
こんにちは、SRE部の谷口(case-k)です。私たちのチームではデータ基盤の開発や運用をしています。1年ほど前からBigQueryのコストパフォーマンス改善を目的にFlex Slotsを導入しています。
本記事ではFlex Slotsの導入効果や運用における注意点、ワークフロー設計についてご紹介します。BigQueryのコストやパフォーマンスで課題を抱えているチームや管理業務を行っている方の参考になれば幸いです。
BigQuery Reservationsとは
Flex Slotsを紹介する前に、まずBigQueryの費用を管理するプラットフォームであるBigQuery Reservationsをご紹介します。
BigQuery ReservationsとはBigQueryの費用や組織・プロジェクトのワークロードを管理するプラットフォームです。
BigQueryの料金モデルには「オンデマンド料金モデル」と「定額料金モデル」の2種類あります。オンデマンド料金モデルはBigQueryのクエリスキャン量に基づいた料金モデルです。一方、定額料金モデルの場合は事前にBigQueryのコンピューティングリソースであるスロットを購入する料金モデルです。
デフォルトではオンデマンド料金モデルが適用されます。オンデマンド料金モデルでは、1プロジェクトあたり2000スロットまで保証されますが、2000スロット以上は保証されていません。そのため、BigQuery全体で空きがあれば2000以上も使えますが、なければ使えません。つまり、データ量が多くなるにつれ、BigQuery Reservationsを使って定額料金モデルにする方が、コストメリットやパフォーマンスの恩恵を受けやすいと言えます。
Maximum concurrent slots per project for on-demand pricing — 2,000
引用:Quotas and limits | BigQuery | Google Cloud
BigQuery Reservationsを使って定額料金モデルにするには「コミットメント」「予約」「割り当て」が必要です。この操作をすることで、スロットの購入からプロジェクトへの割り当てが可能となります。
各操作の関係は以下のようになっています。
- コミットメントでスロットを購入し、予約でプロジェクトに対して割り当てるスロットを決める
- 予約したスロットに対して割り当てを行い、プロジェクトを紐付ける
- 紐付いたプロジェクトで、予約で確保したスロットを利用できるようになる
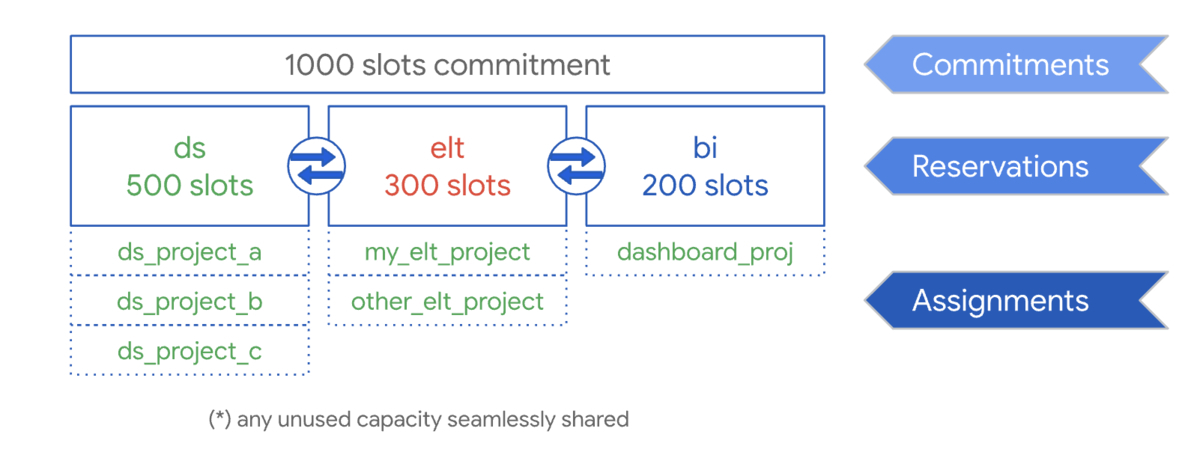 引用:Workload management using Reservations | BigQuery | Google Cloud
引用:Workload management using Reservations | BigQuery | Google Cloud
続いて、各操作の詳細を説明します。
コミットメント
コミットメントではBigQueryのコンピューティングリソースであるスロットを購入します。スロットの購入には次の3つの方法があります。
- 月次コミットメント
- 30日単位でスロットを購入
- 購入後30日間はキャンセルできない
- 年次コミットメント
- 365日単位でスロットを購入
- 購入後365日間はキャンセルできない
- Flex Slots
- 60秒単位でスロットを購入
- 購入から60秒後にはキャンセル可能なため、より柔軟にスロットを購入できる
スロットは100スロットから購入でき、100スロット単位で増やせます。なお、オンデマンド料金モデルは1プロジェクトあたり、2000スロットまでは保証されます。一方、定額料金モデルで2000スロット以下にするとパフォーマンスが落ちる可能性もあります。
BigQueryの利用状況によっては、2000スロット以上必要とすることはなく、その分コストを抑えたい場合もあるかと思います。その場合には、Cloud MonitoringやInformation Schemaを用いてBigQueryのスロット利用状況を確認することで、利用状況に応じた最適なスロット数を決めることができます。

