



はじめまして、ZOZO研究所福岡の家富です。画像検索システムのインフラ、機械学習まわりを担当しています。
今回は画像検索システムでお世話になっているAnnoyについてじっくり紹介したいと思います。
目次
Annoyについて
Annoyは、SpotifyによるPython近傍探索ライブラリです。 github.com
弊社のテックブログでも以前に取り上げています。
今回は実装について紹介していきたいと思います。
近傍探索について
近傍探索が一般的に満たすべき機能は以下の通りです。
まずベクトルの集合Vを用意します。以降「登録ベクトル群」と呼び、この集合に含まれるベクトルは「登録ベクトル」と呼びます。
次に検索ターゲットのベクトルaと個数kを指定します。なお、aはVに含まれていなくて良いです。
そして、このとき集合Vからk個のベクトルをaから近い順に取ってくるというのが近傍探索の処理です。
とても単純に計算するならばaとの距離を各Vの要素ごとに計算し、ソートすれば良いです。しかし、それだとVに含まれるベクトルの個数nに比例して計算時間がかかってしまいます。
そのため、この計算を速くするというのが近傍探索ライブラリの役割です。だいたいlog(n)のオーダー程度になることが望まれていると考えて良いです。
Annoyの性能に関しては、他の近傍ライブラリと比べて特別速いといったことはありません。しかし、メインとなるのはannoylib.hの1500行とannoymodule.ccの700行程度でコード量が少なく、他ライブラリに対する依存もないため、OSS入門として取り扱いやすいものとなっています。
Annoyのソースコードを読むときのポイント
ソースコードを読む際に、どこから読めばいいか迷うと思います。一般的には、わかるところから、もしくは興味あるところからになると思います。Annoyの場合、私はREADMEにある以下の実行サンプルをスタート地点としました。
from annoy import AnnoyIndex import random f = 40 t = AnnoyIndex(f, 'angular') # Length of item vector that will be indexed for i in range(1000): v = [random.gauss(0, 1) for z in range(f)] t.add_item(i, v) t.build(10) # 10 trees t.save('test.ann') u = AnnoyIndex(f, 'angular') u.load('test.ann') # super fast, will just mmap the file print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
参考:Python code example | spotify/annoy
このコードがやっていることは、以下の通りです。
AnnoyIndexというクラスのインスタンスを作る。- ベクトル(
f=40次元)を1000個ランダムに抽出し、「登録ベクトル群」として入れて、検索高速化のための構造(インデックス)を作る。 - 作成したインデックスを
test.annというファイル名で保存。 - 新しいインスタンスを作成し、作成したファイルからインデックスを読み込む。
- 読み込んだインデックスを利用して、0番目のベクトル(最初のベクトル)と近いもの順に並べたベクトル群を出力。
このコードの各実行部分がソースコードのどこにあたるのかを見ていけば良いかなという発想で読んでいきました。
AnnoyIndexというクラスのインスタンスを作る
インスタンス生成では、以下のコードにおいて定義されるAnnoyIndexを呼んでいます。
from .annoylib import Annoy as AnnoyIndex
参考:__init__.py | spotify/annoy
.annoylibがどこからきているかというと、以下のコードからきています。
github.com
このコードを読んでいくには、もう1つPythonのC/C++拡張についての理解が必要です。そのために、まずAnnoyの「インストール過程について」紹介し、その次に「PythonのC/C++拡張」を紹介します。
インストール過程について
Annoyは通常、pipを使って以下のコマンドでインストールします。
pip install annoy
これはソースコードを手動でダウンロードして、以下のコマンドを走らせることと同様です。
python setup.py install
setup.pyでの主要部分は以下の部分です。
... setup(name='annoy', version='1.17.0', description='Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk.', packages=['annoy'], ext_modules=[ Extension( 'annoy.annoylib', ['src/annoymodule.cc'], depends=['src/annoylib.h', 'src/kissrandom.h', 'src/mman.h'], extra_compile_args=extra_compile_args, extra_link_args=extra_link_args, ) ], ...
