



はじめに
こんにちは。検索基盤部 検索技術ブロックの今井です。
検索基盤部では検索機能や検索精度を改善する中で検索クエリの意図解釈にも取り組んでいます。ZOZOTOWNで検索窓にクエリを入力して検索ボタンを押すと、クエリに応じて検索の絞り込み条件に変換するクエリ解釈機能の処理が動作します。
例えば、「ワンピース 白色」と検索した時、「ワンピース」を洋服のカテゴリー、「白色」を色のカテゴリーと解釈し、「白色のワンピース」を検索する絞り込み条件に変換します。
2024年5月現在ではスマートフォン向けWebサイト(https://zozo.jp/sp/xxx)とアプリのみ、クエリ解釈機能の処理が適用されています。クエリ解釈機能では意図解釈や検索の絞り込み条件に変換しています。
現在はシンプルな辞書ベースの手法を用いていますが、カバーしきれない課題も出てきており、改善のモチベーションが少しずつ上がってきています。本記事ではこれまでのクエリ解釈の取り組みについてシステム面も含めて紹介します。
目次
クエリ解釈について
クエリ解釈は、検索の精度改善を目的として、検索者が入力したクエリの意図を解釈し、検索条件に変換します。クエリ解釈機能は以下のような処理フローで実現され、検索者の意図に沿った検索結果を返すことを目指しています。
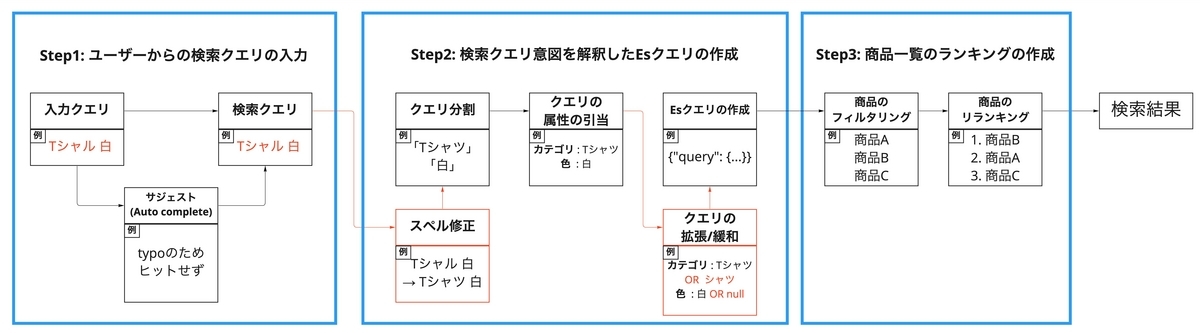
ZOZOTOWNでは一部のみを導入し、全ての処理の導入までは至っていませんが、いずれは全て導入してクエリ解釈を強化したいと考えています。
以前弊社のテックブログ「ZOZOTOWN検索の精度改善の取り組み紹介」でも紹介している下記の外部記事で詳しく解説されていますのであわせてご参照ください。
※クエリ解釈は英語でquery understanding (wikipedia)と呼ばれています。
従来のZOZOTOWNのクエリ解釈機能
ZOZOTOWNには10年ほど前からクエリ解釈機能が導入されていました。
導入背景
導入に至った背景としては以下2つの観点がありました。
- 検索の精度改善の観点
- 検索エンジンに対してキーワードマッチで検索するよりも、特定カテゴリのID等で検索結果を絞った方が検索精度の向上が期待できるため
- SEO観点
- キーワード検索の検索結果ページに遷移するよりも、ブランドページやカテゴリページに遷移した方がSEO観点で良いとされるビジネス的な要件のため
これらの観点が元となって導入された機能は以下です。
- クエリ文字列から特定の絞り込み条件に変換する仕組み
- 特定ページへのリダイレクトURL構築(Web用)
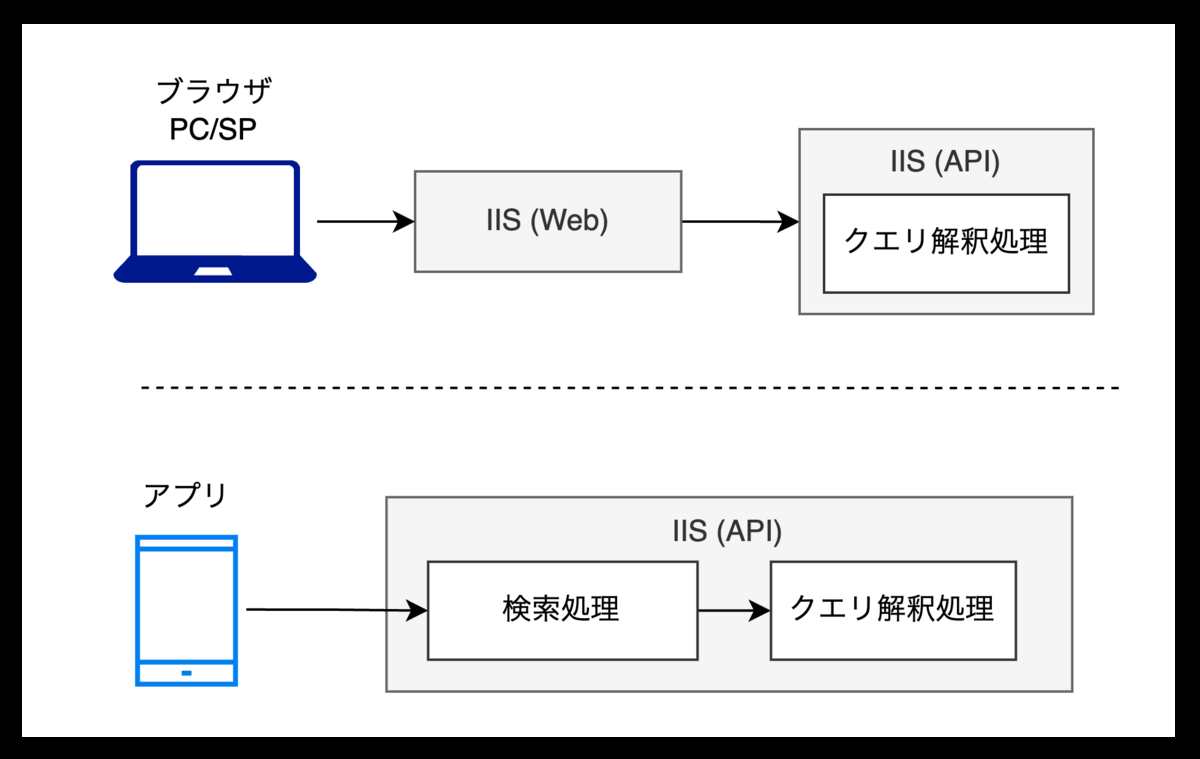
アーキテクチャ
クエリ解釈機能が導入されたシステムアーキテクチャは以下です。この機能はClassic ASPで実装されています。
クエリ解釈機能のロジック
先述の通り、クエリ解釈機能で用いる手法はシンプルな辞書ベースの変換手法を用いています。以下は辞書のイメージです。
| ターム | 意図エンティティタイプ | 意図エンティティ名 | 意図エンティティID |
