法
以下のようなリソースのファイル構成の状態で、キャンペーンのユーザ抽出用のSQL文を記載するxmlを追加します。
resources
└──mybatis
├──mappers
│ ├──common.xml #共通ファイル
│ └──campaign_tshirt.xml #新規追加
└──config.xml #共通ファイル
以下のようなSQLにより、データを抽出します。
common.xml
<sql id="create_tmp_aggregation"> <![CDATA[ CREATE TABLE #aggregation ( userid INT NOT NULL PRIMARY KEY (userid) ); ]]> </sql> <sql id="aggregation"> <include refid="create_tmp_aggregation"> <![CDATA[ INSERT INTO #aggregation ( userid ) SELECT userid FROM openquery(rds, ' SELECT userid FROM access_aggregation WHERE category = ''tshirt'' AND access >= 100 AND date = current_date + interval ''-1DAY'' GROUP BY userid ') LFD; ]]> </sql>
campaign_tshirt.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <mapper namespace="jp.zozo.marketing.realtime.campaign"> <include refid="aggregation"> <select id="campaign_tshirt" resultType="map"> SELECT id FROM user INNER JOIN #aggregation ON user.id = userid WHERE isleave = 0 </select> </mapper>
PostgreSQLのデータは、SQL ServerのSQL文からリンクサーバという他DBにアクセスできるデータベースエンジンを経由し取得します。
リンクサーバを経由したデータ抽出は全てcommon.xmlというファイルに記載します。Tシャツキャンペーンのmapper用xml(campaign_tshirt.xml)にuserid抽出のために、SQL ServerのSQL文を記載します。
あとはcampaign_tshirt.xmlを、アプリケーションが読み込むよう設定されているconfig.ymlに追記します。
config.xml
<!-- 既存 --> <mapper url="../mappers/common.xml"/> <!-- 新規追加 --> <mapper url="../mappers/campaign_tshirt.xml"/>
これにより、アプリケーションがTシャツキャンペーンの対象者を抽出し、対象データテーブル(PostgreSQL)にinsertする事で後続処理に続きます。メールコンテンツ生成も同様の方法でSQL文を生成し、csvを出力して後続処理に続きます。
実装はこれで完了です。実装の流れは一見単純なものですが、実運用では以下の課題が潜んでいます。
実運用での課題
ここでは、実運用で発生した課題を2つ紹介します。
コンテンツ生成のSQL文は長く複雑
コンテンツ生成をするためには、複雑で長いSQL文を作成する事が殆どです。
取得できるデータとSQL文を駆使してコンテンツに必要なデータを抽出するため、仕様の複雑化による影響を受けやすい事が原因です。例えば以下のようなSQL文が挙げられます。
- 出力カラム数200個
- カラムを組み合わせた加減乗除の計算式
- caseごとに分岐されたデータ加工
- 条件判定後の番号(row_number等)振り直し
- 入れ子状態のサブクエリ(サブクエリのサブクエリのサブクエリ)
説明のために実際のものを簡素化し、DB情報等も変えていますが、以下のようなイメージです。
<!-- 対象ユーザの商品情報 --> <sql id="item_info"> <![CDATA[ CREATE TABLE #ITEM_INFO ( MEMBER_ID INT NOT NULL ,ITEMID INT NOT NULL ,IMAGENAME VARCHAR(50) NOT NULL ,ITEMNAME NVARCHAR(100) NOT NULL ,BRANDNAME NVARCHAR(100) NOT NULL ,PRICE NVARCHAR(15) NOT NULL ,DISCOUNT NVARCHAR(10) ,DISCOUNTCOLOR VARCHAR(10) ,COUPONCOLOR NVARCHAR(10) ,COUPONPOINT NVARCHAR(15) ,CMTST