参考:setup.py#L75-L86 | spotify/annoy
packages=['annoy']の部分はカレントディレクトリのannoyというディレクトリをそのままモジュールとして使うことを意味しています。このディレクトリに先程の__init__.pyがあります。
ext_modulesの部分はannoyディレクトリ以下にannoylibを作ることを意味しています。ライブラリの具体的形式はOS環境により変わりますがsetup関数がよしなに処理してくれます。
このときに使うソースがsrc/annoymodule.ccです。
dependsの部分はビルドする際に、src/annoylib.h、src/kisssrandom.h、src/mman.hを必要としていることを示しています。この設定により、OS環境に応じたC/C++コンパイラとそのコンパイル、リンクオプションを自動で設定して、ライブラリを作成してくれます。
上記のようにメインのソースはsrc/annoymodule.ccであり、このソースは「PythonのC/C++拡張」によって書かれているため、次に「PythonのC/C++拡張」について紹介します。
PythonのC/C++拡張
C/C++のコードをPythonから使えるようにする仕組みは大きく分けると、以下の2種類があります。
1つ目がctypesを使う方法です。
2つ目は、PythonのC/C++拡張を使う方法です。
他にはSWIGを使うという方法がありますが、これは上記のPythonのC/C++拡張のためのインタフェース部分を作成するツールです。 ja.dbpedia.org
重要な違いはインタフェースを整える部分をPython側でやるか、C/C++側でやるかの違いです。すでにC/C++のライブラリがある場合はctypesを使ってPython側で調整してやるという方法が簡易です。Pythonライブラリとして公開したいが、ランタイム速度を求める場合などはPythonのC/C++拡張を使い、C/C++側で調整する方法が速度的に有利だと考えられます。
Annoyは後者のPythonのC/C++拡張を使う方法を採用しており、以下のようにモジュールを公開しています。
#if PY_MAJOR_VERSION >= 3 PyMODINIT_FUNC PyInit_annoylib(void) { return create_module(); // it should return moudule object in py3 } #else PyMODINIT_FUNC initannoylib(void) { create_module(); } #endif
参考:annoymodule.cc#L627-L635 | spotify/annoy
Pythonのバージョンが3なのか、2なのかで公開方法が多少異なりますが、2系統は開発が終了しているため、3の方法を確認しておけば問題ありません。
公開するモジュールはcreate_moduleにおいて、以下で作成したオブジェクトを返すようにします。
PyObject *m;
...
m = PyModule_Create(&moduledef);
参考:annoymodule.cc#L608-L616 | spotify/annoy
Annoyの場合、重要なのはAnnoyクラスを登録するところであり、以下の部分です。
PyModule_AddObject(m, "Annoy", (PyObject *)&PyAnnoyType);
参考:annoymodule.cc#L623 | spotify/annoy
ここでannoyモジュールのAnnoyクラスとしてPyAnnoyTypeで設定したものをモジュールに加えています。
PyAnnoyTypeを定義する上で重要な点は以下の通りです。
- クラスインスタンスのメモリ容量の登録:
sizeof(py_annoy) - インスタンスのデストラクタの登録:
(destructor)py_an_dealloc - クラスのメソッドの登録:
AnnoyMethods - クラスのメンバーの登録:
py_annoy_members - インスタンスの初期化関数(下記のメモリ確保関数の後に呼ばれる。Pythonの
__init__の呼ばれるタイミング)の登録:(initproc)py_an_init - インスタンスのメモリ確保関数の登録:
py_an_new
上記のpy_an_newまわりはPythonオブジェクトからC/C++用のデータを取り出す場合、どのように実装すればいいか、とても参考になります。
AnnoyはAnnoyクラスを管理するモジュールになっているため、動作を見る上で一番注意すべきところはpy_an_newです。なお、py_an_initではチェックのみです。
距離構造を指定するパラメータmetricについては、画像検索システムではangularを使っているので、ここからはmetric=angularと指定されているとしてコードを見ていきます。