Estimating how many slots to purchase
引用:Workload management using Reservations | BigQuery | Google Cloud
The minimum commitment size is 100 slots,
引用:Reservations details and limitations | BigQuery | Google Cloud
Note: On-demand pricing gives you access to 2,000 slots per Google Cloud project. With flat-rate pricing, you can commit to fewer than 2000 slots, but your queries might be less performant, depending on your workload demands.
引用:Introduction to Reservations | BigQuery | Google Cloud
予約
購入したコミットメントはバケットに対して割り当てられます。この操作を「予約」と呼びます。予約の操作では、どのくらいスロットを割り当てるか決めます。これをすることにより、購入したスロットをプロジェクトや組織に適用できるようになります。
例えば、2000スロット購入している場合、1000スロットを予約すれば、割り当てられたプロジェクトで1000スロットまで使えます。2000スロット全ての予約も可能です。なお、購入したスロット数以上の予約はできません。

割り当て
予約したスロットに対してGCPプロジェクトなどのリソースを割り当てます。この操作を「割り当て」と呼びます。リソースには組織、フォルダ、プロジェクトを割り当てることができます。企業で利用する場合に当てはめると、組織には会社名、フォルダには部署名、プロジェクトには部署で管理するGCPプロジェクトが該当します。なお、このリソースは継承関係を持ち、プロジェクトはフォルダの割り当てを継承し、フォルダは「組織」の割り当てを継承しています。この「割り当て」の有無で料金モデルが決まります。もし、オンデマンド料金モデルに戻したい場合は割り当てを削除します。
なぜFlex Slotsを使う必要があるのか
次にどうしてFlex Slotsを使う必要があったのか、弊社のデータ基盤が抱えていた課題を紹介します。
弊社でもデータの利活用が進んでおり、全てのデータをBigQueryに集める方針があります。集められたデータはデータ分析やML案件など幅広く用いられています。データの利活用が進むにつれ、BigQueryのデータ量やそれを扱う利用者も増加しました。データ量や利用者、BigQueryを使う案件も増えたことで「パフォーマンス」や「コスト」の課題が見えてきました。
- パフォーマンスの課題
- データマートなどのバッチ処理の集計が課題になっていた
- データ量が少ない時は必要な時間までにバッチ処理の集計を終えることができていたが、データ量や必要なデータマートが増えるにつれ、必要な時間までに集計を終えることができなくなった
- オンデマンド料金モデルではプロジェクトあたり2000スロットまでしか保証されないため、安定したパフォーマンスを得るためにはもっとスロットが必要だった
- コストの課題
- クエリ実行に伴うコストも上がっていた
- データの利活用が進むにつれ、データ量に加えてBigQueryの利用者も増え、オンデマンド料金モデルなので当然費用も上がった
- 利用者のBigQueryのリテラシーも人それぞれなので、あまり詳しくない人でもコストを意識せずに使えるように管理する必要があった
これらの課題を解決するためにFlex Slotsを導入しました。先に述べたようにFlex Slotsを用いることで、より柔軟にスロットを購入できます。60秒単位で購入のキャンセルができるため、重いバッチ処理など一時的に多くのスロットを使う場合に有効です。
従来の定額料金モデルには、年次コミットメントと月次コミットメントの2種類しかありませんでした。月次コミットメントを使えばコストを抑えることができますが、スロットを多く使うバッチ処理の集計を時間内に終えることができません。一方、月次コミットメントでバッチ集計に必要な量のスロットを購入すれば、集計を時間内に終えることができますが、コスト面でのデメリットが大きくなります。定額料金モデルが2種類しかなかった頃は、私たちのユースケースとは相性が良くありませんでした。
そこに、スロットの購入方法として新たにFlex Slotsが導入され、より柔軟なスロットの購入が可能となりました。スロットをあまり必要としないアドホックなクエリなどは、月次コミットメントでコストを抑えます。一方でバッチ処理の集計など多くのスロットが必要な時は、バッチ集計中のみFlex Slotsで必要なスロットを追加で購入し、割り当てることができます。Flex Slotsを導入することでパフォーマンス、コスト面の課題を解決することが可能になりました。
Flex Slotsを用いたコストパフォーマンス改善設計
私たちは月次コミットメント2000スロット、データマート集計前にFlex Slots 7000スロットを購入しています。データマート集計時は月次コミットメントで購入した2000スロットとFlex Slotsにて購入した7000スロット、合計9000スロットを割り当てます。本章では、管理プロジェクトの作成からFlex Slotsを用いたワークフロー設計まで、弊社の活用事例をご紹介します。