NVARCHAR(10) ,CMTEND NVARCHAR(10) ,RANK SMALLINT NOT NULL PRIMARY KEY (MEMBER_ID, RANK) ); INSERT INTO #ITEM_INFO SELECT MEMBER_ID ,ITEMID ,IMAGENAME ,CASE WHEN LEN(ITEMNAME) <= 36 THEN ITEMNAME ELSE LEFT(ITEMNAME, 34) + '...' END AS ITEMNAME --商品名 ,CASE WHEN LEN(BRANDNAME) <= 15 THEN TBNAME ELSE LEFT(BRANDNAME, 14) + '...' END AS BRANDNAME --ブランド名 LTRIM(RTRIM(FORMAT(ROUND((PRICE * TAXRATE), 0), N'#,0'))) AS PRICE ,CONVERT(VARCHAR(3), FLOOR((1.0 - (SALEPRICE * TAXRATE) / (SALEPRICE * TAXRATE)) * 100)) + '%OFF' AS DISCOUNT --割引率 ,CASE WHEN DISCOUNTFLAG = 1 THEN 'discounted' ELSE NULL END AS DISCOUNTCOLOR --価格の文字色 ,COUPONCOLOR ,COOUPONPOINT ,CASE WHEN COOUPONPOINT IS NULL THEN '<!--' ELSE NULL END AS CMTST --クーポンがない場合コメントアウト ,CASE WHEN COOUPONPOINT IS NULL THEN '-->' ELSE NULL END AS CMTEND --クーポンがない場合コメントアウト ,ROW_NUMBER() OVER (PARTITION BY MEMBER_ID ORDER BY RANK) AS RANK --条件判定後に掲載順を振り直す FROM #TARGET_MEMBER_ITEM AS MODEL --PostgreSQLで抽出した配信対象xモデル化データx外部連携データ (作成SQL文略) INNER JOIN ITEM ON MODEL.ITEMID = ITEM.ITEMID INNER JOIN SHOP ON ITEM.SHOPID = SHOP.SHOPID ・ ・ ・ LEFT OUTER JOIN #EXCLUDED_ITEM AS EXCLUDED ON ITEM.ITEMID = EXCLUDED.ITEMID --掲載対象外の商品情報(作成SQL文略) LEFT OUTER JOIN #COUPON_INFO AS COUPON ON SHOP.SHOP_ID = COUPON.SHOP_ID --クーポン情報(作成SQL文略) WHERE EXCLUDED.ITEMID IS NULL --対象外の商品を除外する ・ ・ ) AS BASE WHERE RANK <= 18; ]]> </sql> <!-- 対象商品をデザインテンプレート差込のためメンバーごとに横変換 --> <sql id="main_info"> <![CDATA[ SELECT /* カラム名はデザインテンプレート依存 */ /* ユーザ情報 */ EMAIL ,NAME ,MEMBER_ID ,TEMPLATEID --デザインテンプレートID /* メインコンテンツ情報 */ /* 商品1 */ ,MITEMID01 ,MITEMNAME01 ,MIMAGENAME01 ,MBRANDNAME01 ,MPRICE01 ,MDISCOUNTRATE01 ,MDISCOUNT01 ,MCOUPONCOLOR01 ,MCOUPONPOINT01 ,MCMTST01 ,MCMTEND01 /*商品2*/ ,MITEMDETAILID02 ,MITEMID02 ・ ・ ・ ,MCMTST18 ,MCMTEND18 /* MAT対象者はコメントアウト */ ,CASE WHEN MAT_MEMBER_ID IS NOT NULL THEN '<!--' ELSE NULL END AS COMMENDSTART ,CASE WHEN MAT_MEMBER_ID IS NOT NULL THEN '-->' ELSE NULL END AS COMMENDEND ,DATEPART(year, CURRENT_TIMESTAMP) AS CURRENTYEAR ,DATEPART(month, CURRENT_TIMESTAMP) AS CURRENTMONTH ,DATEPART(day, CURRENT_TIMESTAMP) AS CURRENTDAY ,DATEPART(hour, CURRENT_TIMESTAMP) AS CURRENTHOUR ,DATEPART(minute, CURRENT_TIMESTAMP) AS CURRENTMINUTE FROM #TARGET_MEMBER AS TARGET --MODELから生成した対象者xMAT対象情報(作成SQL文略) INNER JOIN( SELECT MEMBER_ID ,ITEMID AS MITEMID01 ・ ・ ・ ,CMTEND AS MCMTEND01 FROM #ITEM_INFO WHERE RANK = 1 ) AS ITEM01 ON TARGET.MEMBER_ID = ITEM01.MEMBER_ID ・ ・ ・ INNER JOIN( SELECT MEMBER_ID ,ITEMDETAILID AS MITEMDETAILID18 ・ ・ ・ FROM #ITEM_INFO WHERE RANK=18 )AS ITEM18 ON ITEM17.MEMBER_ID = ITEM18.MEMBER_ID ]]> </sql> <!-- PC用コンテンツ --> <select id="pc_select" parameterType="map" resultType="java.util.LinkedHashMap"> <include refid="target_member_item" /> <include refid="target_member" /> <include refid="excluded_item" /> <include refid="coupon_info" /> <include refid="item_info" /> <include refid="main_info" /> <![CDATA[ SELECT /* main_infoでselectした項目全部 */ EMAIL ・ ・ ・ /* PC版のみバナー情報 */ ,HEADERBANNER ,HEADERURL ,FOOTERFILENAME01 ,FOOTERURL01 ・ ・ ・ ,FOOTERURL06 FROM ( <include refid="main_info" /> ) AS MAININFO CROSS JOIN BANNER_INFO; ]]> <!-- セッションに残らないようにtmpテーブル削除 --> DROP #TARGET_MEMBER_ITEM; DROP #TARGET_MEMBER; DROP #EXCLUDED_ITEM; DROP #ITEM_INFO; DROP #COUPON_INFO; </select> <!-- モバイル用コンテンツ --> <select id="mobile_select" parameterType="map" resultType="java.util.LinkedHashMap"> <include refid="target_member_item" /> <include refid="target_member" /> <include refid="excluded_item" /> <include refid="coupon_info" /> <include refid="item_info" /> <include refid="main_info" /> <!-- セッションに残らないようにtmpテーブル削除 --> DROP #TARGET_MEMBER_ITEM; DROP #TARGET_MEMBER; DROP #EXCLUDED_ITEM; DROP #ITEM_INFO; DROP #COUPON_INFO; </select>
慣れてしまえば一発で想定SQL文を書く事も可能ですが、慣れていないとSQL文からは実行結果の推測すら難しいでしょう。
ローカルでの検証が困難
ユーザ抽出の実装例で、リンクサーバを経由してPostgreSQLからデータを抽出する工程があったのを覚えていますか。リンクサーバの存在がローカル環境での検証を困難にした理由の1つです。
リンクサーバ経由の接続のためにOLE DBというデータソースアクセス機能を利用する必要があります。そのため、OLE DBで接続を行うための「OLE DBプロバイダー」が必要でした。Windows環境であればプロバイダーも存在しますが、開発者の大半がmacOS/Linux環境を利用しており、対応プロバイダーが見つからなかったため断念しました。
よって、ローカルでバッチ配信システムを動かしてもリンクサーバ経由の接続ができないため、ローカルでは処理を通貫して確かめる事はできない状態でした。
検証環境が導入される前
新しい人の増加や組織が変化する中、実装頻度が増え仕様はより複雑化していました。しかし先の通りローカル環境もなく、本番環境でしか検証ができない状況でした。当時の私のように慣れていない人の場合、以下のような状況に陥りました。
既存改修を検証する方法は「本番に影響を与えないように気をつけながら試行錯誤」のみ
既にリリースされたキャンペーンを修正する必要がある場合、本番稼働中のそのキャンペーンに影響しないよう、影響を与えない範囲で試行錯誤を少しずつして確認を行っていました。確認方法を検討するだけで長い時間を要する事もありました。