py_an_newでは以下のようにインスタンスを生成して、ptrメンバーに設定されていることがわかります。
new AnnoyIndex<int32_t, float, Angular, Kiss64Random, AnnoyIndexThreadedBuildPolicy>(self->f);
参考:annoymodule.cc#L153 | spotify/annoy
AnnoyのPythonのメソッドと、C/C++コードのメソッドの対応はAnnoyMethodsを見ることで対処できるので、以降はC/C++コード部分であるsrc/annoylib.hを読んでいきます。
なお、C++のtemplateライブラリとして実装しているので、ヘッダーファイルが実装になっています。しかし、そこまで型を抽象化しているメリットは特にないように思います。
Annoyの実装
以降、引き続きmetricの設定としてangularが指定されているとしてコードを読んでいきます。
他のmetricの場合、さらにヒューリスティックな要素が大きく、コードを読む際にわかりにくいこともあるため、対象を絞りました。一通り読む際も、まずはmetricを固定して一読した方が良いです。
アルゴリズムを理解する上で重要となるAnnoyIndexクラスのメソッドは以下の3つです。
add_item: 検索対象となるベクトルの登録build: 登録されたベクトルに対する検索を高速化するための構造の作成get_nns_by_vector: 登録されたベクトルに対する検索
C++コードにおいても、メソッド名はPythonインタフェースと同名のメソッドとなっています。
上記のメソッドを紹介する前に、AnnoyIndexのメンバーを簡単に説明しておきます。
const int _f; // 登録するベクトルの次元(e.x. 512) size_t _s; // nodesの要素のバイトサイズ S _n_items; // 「登録ベクトル群」に登録されているベクトルの個数 void* _nodes; // Nodeインスタンスの配列で、buildで作られるインデックス構造は、このNodeからなるtreeの集合 S _n_nodes; // 実際に登録しているNodeの個数 S _nodes_size; // _nodesが確保している配列の長さで、_n_nodesよりも一般に大きく取られる。この辺りはメモリを気にするC/C++特有のメンバー vector<S> _roots; // buildで作られる複数のtreeの各ルートを保持した配列 S _K; // ひとつのNodeに何個のIDを保持できるかを表した数。末端の1つ上のNodeに対して重要な使われ方をする int _seed; // 乱数のシード。 buildにおいて乱数が使われるので必要となる bool _loaded; // ファイルからロードされたかどうか bool _verbose; // 出力モードフラグ。trueなら出力が丁寧だが量が多くなる int _fd; // ファイルからインデックスをロードする際に使われる bool _on_disk; // _nodesをディスクにおく場合はtrue bool _built; // buildが呼ばれる前か呼ばれた後かを表すフラグ
参考:annoylib.h#L869-L882 | spotify/annoy
なお、登録ベクトルの個数_n_itemsと検索に使うNodeの個数_n_nodesの違いは重要です。
アルゴリズムとしてはNodeのメンバーも重要なので、buildの説明の際に行います。
1. add_item
ここでは、まず、登録ベクトルに対応するNodeインスタンスを作成を行います。IDの割り振りと、ベクトル値の登録をします。
次に、_nodesメンバーに、先程作成したNodeインスタンスを追加します。このとき、_nodesに割り当てているメモリが足りない場合は確保し直します。
buildのフェーズにおいてはNodeとして、ベクトルに対応しないものを登録していきます。そのためNodeは登録ベクトルに対応するものと、しないものを見分けるためのメンバーが必要になりますが、その役割をn_descendantsが行います。この値が1のときは登録ベクトルであるということになります。それ以外の値に関しては次の「2. build」で説明します。
2. build
目的は以下のデータ構造を作ることになります。「3. get_nns_by_vector」でデータ構造の詳細と使われ方を説明した後、「4. build再考」にて実装の説明をします。
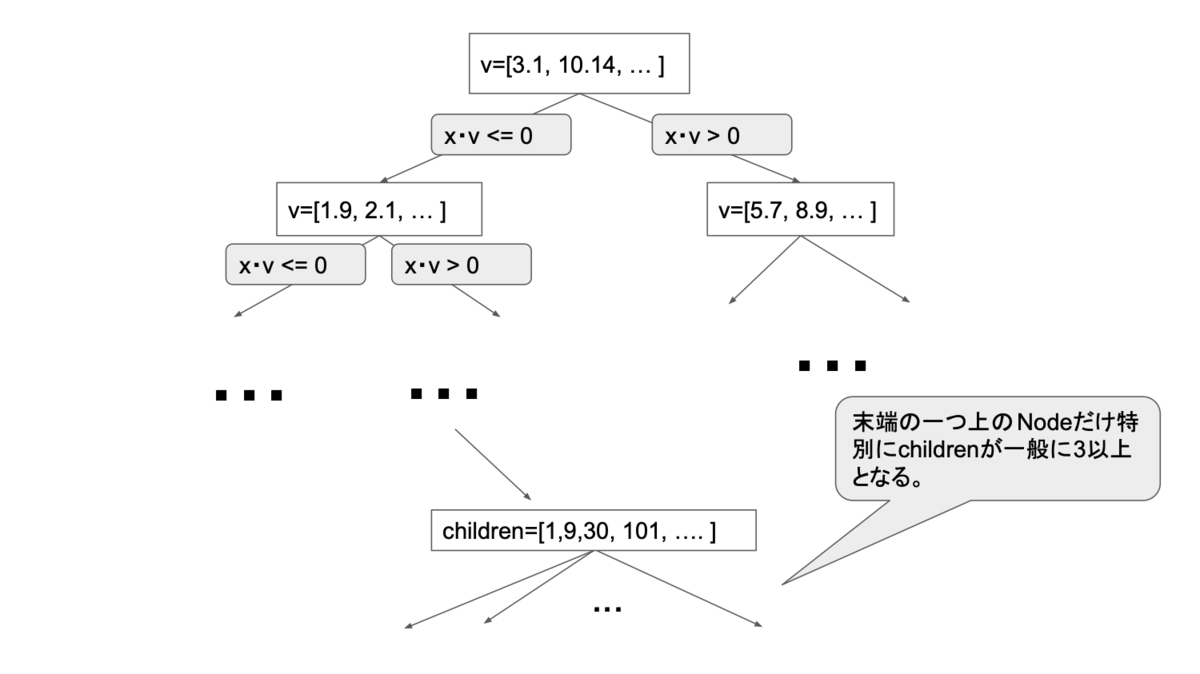 上図のようなtreeの構造についてまず説明します。
上図のようなtreeの構造についてまず説明します。
Nodeは大きく、3つに分けられます。
末端
Node「登録ベクトル群」に属するベクトルと対応します。
末端の1つ上の
Node末端
NodeのIDの配列を保持します。その他の