管理プロジェクトの作成
まず、BigQuery Reservations用の管理プロジェクトを作成します。既存のプロジェクトとは分けて管理用のプロジェクトを作ります。
そして、この管理プロジェクトを用いて、組織内の各プロジェクトにあるBigQueryのスロットを管理できるようにします。なお、管理プロジェクトではBigQuery Reservations APIを有効化する必要があります。
弊社では複数のGCPプロジェクトが存在しますが、現在BigQuery Reservationsを用いて定額モデルを採用しているのはデータ基盤のプロジェクトのみです。そして、権限は管理用のプロジェクトと割り当てプロジェクト両方で必要な点に注意しましょう。

Project-to-reservation assignment requires that you grant permission in both the administration project and the assignee projects. We recommend that you grant administrators the bigquery.resourceAdmin role at the organization or folder level.
引用:Reservations details and limitations | BigQuery | Google Cloud
月次コミットメントの活用
月次コミットメントを用いて、スロットの購入から予約、プロジェクトに対する割り当てまでの流れを説明します。Flex Slotsと違い、一度操作するだけで良いものなので、GCPコンソールから設定します。

最初にスロットの購入をします。GCPコンソールから、月次コミットメントを2000スロット購入します。

次に予約です。先ほど購入した2000スロットを全て予約します。予約では手持ちのスロットのうち何スロット割り当てるか決めます。弊社の場合、データ基盤用のGCPプロジェクト1つのみが対象なので、購入したスロット全てを予約しています。

最後に割り当てです。予約から割り当てを作り、スロットを割り当てるプロジェクトを選択します。そして、割り当てが完了すると、スロットを割り当てたプロジェクトはオンデマンド料金モデルから定額料金モデルに切り替わります。その結果、割り当て完了後には、弊社の環境の場合はデータ基盤のプロジェクトで2000スロットまで使うことができるようになります。

Flex Slotsの活用とワークフロー設計
コストパフォーマンスを改善させるために、Flex Slotsを用いてバッチ処理の前にスロットを購入し、完了後にスロットを破棄させるようにします。この制御はワークフローエンジンであるDigdagを用います。ここでは、Digdagのワークフローや実行してるタスクもご紹介します。
ワークフロー
Digdagで実行しているワークフローを紹介します。Digdagではコンテナイメージ内部でオペレータのタスクを実行できます。それを利用するために、GCPのサービスアカウントなどの秘密情報をDigdag Secretに登録し、タスク実行時に環境変数として渡しています。
タスクの流れを順に説明します。まず、バッチ処理の実行前にFlex Slotsで7000スロット購入します。次に、月次コミットメントで購入した2000スロットと合わせて9000スロット割り当てます。なお、割り当ては既に月次コミットメント適用時に作成済みなので、再度作る必要はありません。

+bigquery_flex_slots_up:
+bigquery_flex_slots_commitment:
_retry:
limit: 5
interval: 10
interval_type: exponential
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_purchase_commitment.sh 7000
+bigquery_flex_slots_reservation:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_reservation.sh batch 9000
続いて、購入完了後にワークフローエンジンでバッチ処理を実行します。バッチ処理完了後は再度予約で2000スロットに戻してから、Flex Slotsで購入した7000スロットを削除します。なお、2000スロットへ戻す前にFlex Slotsを削除してしまうと、予約で割り当てたスロットを満たすことができなくなり、エラーが発生します。

+bigquery_flex_slots_down:
+bigquery_flex_slots_reservation:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_reservation.sh batch 2000
+bigquery_flex_slots_removement:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_remove_commitment.sh
タスク
コミットメント、予約、割り当て実行しているタスクをご紹介します。
「コミットメントの購入」タスク
コミットメントの購入は以下のスクリプト bigquery_flex_slots_purchase_commitment.sh で行います。当時はbqコマンドしかサポートされていなかったため、bqコマンドを使っています。
admin_project_id=$ADMIN_PROJECT_ID
slots=$1
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq mk --project_id=${admin_project_id} --location=US --capacity_commitment --plan=FLEX --slots=${slots}
そして、スロットの購入に成功すると以下のようなログが出力されます。stateがACTIVEであれば、問題なく購入できていることを示しています。
name slotCount plan renewalPlan state commitmentStartTime commitmentEndTime
--------------------------------------------- ----------- ------ ------------- -------- ----------------------------- -----------------------------
admin-gcp-project:US.12697877815420638341 7000 FLEX ACTIVE 2021-07-06T01:03:56.570385Z 2021-07-06T01:04:56.570385Z
この状態でGCPコンソールを確認すると、月次コミットメントに加え、購入したFlex Slotsが表示されていることを確認できます。