修正と確認のリードタイムが長くなる
入念に目視確認を行った後に本番リリースし検証。リリース後の検証を動かして何か見つかれば修正。このようなリリースを何度も繰り返します。動作確認してない、かつ本番リリースなので、自然と確認時間も長くなります。私は入社当初、何度もこのような本番リリースを繰り返しました。
監視担当に余計な負荷をかける
本番環境では監視設定があり、エラーはSlackの本番監視用チャネルに通知する仕組みが入っています。今回の検証時のエラーも例外ではありません。これは他の監視の妨げにもなりかねず、余計な監視アラート通知は皆に負荷をかける行為です。繰り返しの本番リリースに加えて、この状況は私の作業効率を下げていきました。

これらの課題を解決するため、AWS上にリアルタイムマーケティングシステムを動かす検証環境を作りました。同時に、検証環境でバッチ配信システムの検証も可能にしました。しかし、問題も発生しましたので、その問題について説明します。
検証環境を導入した後の効率問題
検証環境を導入し、本番環境に依存して余分に増えていた作業時間は短縮されました。しかし、検証環境で検証をするための準備に時間がかかるという問題が残っていました。

これを解決するために下記2点を行いました。
- デプロイの自動化
- データ転送の自動化
デプロイの自動化
当初、検証環境でのデプロイは全て手動で行っていましたが、検証用ブランチ(staging)にマージ後、CircleCIが自動で検証環境にファイルをコピーするよう、デプロイ手順を自動化しました。
データ転送の自動化
検証環境により、処理の流れを確認できるようになりましたが、処理をするためのデータが入っていないと想定結果を返すかどうかの確認ができません。当時はこの検証環境のデータ不備により、本番環境で気付いた後に、再検証を行うという検証環境の導入前と同様の状況になりました。
その後、都度本番から検証に必要なデータを取得してinsertするようにしました。利用するテーブルやケースが多いためデータの準備にとても時間がかかりました。
そこで、Digdagを使ったデータ転送機能を追加しました。
Digdagを使ったデータ転送については、やってみると効率化だけでなく、品質担保にも有用でした。
これらの改善により、検証からリリースまでのフローは以下のように効率改善されました。

Digdagを選択した理由は、既に他のデータ連携の実装で多用していたため知見もあり、比較的導入しやすかった事が主な理由でした。しかし実際に使ってみると、検証ケースが書かれたドキュメントとして残せたり、追加改修の時に流用しやすかったりと利点が多くありました。そのため、結果的にこの選択は正しいものでした。
Digdagを使ったデータ転送について、以下で実装方法と共に説明していきます。
データ転送機能の実装方法
PostgreSQLとSQL Serverの本番データを検証環境に転送する機能の実装方法について説明します。
SQL Serverではテーブル定義による壁があり、定番のEmbulkではなく別の方法を使っています。同じ壁にぶつかった方の参考になればと思います。
なお、環境変数やsecretsの設定方法、利用しているDockerイメージの詳細説明についてはトピックから外れるため一部省略しています。予めご了承ください。
また、本番環境に個人情報や情報区分の高いものがある場合は取り扱いに注意してください。
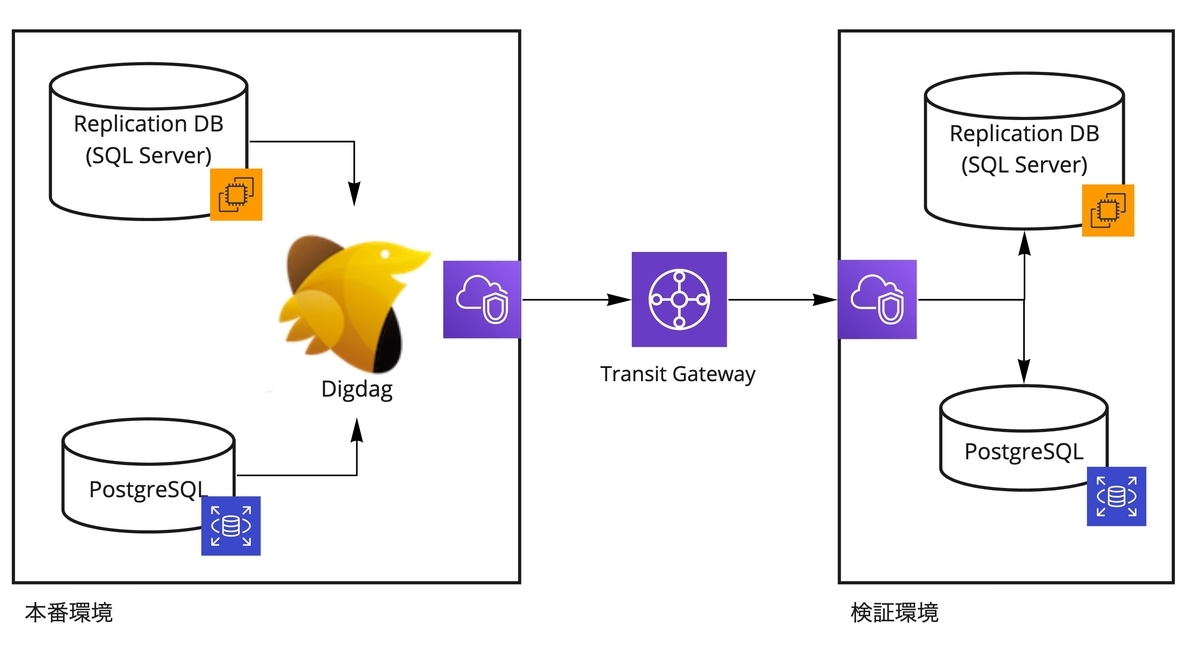
本番環境と検証環境間の接続について
環境を跨いだVPC間の接続ではAWS Transit Gatewayを利用しています。Transit Gatewayはルーターのような役割で、VPCを接続(Attachment)し、通信させたいサーバの接続情報をルートテーブルに設定する事でVPC間の通信を実現します。セキュリティグループの制御により単一方向のみ接続を許可しています。
digファイル構成
キャンペーンごとにどのデータ定義をしたか判別しやすくするため、専用の実行digファイル(TestDataxxxx.dig)とデータ定義の設定(config/xxxx)を用意します。キャンペーンに依存しない共通処理はsub、taskディレクトリに保持しています。
- config
- データ定義に関する情報を記した設定ファイル群
- sub
- 実行digファイルの中で実行するサブタスク群
- tasks
- サブタスクの中で実行するスクリプト群
以下のような構成で管理しています。中のファイルについては後述します。
ProductionToStaging
├── TestDataCampaignA_postgres.dig
├── TestDataCampaignA_sqlserver.dig
├── config
│ └── campaignA
│ ├── postgres
│ │ └── ranking.yml.liquid
│ └── sqlserver
│ └── target.yml
├── sub
│ ├── build_query_parameter.dig