Nodechildrenとして子Nodeを2つ保持します。この2つの子Nodeのどちらかを辿っていけば、登録したベクトルに行き着くようにtreeを作成します。このNodeでのベクトルvは、ある登録したベクトルが子Nodeのどちらにあるかを示すために使用します。ベクトルxがx・v<=0のとき、children[0],x・v>0のとき、children[1]の方から辿れるようにNodeを構成します。
探索中に辿っているNodeが上記3つのNodeのどれにあたるのか識別する必要がありますが、それはn_descendantsというNodeのメンバーを見ることで判断しています。n_descendantsは、そのNode以下にたどり着く登録ベクトルが何個あるのかを表しています。
n_descendants=1ならば、末端Noden_descendants<=_Kならば、末端の1つ上のNode_Kの決め方が特殊なので「4. build再考」にて説明しますそれ以外ならば、中間の
Node
上記の判断を行っているコードは、以下の部分がわかりやすいです。
if (nd->n_descendants == 1 && i < _n_items) { nns.push_back(i); } else if (nd->n_descendants <= _K) { const S* dst = nd->children; nns.insert(nns.end(), dst, &dst[nd->n_descendants]); } else { T margin = D::margin(nd, v, _f); q.push(make_pair(D::pq_distance(d, margin, 1), static_cast<S>(nd->children[1]))); q.push(make_pair(D::pq_distance(d, margin, 0), static_cast<S>(nd->children[0]))); }
参考:annoylib.h#L1365-L1374 | spotify/annoy
3. get_nns_by_vector
実際には、さらに「2. build」で説明したようなtreeを複数個作り保持します。なぜ複数必要なのかは後で説明します。
このように複数のtreeが構成された状態で検索アルゴリズム本体である_get_all_nnsが呼ばれます。
検索ターゲットのベクトルaに対して、各treeをどのように探索していくかを見ていきます。末端に到達するまでは各中間のNodeにおいてどちらのchildrenのNodeを辿るべきかを判断する必要があります。
ここでa・vの値を計算し、a・v>0だったらchildren[1]、a・v<=0だったらchildren[0]を探索していきます。
これはchildrenを構成する際に、登録するベクトルxに対してx・v>0だったらchildren[1]、x・v<=0だったらchildren[0]の方に入れていくように構成するからです。具体的な構成方法は、「4. build再考」で紹介します。
厳密に計算するならば、探索ターゲットのベクトルaと「登録ベクトル群」に属するベクトルxの内積を調べる必要があります。しかし、それでは計算量が多くなるので代わりにv・x>0となる代表ベクトルvとの内積a・v>0かどうかを使って、近似的に近くになるだろうベクトル群を探します。「a・v>0、x・v>0、ならば、まあだいたいa・x>0だろう」という感覚です。vを基準として反対側よりも同じ側にあるベクトル群から探した方が近いものを見つけられるだろうという捉え方もできます。

「登録ベクトル群」の個数がnのとき、treeがうまく作られていれば、理想的にtreeのルートから辿るNodeの個数はlog(n)となるため、高速に検索できるということです。
ここで複数のtreeを用意する理由を考えます。
1つのtreeとした場合、あるNodeのvとの内積が0となるところ(以降、「際」と呼ぶ)の近くに検索ターゲットのベクトルaがある場合、問題が生じます。このようなベクトルaに対して、childrenのどちら側のベクトル群もそれぞれ、aと近いベクトルを含む事態が生じるためです。
このような「際にあるベクトル」は一般的にはいくらでも存在します。各Nodeのvを基準とした場合に、検索ターゲットのベクトルaが「際」に近いベクトル(内積が0に近い)となる可能性を低くするため複数のtreeが必要になります。そのため、buildのパラメータqは、大きければその分精度向上しますが、その分検索速度が落ちます。
では実際に探索するコードを見ていきます。