|---|---|---|---|
| ジャケット | category | "jacket" | 1 |
| パンツ | category | "pants" | 2 |
| zozo brand | brand | "ZOZO BRAND" | 11 |
| zozo shop | shop | "ZOZO SHOP" | 21 |
| zozo brandshop | brand | "ZOZO BRANDSHOP" | 12 |
| shop | "ZOZO BRANDSHOP" | 22 | |
| ... |
検索条件の構築までの流れは以下です。タームによっては複数意図を持つタームも存在します。(e.g. 上記の表の"zozo brandshop")
- クエリ
ジャケットを入力する - 辞書内のターム一覧から
ジャケットに完全一致でマッチした辞書エントリーを取得する - 取得した辞書エントリーから
カテゴリエンティティ(カテゴリ意図)であること、そのidが1であることを認識する- 辞書エントリーによっては複数エンティティに紐づいていることがある
- 検索エンジンにリクエストする絞り込み条件として
category_idに1をセットする- 複数エンティティが存在する場合、優先意図の考慮や絞り込み条件同士の整合性が取れているかなどをチェックして一意に絞り込む
導入しているクエリ解釈機能の中には、以下3つの処理が含まれています。
| 処理 | 説明 |
|---|---|
| クエリ分割(Query Segmentation) | スペース区切りの文字列を意味のあるまとまりごとに扱うようにするために判定・分割する。 e.g. ・クエリ「ジャケット」→「ジャケット」としてセグメント化 ・クエリ「zozo brandshop 春服」→「zozo brandshop / 春服」として分割しセグメント化 |
| クエリの属性の引当(Entity Recognition) | セグメント化された各文字列がどの属性のタームなのかをエンティティとして識別する。 e.g. ・「ジャケット」→「カテゴリ:jacket(ID:1)」を属性として識別 ・「zozo brandshop 春服」→「ブランド:ZOZO BRANDSHOP(ID:12)」「ショップ:ZOZO BRANDSHOP(ID:22)」「キーワード:春服」を属性として識別 |
| 絞り込み検索条件の構築(Query Scoping) | 識別されたタームを検索条件に変換する。検索エンジンに応じてクエリ要素へのマッピング内容が変わる。 e.g. ・「カテゴリ:jacket(ID:1)」→「カテゴリID:1」の絞り込み条件に変換 ・「ブランド:ZOZO BRANDSHOP(ID:12)」「ショップ:ZOZO BRANDSHOP(ID:22)」「キーワード:春服」→「ブランドID:12」AND「キーワード:春服」の絞り込み条件に変換("zozo brandshop"をショップではなくブランド条件として検索する場合) |
課題