│ ├── copy_sqlserver.dig
│ ├── postgresql_environment.dig
│ ├── prepare_environment.dig #環境変数の設定
│ ├── run_embulk.dig
│ └── secrets.dig #secrets設定
└── tasks
├── bcp_copy.sh
└── query_parameter.rb
PostgreSQLのデータ転送方法
PostgreSQL同士でのデータ転送にはEmbulkを利用しました。input、output共にPostgreSQL用のJDBCプラグインを利用します。
Embulkは異なるDBやストレージ間でデータ転送できる事が特徴ですが、今回のようなPostgreSQL同士のデータ転送でも利用できます。以下の例のように、設定をliquidというテンプレートエンジンを使ってinput(in:)とoutput(out:)情報を記載する事で実現します。
target.yml.liquid
in: type: postgresql host: {{ production_postgres_hostname }} port: {{ production_postgres_port }} user: {{ production_posrgres_user }} password: {{ production_postgres_password }} database: {{ database }} query: #人気ランキング上位3位 SELECT user_id ,item_id ,rank FROM ranking WHERE rank <= 3 out: type: postgresql host: {{ staging_postgres_hostname }} port: {{ staging_postgres_port }} user: {{ staging_postgres_user }} password: {{ staging_postgres_password }} database: {{ database }} table: ranking mode: truncate_insert
上記のようにinputに記載のqueryで転送データを定義しています。
digファイルに対象テーブル名(=liquidファイル名)をymlの配列型式で指定し、Embulkを実行します。検証データが増えた際にテーブルが増やせるようにするためです。
TestDataCampaignA_postgres.dig
timezone: Asia/Tokyo +prepare_environment: !include : sub/prepare_environment.dig _export: wf: name: Transfer production data to staging for testing campaignA campaign_id: campaignA target_table_names: - ranking +prod_to_staging_postgres: for_each>: target_table_name: ${target_table_names} _parallel: false _do: +psql_to_psql: !include : sub/run_embulk.dig
run_embulk.dig
_export: docker: image: ${embulk_docker_image} pull_always: true sh>: embulk -J-Duser.timezone=Asia/Tokyo run -b /var/lib/embulk config/${campaign_id}/postgres/${target_table_name}.yml.liquid
SQL Serverのデータ転送方法
Embulkを利用したかったのですが、以下のような壁がありました。
IDENTITY設定の壁
SQL ServerではIDENTITY設定されたカラムが存在するテーブルを転送する必要がありました。何も設定しない場合、insert時にエラーとなります。
例えば以下のようなテーブルをinsertした場合を考えてみます。
# IDENTITY設定されたテーブル作成 create table target_user(id integer identity primary key, name varchar(100)); # データinsert insert into target_user(id,name) values(1,'username');
すると、以下のようなエラーメッセージがでます。
[S0001][544] Cannot insert explicit value for identity column in table 'target_user' when IDENTITY_INSERT is set to OFF.