std::priority_queue<pair<T, S> > q; if (search_k == -1) { search_k = n * _roots.size(); } for (size_t i = 0; i < _roots.size(); i++) { q.push(make_pair(Distance::template pq_initial_value<T>(), _roots[i])); } std::vector<S> nns; while (nns.size() < (size_t)search_k && !q.empty()) { const pair<T, S>& top = q.top(); T d = top.first; S i = top.second; Node* nd = _get(i); q.pop(); if (nd->n_descendants == 1 && i < _n_items) { nns.push_back(i); } else if (nd->n_descendants <= _K) { const S* dst = nd->children; nns.insert(nns.end(), dst, &dst[nd->n_descendants]); } else { T margin = D::margin(nd, v, _f); q.push(make_pair(D::pq_distance(d, margin, 1), static_cast<S>(nd->children[1]))); q.push(make_pair(D::pq_distance(d, margin, 0), static_cast<S>(nd->children[0]))); } }
参考:annoylib.h#L1348-L1375 | spotify/annoy
なお、std::priority_queueのtopメソッドはデフォルトでは一番大きい値のものを返します。
各treeにおいては、ルートからそのNodeまでに通るすべてのNodeで「際」に最も近いもの(最も内積の値が小さいもの)をqに入れます。コード上ではこの値をmargin(「際」からの距離)と呼んでいます。
q.topでこの値の「一番大きなもの」を取り出すという操作をしていますが、これは「際」から最も遠いものを選んでくることに対応します。同時に内積が負になるもの(つまり検索対象のベクトルaと反対側にあるもの)も取り除いています。
各treeの内部においては一番小さいものをとり、tree同士の比較では一番大きいものを取り出すというところで、混乱しやすいので注意が必要です。
できるだけ「際」に近いNodeは辿らず、「際」から遠いNodeを辿っていった方が近傍探索の精度は高くなるという発想です。
このように各treeから、より近いベクトルが含まれてそうな「末端の1つ上のNode」を取り出し、それ以下のNodeをnnsに入れます。ここでnnsに入れられるNodeはそれぞれ「登録ベクトル群」に属するベクトルと対応します。あとはnnsに入れられたベクトルとaの距離を求めて、ソートして返すだけです。この部分はstd::partial_sortで実装されており、一般的にはヒープソートで実装されているようです。
よって、返すベクトルの個数をMとした場合、nnsに対する操作のオーダーはM・log(M)と考えられます。
4. build再考
「3. get_nns_by_vector」で述べたようなアルゴリズムを実行するためにtreeを構成する必要があります。ここで重要なのは、登録されたベクトルを分けるためのベクトルvです。このときtreeの高さを抑えるため、ひいては検索速度をあげるため、「登録ベクトル群」をおおよそ半分に分けるベクトルvが望まれます。
また複数treeを作った際に、それぞれのtreeができるだけランダムな方が望ましいです。そうすることで、検索ターゲットのベクトルがすべてのtreeにおいて「際」になるようなケースを確率的に減らすことができます。
Annoyはrandom projectionを使ってtreeを構成し、そのtreeで検索するアルゴリズムです。一般的に近傍探索アルゴリズムにおいて、random projectionの取り方、treeの実装方法は多岐に渡ります。
ここではAnnoyの実装を述べます。Annoyでのrandom projectionに相当する、vの取り方はcreate_splitという関数で実装しています(参考:annoylib.h#L486-L493 | spotify/annoy)。
さらにこの中のtwo_meansという関数がメインです。
template<typename T, typename Random, typename Distance, typename Node> inline void two_means(const vector<Node*>& nodes, int f, Random& random, bool cosine, Node* p, Node* q) { /* This algorithm is a huge heuristic. Empirically it works really well, but I can't motivate it well. The basic idea is to keep two centroids and assign points to either one of them. We weight each centroid by the