現行の辞書ベースの手法には、クエリ解釈精度面の課題があることが分かりました。特に、辞書にマッチしたタームが以下のケースに該当する場合は、変換を控える必要があります。
- 誤変換されるケース
- 複数の変換候補があるにもかかわらず、特定の候補に変換することがある
- この誤変換によって、他の変換候補の検索結果が表示されなくなる問題も発生
- 同音異義語が存在するケース
- ワンピース(カテゴリ)、ワンピース(漫画)は、カテゴリに変換するとワンピース(漫画)関連の商品が表示されなくなる
- 文字列長が短いケース
- 1文字、2文字など短いタームを変換してしまうため、検索者が意識せずたまたま入力したタームに対して誤ったまま変換してしまう可能性がある
これらの問題が発生した場合は1件ずつアドホックに対応してきました。ただし、このままだとアドホック対応をいつまでも続ける必要があるため、根本解決する必要があります。
根本解決に向けて進めるために、まずはレガシーな実装の問題を解決するところから進めようと考えました。現行のクエリ解釈機能を保守運用する中で以下のアーキテクチャ面の課題が出てきました。
- APIの管轄部署が検索基盤チーム以外であったため、改修や新機能の検証を気軽に出来なかった
- 実装がレガシー
- Classic ASPで実装されていたため、新規参画者に開発・保守運用の経験が少なく、学習コストが高かった
- モノリシックなレガシーAPIの1機能となっているため、改修による他影響を考える必要があった
- テストコードがないため、リグレッションに対して注視する必要があった
- アドホック対応
- 現状上記のような問題が発生したときに都度対応している
- ビジネス要件での変換依頼に対応することが時々ある
- 改善施策を施しABテストを実施するサイクルが回せていない
これらのアーキテクチャ面の課題を解決すべく、まずはクエリ解釈APIのリプレイスを実施し、変換の課題を解決するための環境を整えました。次項では、そのリプレイス対応について説明します。
クエリ解釈APIへのリプレイス
これらの課題解決の第一歩として、ZOZOTOWNのモノリシックなレガシーAPIの中からクエリ解釈の主機能を切り出し、クエリ解釈APIとしてリプレイスしました。このリプレイスではまず既存仕様を踏襲することとし、今後改善しやすいアーキテクチャを構築することを最優先としました。
このAPIは弊社技術スタックの推奨言語の1つであるGo言語で開発しました。採用理由としては、高速に動作することやGo言語開発の経験者による開発スピードの向上が期待できることなどが挙げられます。
リプレイス前後のシステムイメージは以下です。
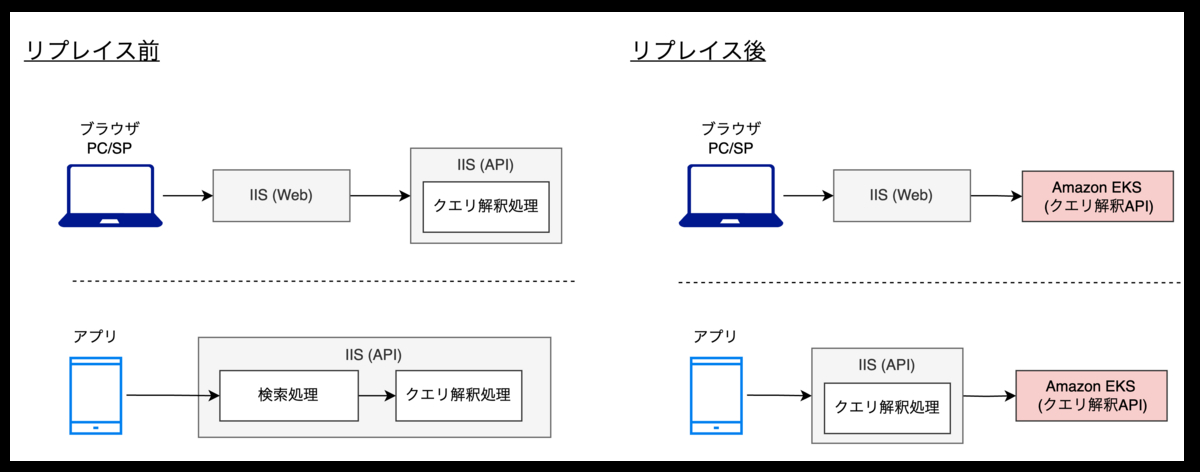
※ 辞書ファイルのレコード数は大規模ではないためKubernetesのPodに内包する形式を採用。そのため外部通信が発生せず安定かつ高速に動作。
クエリ解釈APIとして切り出すことで以下の恩恵が得られました。
- 機能追加、保守運用のし易さ
- リプレイス前は必要最低限の変更しか行われていなかったが、リプレイス後は問題の特定や影響範囲が分かりやすくなったこともあり定期的に改善が行われるようになった