IDENTITY_INSERT設定がOFFの場合、IDENTITY設定のカラムの値は自動付与するので設定できないというエラーです。例だと、id=1の指定を外せばinsertができます。
今回はIDENTITY設定をされたカラムの値もそのまま転送したかったので、以下のようなステートメントを実行して、IDENTITY設定カラムに値を指定できるように設定し直す必要がありました。
SET IDENTITY_INSERT target_user ON;
同一セッション内でSET IDENTITY_INSERTを実行する方法が見つからなかったため、Embulk利用を断念しました。そのため、SQL Serverのデータはbcp(bulk copy program)を利用して転送する事にしました。
bcpを使ったデータ転送
bcpは一括でデータをコピーするユーティリティです。インポート時に-Eオプションをつける事で、IDENTITY設定カラムでも値を割り当てずにデータファイルの値を利用するため、転送が可能になります。
さらにデフォルトではトリガーを実行しないため、ヒントオプション-hにFIRE_TRIGGES引数を指定する事でインポート時にinsertトリガーを実行します。
インポート前に重複データを削除する際にはsqlcmdを利用しています。sqlcmdはコマンドラインからSQL文を実行できるユーティリティです。
以下のようなシェルを用意する事で転送を実現できました。
bcp_copy.sh
#!/usr/bin/env bash
set -e
BIN_PATH="/opt/mssql-tools/bin"
# 対象テーブル・条件のデータをエクスポート
${BIN_PATH}/bcp "SELECT * FROM rtm.dbo.${table_name} WHERE ${where}" queryout data.dat -N -S ${sqlserver_host},${sqlserver_port} -d rtm -U digdag -P ${secret_db_sqlserver_password}
# 重複エラーにならないよう、同条件のデータを削除
${BIN_PATH}/sqlcmd -S ${staging_sqlserver_host},${staging_sqlserver_port} -d rtm -U ${staging_sqlserver_user} -P ${secret_db_sqlserver_stg_password} -Q "DELETE FROM rtm.dbo.${table_name} WHERE ${where}"
# エクスポートしたデータをインポート
${BIN_PATH}/bcp rtm.dbo.${table_name} in data.dat -E -N -S ${staging_sqlserver_host},${staging_sqlserver_port} -U ${staging_sqlserver_user} -P ${secret_db_sqlserver_stg_password} -h FIRE_TRIGGERS
copy_sqlserver.dig
_export: table_name: ${condition.table_name} where: ${condition.where} docker: image: ${mssql-tools_image} sh>: tasks/bcp_copy.sh
ymlファイルを利用したデータ定義
bcpのシェルに記載の${table_name}と${where}に入る情報は、ymlファイル内に以下のようなjson形式でキャンペーンのケース毎にテーブル、条件を持たせています。
target.yml
- {table_name: User, where: user_id = 1111111} # 担当者のuser_id - {table_name: Item, where: 'item_id in (10000, 100001, 100002)'} # ランキングで利用する商品
SQL Serverデータ転送の場合、このtarget.ymlに検証データを定義しています。
ymlに記載した情報はRubyで以下のようにjson情報をパラメータとして渡します。
query_parameter.rb