number of points assigned to it, so to balance it. */ static int iteration_steps = 200; size_t count = nodes.size(); size_t i = random.index(count); size_t j = random.index(count-1); j += (j >= i); // ensure that i != j Distance::template copy_node<T, Node>(p, nodes[i], f); Distance::template copy_node<T, Node>(q, nodes[j], f); if (cosine) { Distance::template normalize<T, Node>(p, f); Distance::template normalize<T, Node>(q, f); } Distance::init_node(p, f); Distance::init_node(q, f); int ic = 1, jc = 1; for (int l = 0; l < iteration_steps; l++) { size_t k = random.index(count); T di = ic * Distance::distance(p, nodes[k], f), dj = jc * Distance::distance(q, nodes[k], f); T norm = cosine ? get_norm(nodes[k]->v, f) : 1; if (!(norm > T(0))) { continue; } if (di < dj) { for (int z = 0; z < f; z++) p->v[z] = (p->v[z] * ic + nodes[k]->v[z] / norm) / (ic + 1); Distance::init_node(p, f); ic++; } else if (dj < di) { for (int z = 0; z < f; z++) q->v[z] = (q->v[z] * jc + nodes[k]->v[z] / norm) / (jc + 1); Distance::init_node(q, f); jc++; } } }
参考:annoylib.h#L364-L407 | spotify/annoy
引数のnodesは分ける対象となるベクトル群を表しています。まず、2つのベクトルをnodesからランダムに取り出してp、qにセットします。次に200個のベクトルをランダムに取り出し、p、qの近い方に足して、足した方を平均化します。
これは以下の操作に相当します。
nodesから200個のベクトルをランダムに取り出しk-meansで2つのグループに分ける。- それぞれのグループの中心ベクトルを
p、qとする。
ここは厳密なアルゴリズムではなく、ヒューリスティックに分けています。一般的にk-meansアルゴリズムはヒューリスティックなものです。
このようにp、qを求めて、その差分をvとして設定しています。確率的にnodesに属していたベクトルを内積で2分するようなベクトルになっていると考えられます。

上記を踏まえてbuildを読んでいきます。
thread_buildというメソッドがメインになっています。元々はbuildによる実装でしたが、Annoyが1.17.0より並列コードを追加したため、thread_buildというメソッドになりました。1.16.3のバージョンのコードと比較してみるとわかりやすいです。thread_build_policyというものを用いてthreadが共有するデータ構造に対してロックをかけながら実行するコードになっています。最初に読む場合、これらは無視して進むと読みやすいです。実際のところ、具象クラスのAnnoyIndexSingleThreadedBuildPolicyの実装の場合、lockメソッドは何もしていません。
では引き続きthread_buildを読んでいきます。thread_buildはindicesというローカル変数に「登録ベクトル群」を詰め込んで_make_treeを呼びます。
この_make_treeがtree構造作成のメインになります。create_splitによって区分けするためのベクトルを作り、再帰的にindicesを2つのグループに分けるNodeを作っていきます。
なお、正確にはtree構造が偏ってしまい、うまく分けられない場合がときおり生じます。そのための処理も入っています。
ここで「末端の1つ上のNode」に関して_Kについて実装を説明します。使われている部分として以下のif文があります。
if (indices.size() <= (size_t)_K && (!is_root || (size_t)_n_items <= (size_t)_K || indices.size() == 1)) { ...