「コミットメントの削除」タスク
コミットメントの削除は以下のスクリプト bigquery_flex_slots_remove_commitment.sh で行います。なお、削除対象のコミットメントIDを指定する必要があります。そのため、Flex SlotsのコミットメントIDを取得し、そのIDを利用して対象のコミットメントを削除します。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
capacity_commitment_id=$(bq ls --capacity_commitment --location US --format prettyjson --project_id=${admin_project_id} | jq 'map(select(.["plan"] | startswith("FLEX"))) | .[] | .name | split("/") | .[5]'| sed 's/"//g')
bq rm --project_id=${admin_project_id} --location=US --capacity_commitment ${admin_project_id}:US.${capacity_commitment_id}
「予約」タスク
予約は以下のスクリプト bigquery_flex_slots_reservation.sh で行います。予約により、プロジェクトに対し割り当てるスロットを確保します。ここでは、月次コミットメント2000とFlex Slots 7000、合計9000スロットを予約します。
admin_project_id=$ADMIN_PROJECT_ID
reservation=$1
assignment_project_slot=$2
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq update --project_id=${admin_project_id} --location=US --slots=${assignment_project_slot} --reservation ${reservation}
そして、予約に成功すると以下のようなログが出力されます。
name slotCapacity ignoreIdleSlots creationTime updateTime
------------------------------ -------------- ----------------- ----------------------------- -----------------------------
admin-gcp-project:US.batch 9000 False 2020-06-01T01:48:43.480961Z 2021-07-06T01:06:55.357921Z
また、GCPコンソールの予約を確認すると2000スロットから9000スロットに更新されていることも確認できます。

運用におけるFlex Slotsの注意点とワークフロー設計
上記の運用を実際に行ってみると、Flex Slotsを購入できないことが1〜2か月に1度程度発生します。スロットが購入できない場合、そのままでは月次コミットメントで購入した2000スロットを用いてバッチ処理の集計をすることになります。
本来9000スロットを必要とするバッチ処理の集計を2000スロットで実施することになり、完了していなければいけない想定の時間までに集計を終えることができません。そのため、Flex Slotsを購入できなかった場合には、割り当てを削除し、定額料金モデルからオンデマンド料金モデルに切り替える必要があります。
それらを考慮し、以下のワークフロー設計で運用をしています。
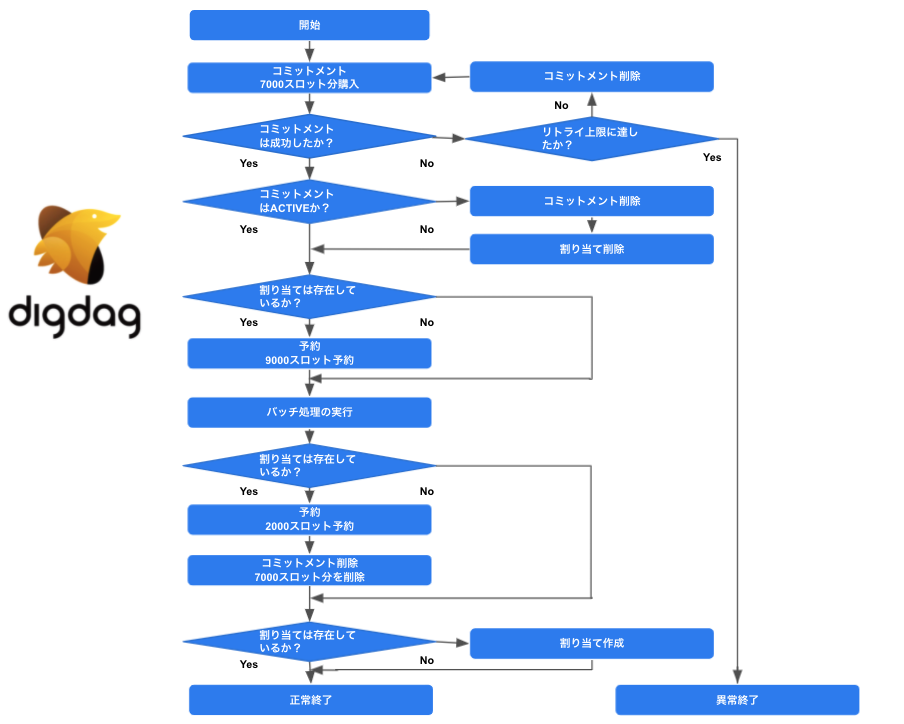
運用上の注意点2選
前述のフロー設計で運用していく場合にも注意点が存在するので、2つ紹介します。どちらもFlex Slotsが購入できない場合に必要となる対応です。
コミットメント購入時は冪等にする
コミットメント購入時には冪等性を意識する必要があります。
実際に次のようなエラーで購入できない場合があります。
BigQuery error in mk operation: Failed to create capacity commitment in '': The
service is currently unavailable.
このエラーの場合、リトライすることで購入できます。リトライによりFlex Slotsを2回購入してしまうと費用がその分加算されてしまうので、以下のスクリプト例のように、既に購入したコミットメントを削除して冪等性を意識した処理にします。なお、PENDING状態でもしばらくするとACTIVE状態になるため、スロット分の費用が発生します。
slots=$1
bash tasks/bigquery_flex_slots_remove_commitment_wrapper.sh
bash tasks/bigquery_flex_slots_purchase_commitment.sh $slots
オンデマンド料金モデルに自動で切り替える
Flex Slotsで購入したコミットメントの状態がPENDING状態の場合、次の購入が長時間できない状態になることが多いです。Exponential Backoffでリトライしても購入できません。そのため、後続処理が遅延しないように定額料金モデルからオンデマンド料金モデルへ切り替える必要があります。公式ドキュメントでもそのような対応を勧めています。
発生頻度や遅延の影響を考慮すると、自動切り替えが可能なワークフロー設計にする必要があります。それには、割り当てを削除することで切り替え可能な設計にできます。月次コミットメントは削除できませんが、PENDING状態のFlex Slotsは削除できるので、割り当てと一緒に削除します。なお、PENDING状態の場合には費用は請求されませんが、ACTIVE状態になると請求されてしまいます。
Slots are subject to available capacity. When you purchase slots and BigQuery allocates them, then the Status column shows a check mark. If BigQuery can't allocate the requested slots immediately, then the Status column remains pending. You might have to wait several hours for the slots to become available. If you need access to slots sooner, try the following:
If a slot commitment fails or takes a long time to complete, consider using on-demand pricing temporarily. With this solution, you might need to run critical queries on a different project that's not assigned to any reservations, or you might need to remove the project assignment altogether.
引用:Working with Reservations | BigQuery | Google Cloud
ワークフロー
運用上の注意点で述べたように、Flex Slotsを購入できなかった場合には、オンデマンド料金モデルに切り替える必要があります。冒頭で紹介したワークフローと違い、各タスクで冪等性を考慮したり、コミットメントの状態を確認し、オンデマンド料金モデルに切り替えられるよう設計し直しています。実行してるタスクはラッパータスクとして後ほどご紹介します。