require 'yaml' module Tasks class QueryParameter def load # digファイルで定義したcampaign_idパラメータ campaign_id = Digdag.env.params.fetch("campaign_id", 0) # データの定義ファイルを読み込む File.open("config/#{campaign_id}/sqlserver/target.yml", "r") do |f| params = YAML.load(f, symbolize_names: true) # 検証データの条件を後続タスク(bcp)で利用するため、Digdagのstoreパラメータとして格納 Digdag.env.store("sqlserver_conditions".to_sym => params) end end end end
query_parameter.dig
_export: docker: image: ruby:2.6.1 rb>: Tasks::QueryParameter.load require: 'tasks/query_parameter'
これらをdigファイルに記載してデータ転送を実現します。
TestDataCampaignA_sqlserver.dig
_export: wf: name: Transfer production data to staging for testing campaignA campaign_id: campaignA +prod_to_staging: +load_sqlserver_params: !include : sub/query_paramter.dig +loop_sqlserver: for_each>: condition: ${sqlserver_conditions} _do: +run_sqlserver_copy: !include : sub/copy_sqlserver.dig
以上がSQL Serverのデータ転送方法です。
これらのデータ転送機能を運用する中で以下の利点がありました。
検証データの定義を保持するドキュメントとしての有用性
データ転送機能で実装したクエリは、検証データの定義を保持するドキュメントとしても有用でした。
同じキャンペーン運用中に何か追加改修が必要になった場合は、同一データまたは追加の検証ケースを追記して検証ができるため、追加改修時の効率化も行えます。
私たちの場合は現在と未来の実装を正確に素早く行うための手段として、Digdagのデータ転送機能は適した手段でした。
改善した検証環境で検証を行うメリット
今回の経験により、整備された検証環境で検証を行うメリットとして以下が挙げられます。
- 本番稼働しているものを改修する際の検証が楽になる
- 修正と確認のリードタイムが短くなる
- 余計な監視通知を抑制できる
- 気付きが多くなる
本番稼働しているものを改修する際の検証が楽になる
検証環境で本番環境と同様の検証ができるようになった結果、既に動いてるキャンペーンに影響しないように検証するための試行錯誤を本番環境でする必要はなくなりました。
修正と確認のリードタイムが短くなる
事前に検証環境で検証ができるようになった結果、事前検証が可能になりリリース時の確認点を減らすことができました。検証をするのは検証環境なので本番に影響を与える事なく、迅速に修正・確認を実施できます。
余計な監視通知を抑制できる
監視担当に余計な負荷をかける行為からも脱却する事ができるため、全体の効率化にもつながります。
気付きが多くなる
作業効率が良くなり作業時間に余裕が生まれる事で本来考えるべき事へ集中できるようになります。実際に、検証環境ができてから仕様の過不足や必要な検証ケースについて担当者とやり取りをする機会が増えました。そのためキャンペーンの品質担保へも貢献できていると言えます。
以上のように、整備された検証環境の存在によって品質と効率を上げる事ができました。
まとめ
成功まで何度も失敗を繰り返すことのできる検証環境は、システムに慣れている人と慣れていない人の差をカバーする手段として大きく機能しました。
検証環境を利用した後の効率低下のリスクについては、CircleCIやDigdagを利用して効率化を上げる事でカバーできました。本番リリース特有の確認時間が減り、余計な監視通知もなくなるため、全体効率は上がっていると言えます。
さらにDigdagによるデータ転送自動化は、効率化だけでなく品質担保にも繋がりました。
皆さんも様々な方法で品質と効率のバランスを保つために試行錯誤していると思います。私たちのこういった運用改善が少しでも皆さんのお役に立てば幸いです。
おわりに
私たちは他にも多くのマーケティングに関わるシステムを開発・運用しています。今回のような環境整備も含めて、既存システムの品質と効率のバランスを保ちながら、新しい施策のための新規機能やリプレイスを検討しています。
興味を持たれた方は採用ページ等をチェックしてみてください!