参考:annoylib.h#L1248 | spotify/annoy
残りのindicesの個数が少ない場合、「末端の1つ上のNode」を作成するときに処理される部分です。_K以下というところがポイントで、この_Kは以下で定義されています。
_K = (S) (((size_t) (_s - offsetof(Node, children))) / sizeof(S)); // Max number of descendants to fit into node
参考:annoylib.h#L889 | spotify/annoy
かなりアドホックですが、_Kは以下の式の値を計算しています。
(Node構造体のchildren以下のメンバーが保持するバイト数) / (Sのバイト数)
これはchildren以下のメモリ領域にSのインスタンスを何個保持できるかを表しています。この値を使うことで、残りのNodeのIDをchildren以下のメモリ領域に保持できるかを判断しています。
そして可能な場合は実際にNodeのIDの配列をchildren以下にコピーし、「末端の1つ上のNode」を作り出します。Nodeクラスのchildren[0]、children[1]、vの領域を配列として使っていて、メモリ破壊的な使い方をしています。しかし、一応、C++のstd::vectorはメモリ上に連続的に配置しなければならないという規約があるので大丈夫なようです。
以上、コードを読む際にひっかかりやすそうな部分を紹介しました。
他に問題となる点について
CPU依存部分
バージョン1.16.0以降、Annoyは内積計算の部分でAVX512命令があるCPUにおいてはAVX512命令を使うようになっています。
template<> inline float dot<float>(const float* x, const float *y, int f) { float result = 0; if (f > 7) { __m256 d = _mm256_setzero_ps(); for (; f > 7; f -= 8) { d = _mm256_add_ps(d, _mm256_mul_ps(_mm256_loadu_ps(x), _mm256_loadu_ps(y))); x += 8; y += 8; } // Sum all floats in dot register. result += hsum256_ps_avx(d); } // Don't forget the remaining values. for (; f > 0; f--) { result += *x * *y; x++; y++; } return result; }
参考:annoylib.h#L210-L230 | spotify/annoy
これによって高速にはなるのですが、ビルド環境と実行環境において使用しているCPUに差が出るようなコンテナ運用などをしている場合、動かないことがあるので注意が必要です。
なお、AVX512ではないですが、AVX2に対しても同様の問題がありました。 github.com
実際に、画像検索システムではGitHub Actionsでビルドを行っているのですが、以下のような問題が生じました。
ビルド時にはAVX512命令をもっているCPUを割り当てられ、実行環境においてはAVX512命令がないCPUだったので、セグメンテーションフォルトとなることがありました。幸いテスト環境なので運用に支障はありませんでした。
解決方法としては以下の2つが考えられます。
- 使用するAnnoyのバージョンを落とす
- ビルド時に環境変数ANNOY_COMPILER_ARGSをコンパイルオプションとして指定する
AVX512を抑制するgccの最適化オプションを調べるのは難しく、画像検索システムにおいては現状使用するAnnoyのバージョンを1.15.2としています。
ディスクかメモリか
ファイルにセーブしたデータをロードするコードはmmapを使ったコードになっています。これはdisk cacheを使っているのでメモリから追い出される可能性があります。また、経験上、disk cache自体の速度が不安定という問題があります。
弊社瀬尾の以下の記事に問題となった部分の詳細と対応が述べられています。 docs.google.com
まとめ
Annoyは依存ライブラリがなく、コード量もそこまで多くないため非常にとっつきやすいコードとなっています。そのため、数値計算のOSSの入門として、とてもおすすめです。
また、その他の近傍探索ライブラリのコードを読む際にも、基準とするには良いコードです。
さいごに
ZOZOテクノロジーズでは、ZOZO研究所のMLエンジニアも募集しております。 hrmos.co