+bigquery_flex_slots_up:
+bigquery_flex_slots_commitment:
_retry:
limit: 5
interval: 10
interval_type: exponential
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_purchase_commitment_wrapper.sh 7000
+bigquery_flex_slots_verify_for_ondemand_planning:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_verify_for_ondemand_planning.sh
+bigquery_flex_slots_reservation:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_reservation.sh batch 9000
これにより、オンデマンド料金モデルへ切り替えた場合、割り当ては削除されるようになります。バッチ処理完了後に割り当ての有無を確認し、割り当てがなければ割り当てを作る点が、前述のタスクとの違いです。

+bigquery_flex_slots_down:
+bigquery_flex_slots_reservation:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_reservation.sh batch 2000
+bigquery_flex_slots_removement:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_remove_commitment_wrapper.sh
+bigquery_flex_slots_reserve_assignment:
_retry: 3
_env:
GCP_CREDENTIAL: ${secret:gcp.credential}
_export:
docker:
image: ${docker_cloudsdk.image}
pull_always: ${docker_cloudsdk.pull_always}
sh>: tasks/bigquery_flex_slots_reserve_assignment_wrapper.sh
ラッパータスク
次に、ワークフローから実行しているタスクを紹介します。冪等性やエラーのハンドリングをする必要があるため、ラッパータスクを用意しています。なお、ラッパータスクから呼び出しているタスクは後述します。
コミットメント
最初に、コミットメントのラッパータスクをご紹介します。
コミットメントの購入
コミットメントの購入時に、以下のエラーが出力される場合もあります。このエラーがでた場合、購入したコミットメントはPENDING状態になります。
BigQuery error in mk operation: Failed to create capacity commitment in '': The
service is currently unavailable.
PENDING状態になった場合、しばらくするとACTIVEになり請求対象となります。そのため、リトライの際は対象のコミットメントを削除してから再購入しています。
Flex Slotsを運用してみたところ、Flex Slotsでコミットメントを購入できないケースが2パターン見つかりました。
1つ目は、コミットメント購入時に上記のエラーが出力されて購入できない場合です。この場合は、Exponential Backoffなどでリトライすることで購入できます。
2つ目は、コミットメント購入時にエラーは出力されないものの、購入したコミットメントの状態がPENDINGになる場合です。
コミットメントの購入に失敗することは、前述の通り1〜2か月に1度程度発生し、ほとんどが上記の2つ目のパターンです。2つ目の場合、Exponential Backoffなどでリトライしても購入できないため、即時オンデマンド料金モデルへ切り替える必要があります。

上記の内容を、以下のスクリプト bigquery_flex_slots_purchase_commitment_wrapper.sh で行います。
slots=$1
bash tasks/bigquery_flex_slots_remove_commitment_wrapper.sh
bash tasks/bigquery_flex_slots_purchase_commitment.sh $slots
コミットメントの削除
コミットメントを削除するタスクです。まず、オンデマンド料金モデルへの切り替えを考慮し、割り当ての有無を確認します。その後、割り当ての確認ができたらFlex SlotsのコミットメントIDを取得して、対象のコミットメントIDを削除しています。