- これにより「実装がレガシー」と「APIの管轄部署が検索基盤チーム以外であったため、改修や新機能の検証を気軽に出来なかった」の課題が解消された
- パフォーマンス向上
- リプレイス前のAPIが高速でなかったこともあったが、リプレイス前後で比較すると10倍以上高速に動作
- 辞書登録する内容を一部見直し、リプレイス前は検索時に逐次DB問い合わせして取得していた情報をリプレイス後では予め辞書登録しておくようにしたことも効果的であった
今回のリプレイスにより以下の課題を解消できました。
- 実装がレガシー
- APIの管轄部署が検索基盤チーム以外であったため、改修や新機能の検証を気軽に出来なかった
ただし、「アドホック対応」と「改善施策を施しABテストを実施するサイクルが回せていない」の課題の解消にはまだ至っていないため、引き続き解消に向けて取り組んでいきたいと思います。
辞書生成バッチについて
辞書ファイルは辞書生成バッチで生成していましたが、このバッチもClassic ASPで実装されていました。クエリ解釈APIのリプレイスに伴いバッチ側も同様にリプレイスを行いました。
具体的には、ワークフローエンジンに Vertex AI Pipelines を採用しPythonでバッチ処理を実装しました。
Classic ASPからVertex AI Pipelinesに乗り換えたことでワークフローエンジンとしての基本的な機能を得ることができ、保守運用を行いやすくなりました。以下は基本的な機能の例です。
- バッチ処理内のタスクの依存関係を定義できる
- 処理途中で失敗したタスクからリトライできる
- backfillが容易になる
データソースにはGoogle BigQueryとカスタマイズCSVファイルを利用します。Google BigQueryからはブランドやショップ、カテゴリなどの情報を取得します。これらのデータを用いて辞書ファイルを作成しGoogle Cloud Storageにアップロードします。
Google Cloud Storage上の辞書ファイルは、クエリ解釈APIのDockerコンテナイメージを作成するタイミングでダウンロードし内包しています。このDockerコンテナイメージからKubernetesのPodを作成・起動することで、外部通信が発生することなく安定かつ高速に動作します。
おわりに
本記事では、ZOZOTOWNでのこれまでのクエリ解釈の取り組みについて紹介しました。
クエリ解釈機能を従来のClassic ASPの実装からAPIとして切り出してGo言語でリプレイスしました。リプレイスではこれまでの仕様を踏襲したため依然として残っている課題も多々ありますが、切り出したことで改善しやすい状態に整えられました。
現在、クエリ解釈の次ステップの試みとして誤変換に対する課題を解決する手段などを検討・分析しています。この取り組みについても紹介できるようになり次第共有したいと思います。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。