上記の内容を、以下のスクリプト bigquery_flex_slots_remove_commitment_wrapper.sh で行います。
assignment=$(bash tasks/bigquery_flex_slots_assignment_status.sh)
if [ -n "$assignment" ]; then
capacity_commitment_id=$(bash tasks/bigquery_flex_slots_fetch_commitment.sh)
if [ -n "$capacity_commitment_id" ]; then
bash tasks/bigquery_flex_slots_remove_commitment.sh $capacity_commitment_id
fi
fi
なお、コミットメントを削除する際に、以下のエラーが出力される場合もあります。一見、コミットメントの削除に失敗していそうですが、実際には削除できています。そのため、リトライした際に削除済みであるか、コミットメントの有無を確認しています。
BigQuery error in rm operation: Failed to delete capacity commitment 'admin-gcp-project:US.11812766842974244240': The service is currently unavailable.
予約
次に予約のタスクをご紹介します。
予約の作成
このタスクではFlex Slotsで購入した7000スロットと月次コミットメントを合わせた、合計9000スロットをデータ基盤用のプロジェクトへ割り当てるために利用しています。

上記の内容を、以下のスクリプト bigquery_flex_slots_reservation.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
reservation=$1
assignment_project_slot=$2
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
assignment=$(bash tasks/bigquery_flex_slots_assignment_status.sh)
if [ -n "$assignment" ]; then
bq update --project_id=${admin_project_id} --location=US --slots=${assignment_project_slot} --reservation ${reservation}
fi
割り当て
定額料金モデルからオンデマンド料金モデルに切り替えるには、作成した割り当てを削除する必要があります。割り当てがあるか確認し、もしなければ割り当てを作ります。
割り当ての作成
このタスクはワークフローでオンデマンド料金モデルに切り替えたのち、バッチ集計完了後に実行しています。割り当てがない場合は割り当てを作ります。

上記の内容を、以下のスクリプト bigquery_flex_slots_reserve_assignment_wrapper.sh で行います。
assignment=$(bash tasks/bigquery_flex_slots_assignment_status.sh)
if [ -z "$assignment" ]; then
bash tasks/bigquery_flex_slots_reserve_assignment.sh
bash tasks/bigquery_flex_slots_alert_notice.sh 2
fi
割り当ての削除
割り当てを削除するタスクです。具体的には、作成した割り当てを取得して削除します。これは、定額料金からオンデマンド料金モデルへ切り替えるために利用しています。

上記の内容を、以下のスクリプト bigquery_flex_slots_remove_assignment_wrapper.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
assignment=$(bash tasks/bigquery_flex_slots_fetch_assignment.sh)
bash tasks/bigquery_flex_slots_remove_assignment.sh $assignment
オンデマンド料金モデルへ切り替え
Flex Slotsで購入したコミットメントの状態を確認してPENDING状態だった場合、即時にオンデマンド料金モデルへ切り替えています。Flex SlotsはPENDING状態であれば請求されませんが、しばらくするとACTIVE状態になり、請求対象になります。そのため、購入したスロットをまず削除します。
その後、割り当てを削除し、定額料金モデルからオンデマンド料金モデルへ切り替えます。前述の通り、この場合はExponential Backoffなどでリトライしても購入できないため、即時オンデマンド料金モデルに切り替えています。しかし、オンデマンド料金モデルの場合、確実に遅延します。遅延の原因調査をやりやすくするために、料金モデルを切り替えた際には通知を飛ばしています。

上記の内容を、以下のスクリプト bigquery_flex_slots_verify_for_ondemand_planning.sh で行います。
flex_slots_status=$(bash tasks/bigquery_flex_slots_fetch_commitment_status.sh)
if [ $flex_slots_status = "PENDING" ]; then
bash tasks/bigquery_flex_slots_remove_commitment_wrapper.sh
bash tasks/bigquery_flex_slots_remove_assignment_wrapper.sh
bash tasks/bigquery_flex_slots_alert_notice.sh 1
fi
その結果、購入したスロットを見るとPENDING状態であることが分かります。
Capacity commitment admin-gcp-project:US.
name slotCount plan renewalPlan state commitmentStartTime commitmentEndTime
-------------------------------------------- ----------- ------ ------------- --------- --------------------- -------------------
admin-gcp-project:US.9638566938320457134 7000 FLEX PENDING
タスク
次にラッパータスクから実行しているタスクを紹介します。
コミットメント
コミットメントの購入、削除、取得、状態確認をするスクリプトをご紹介します。
コミットメントの購入
まずはコミットメントを購入するスクリプトです。その際に、コミットメントでは購入したいスロット数を指定します。弊社では前述の通り7000スロット購入しています。
上記の内容を、以下のスクリプト bigquery_flex_slots_purchase_commitment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
slots=$1
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq mk --project_id=${admin_project_id} --location=US --capacity_commitment --plan=FLEX --slots=${slots}
コミットメントの削除
次に、コミットメントを削除するスクリプトです。購入したコミットメントは削除しないかぎり請求されるため、バッチ処理が終わったら、購入したコミットメントを即時削除する必要があります。
上記の内容を、以下のスクリプト bigquery_flex_slots_remove_commitment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
capacity_commitment_id=$1
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq rm --project_id=${admin_project_id} --location=US --capacity_commitment ${admin_project_id}:US.${capacity_commitment_id}
コミットメントの取得
コミットメントを取得するスクリプトです。コミットメントを削除する際にはコミットメントIDを取得する必要があるため、その用途で利用するものです。
上記の内容を、以下のスクリプト bigquery_flex_slots_fetch_commitment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq ls --capacity_commitment --location US --format prettyjson --project_id=${admin_project_id} | jq 'map(select(.["plan"] | startswith("FLEX"))) | .[] | .name | split("/") | .[5]'| sed 's/"//g'
コミットメントの状態取得
コミットメントの状態を確認するスクリプトです。PENDING状態の場合に、コミットメントと割り当てを削除し、定額料金モデルからオンデマンド料金モデルへ切り替えるために利用します。
上記の内容を、以下のスクリプト bigquery_flex_slots_fetch_commitment_status.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq ls --capacity_commitment --location US --format prettyjson --project_id=${admin_project_id} | jq 'map(select(.["plan"] | startswith("FLEX"))) | .[] | .state | split("/") | .[0]'| sed 's/"//g'
予約
次に予約を作成するスクリプトをご紹介します。
予約の作成
予約を作成するスクリプトです。Flex Slotsで購入した7000スロットと月次コミットメントを合わせた、合計9000スロットをデータ基盤用のプロジェクトへ割り当てるために利用しています。
上記の内容を、以下のスクリプト bigquery_flex_slots_reservation.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
reservation=$1
assignment_project_slot=$2
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
assignment=$(bash tasks/bigquery_flex_slots_assignment_status.sh)
if [ -n "$assignment" ]; then
bq update --project_id=${admin_project_id} --location=US --slots=${assignment_project_slot} --reservation ${reservation}
fi
割り当て
次に割り当ての作成、削除、取得、作成有無を確認するスクリプトをご紹介します。
割り当ての作成
割り当てを作成するスクリプトです。割り当てを作成することにより、BigQueryの料金モデルがオンデマンド料金モデルから定額料金モデルに切り替わります。
上記の内容を、以下のスクリプト bigquery_flex_slots_reserve_assignment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq mk --reservation_assignment --project_id=${admin_project_id} --assignee_id=assignee-gcp-project --location=US --assignee_type=PROJECT --job_type=QUERY --reservation_id=${admin_project_id}:US.batch
割り当ての削除
割り当てを削除するスクリプトです。割り当てを削除することにより、BigQueryの料金モデルが定額料金からオンデマンド料金モデルへ切り替わります。
上記の内容を、以下のスクリプト bigquery_flex_slots_remove_assignment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
assignment=$1
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq rm --project_id=${admin_project_id} --location=US --reservation_assignment $assignment
割り当ての取得
割り当てたリソース名を取得するスクリプトです。オンデマンド料金モデルへ切り替える際に、リソース名を取得して削除するために利用しています。
上記の内容を、以下のスクリプト bigquery_flex_slots_fetch_assignment.sh で行います。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq ls --project_id=${admin_project_id} --location=US --reservation_assignment --format prettyjson | jq 'map(select(.["assignee"] | startswith("projects/assignee-gcp-project"))) | .[] | .name'| sed 's/projects//g' | sed 's/locations/:/g' | sed 's/reservations/./g' | sed 's/assignments/./g' | sed 's/\///g' | sed 's/"//g'
割り当ての有無を確認するために、以下のスクリプト bigquery_flex_slots_assignment_status.sh も利用しています。
admin_project_id=$ADMIN_PROJECT_ID
echo $GCP_CREDENTIAL > GCP_CREDENTIAL.json
gcloud auth activate-service-account --key-file=GCP_CREDENTIAL.json
export BIGQUERYRC=/root/.bigqueryrc
bq ls --project_id=${admin_project_id} --location=US --reservation_assignment | sed 's/No reservation assignments found.//g'
Flex Slotsの導入効果
本章では、Flex Slotsの導入効果をご紹介します。
パフォーマンス面の効果
Flex Slots導入により、2〜6時間ほどのパフォーマンス改善が実現されました。スロットを購入できた場合、1.5時間前後でバッチ処理は完了します。スロットを購入できなかった場合は、即時オンデマンド料金モデルへ切り替えています。オンデマンド料金モデルだと、改善された分のパフォーマンスが得られないため、スロットを購入できた場合と比べ2〜6時間ほど遅延します。
コスト面の効果
現時点で毎月数十万円ほどのコストメリットを得られています。
オンデマンド料金モデルでは1TBあたり日本円にして500円ほどで、毎月1TBまでは無料で利用できます。なお、クエリで処理しているバイト数はBigQueryのInformation Schemaより確認できます。
SELECT
SUM(total_bytes_processed) /(1024 * 1024 * 1024 * 1024) AS total_terabyte_processed
FROM
`assignee-gcp-project`.`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN '2021-06-01 00:00:00.000 UTC'
AND '2021-06-30 23:59:59.000 UTC'
cloud.google.com
Flex Slotsのメリット・デメリット
Flex Slotsを導入して実感したメリットとデメリットをご紹介します。
メリット
Flex Slotsを利用するメリットは以下の通りです。
パフォーマンスが改善される
Flex Slots導入により、オンデマンド料金モデルに比べて格段に集計時間が早くなりました。3〜6時間かかっていた集計が1.5時間程度で終わります。
BigQueryのオンデマンド料金モデルのままでパフォーマンス要件を満たせない場合、Flex Slotsを導入して得られるメリットは大きいでしょう。
コストを削減できる
Flex Slotsの導入効果で述べたように、弊社の利用状況だと月々数十万円ほどのコスト削減を実現できています。なお、既に述べたようにコストメリットはBigQueryの利用状況にも依存します。コストとパフォーマンスはトレードオフなので、Cloud MonitoringやInformation Schemaを使い、適切なスロット数を割り当てることでコスト削減が可能です。
デメリット
Flex Slotsを利用するデメリットは以下の通りです。どれもスロットを購入できないことに起因するものです。
リトライしても購入できない場合がある
Flex Slotsが購入できない場合、そのまま数時間にわたり購入できないことが多いです。月次コミットメントだと購入したスロット数以上のスロットは割り当てられないため、オンデマンド料金モデルに切り替えています。発生頻度は前述の通り1〜2か月に1度程度ですが、最長だと5日間連続で購入できないことも過去に発生しました。発生頻度が低いとは言えないため、手動ではなく自動で切り替わるようにしておかないと、運用負荷が大きくなります。
Slots are subject to available capacity. When you purchase slots and BigQuery allocates them, then the Status column shows a check mark. If BigQuery can't allocate the requested slots immediately, then the Status column remains pending. You might have to wait several hours for the slots to become available. If you need access to slots sooner, try the following:
引用:Working with Reservations | BigQuery | Google Cloud
オンデマンド料金モデル切り替えに伴いコストが発生する
定額料金モデルからオンデマンド料金モデルへ切り替える場合、割り当てとFlex Slotsで購入したコミットメントを削除します。
しかし、Flex Slotsのコミットメントは削除できますが、月次コミットメントは購入から30日間は削除できません。そのため、切り替えに伴ってオンデマンド料金に加え、月次コミットメント分の費用が余分に発生します。
ワークフローが煩雑化する
Flex Slotsが購入できない場合を考慮したワークフロー設計にする必要があるため、それに伴ってコードも煩雑化します。サポート状況などの確認が必要ですが、必要に応じてOSSにPull Requestを投げつつ、Pythonのクライアントライブラリに置き換えたいと考えています。
googleapis.dev
今後の活用
現在は、社内でもデータ基盤用のプロジェクトのみ、定額料金で運用しています。今後は全社展開を行い、コスト・パフォーマンス改善を全社規模で行いたいと考えています。
社内では、機械学習の活用に伴いBigQueryの利活用が進んでおり、推論のバッチやBigQuery MLなど、Flex Slotsを使ってパフォーマンス面で解決できる部分は多く存在しています。さらに、検索系の案件など、全社のBigQuery費用の上位に該当するプロジェクトもあります。これらのプロジェクトでコスト、パフォーマンスの両面で最適化を行えば、その効果は大きなものになるでしょう。
また、現時点ではBigQueryのジョブユーザ管理ができていません。BigQueryはストレージとコンピューティングリソースが分離されており、IAMもBigQuery閲覧権限とBigQueryジョブユーザと別れています。クエリ実行に伴う請求はこのBigQueryジョブユーザ権限を付与したプロジェクトに対して行われます。下図の場合、プロジェクトBでジョブユーザを管理し、プロジェクトAのテーブルやビューを参照できます。

引用:BigQuery for data warehouse practitioners | Cloud Architecture Center
しかし、現時点では社内でジョブユーザの管理をうまくできていないため、重複管理やオンデマンド料金モデルのプロジェクトに対しても付与されています。ユーザに紐付くアドホックなクエリなど、定額料金モデルを適用したプロジェクトで管理できるとBigQueryのコストを下げることができるので、この点は今後の課題としています。
おわりに
Flex Slotsを導入することで、BigQueryのコストやパフォーマンスの改善が可能であること、その運用上の注意点をご紹介しました。Flex Slotsの購入に失敗することを考慮したワークフロー設計が必要になるなどの煩雑さはありますが、欠点を大きく上回る利点があります。今後もFlex Slotsを積極的に使っていく予定です。
データの利活用を促進する際に、本記事が同じような課題を抱えている方の参考にれば幸いです。
私たちのチームの業務内容は、以下の記事で紹介しているのでご覧ください。今回紹介した内容以外にも、ログ収集基盤の開発など、データ基盤に関する業務全般を行っています。
https://it-career.blm.co.jp/interviews/zozotechnologies-it-taniguchi-interviewit-career.blm.co.jp
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
https://tech.zozo.com/recruit/tech.zozo.com


























































