



こんにちは。ZOZOテクノロジーズZOZOTOWN部 検索チーム 兼 ECプラットフォーム部 検索基盤チームの有村です。
ZOZOTOWNでは、以前からキーワード検索時にはRDBと併用してElasticsearchを使用していました。本記事ではこれまでRDBで行っていたIDによる索引検索も含め、すべての検索をElasticsearchへ置き換えた事例と、その際に行った設定内容の一部をご紹介します。
背景
弊社CTOによるこちらの記事にもある通り、ZOZOTOWNでは現在マイクロサービス化を進めており検索システムについてもその対象となっています。検索の文脈では、全文検索/サジェスト/ロギング等関連する様々な課題への解決策として有効であるElasticsearchを採用しマイクロサービス化を進めています。
また、もう1つの背景として検索のパーソナライズ化があります。これまでZOZOTOWNでは表示順として「人気順」という多方面から集計されたデータを基に算出されたスコアを使用していましたが、このスコアは商品に紐づくため全ユーザに対して一律な結果を返していました。一方でファッションは年代・性別だけでなく個人の趣味・時代によって大きく好みが異なる分野であり、個人にパーソナライズされた検索が必須となることは明らかでした。そこでRDBからElasticsearchのような検索に特化したシステムへ置き換えることによって検索のパーソナライズ化を実現することとしました。
先述した通りZOZOTOWNではElasticsearchをキーワード検索時の検索エンジンとしてRDBと併用していたため、Elasticsearchにデータを連携するシステムは存在していました。しかしRDBとの併用を廃止し、完全にElasticsearchのみで検索を行うにあたり既存のシステムでは以下のような難しい部分がありました。そこで今回インデキシングに特化した新規システムを構築しこれらの課題への対処を行うこととしました。
RDBからElasticsearchへ反映されるまでのリードタイム
既存のElasticsearchを用いた検索ではキーワードにマッチした商品IDのみを取得し、それをキーにRDBから最新の情報を引き当てていました。故に品切れや価格等のクリティカルな情報はRDB側で補完できたため、情報の更新は定期的なバッチで行っていました。一方でRDBの併用を廃止しElasticsearchのみでの検索を実現するにあたり、RDB内マスタテーブルの更新からElasticsearchへ変更を反映するまでのリードタイムに制約が設けられました。この制約を満たすためには既存のバッチの仕組み上対処が難しく、これに耐えうる新しい仕組みが必要でした。
多方面からのデータ登録
パーソナライズ化を進めていくにあたり、研究所の機械学習に基づくデータや分析チームのデータ分析に基づく商品特徴量など、データを追加する関係部署が複数考えられました。そのため任意の箇所から任意のデータを受け入れ、柔軟に検索可能になる状態を目指しました。今回構築した基盤はBigQueryをベースとしているため、データを抽出するクエリさえ用意できれば少ない手間でデータの反映が出来るような状態となっています。
システム概要
移行に際して新たに構築したシステムは以下のようなアーキテクチャです。
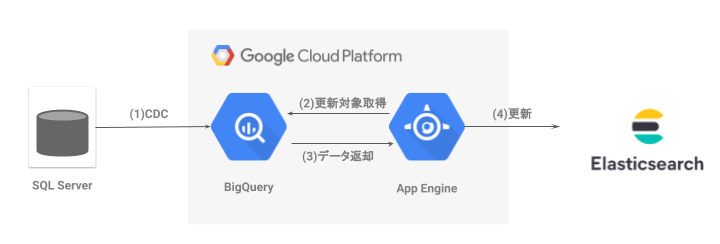
(1) CDCを取得
CDCとはChange Data Captureの略で、データベース内で行われた変更を追うことができる機能です。この機能はテーブル単位で設定可能で、レコードの追加・変更・削除やテーブルに対するカラム追加・削除の履歴が取得できます。
今回構築したシステムではこのCDCを以下の2つの用途で用いました。
- テーブルへの変更差分を蓄積することによって、レプリケーションが行えないテーブル間でもスナップショットと差分の組み合わせから最新のテーブルを再現する
- insert/delete/updateのうちどの操作が行われたのかを判断し、Elasticsearchに対する適切な更新オペレーションを行う
システム概要図のうち (1) の部分を更に詳細に示したのが以下の図になります。

SQL ServerからCDCを取得し、解読可能なメッセージの形への変換・配信するツールにはQlik Replicateを採用しました。
(2) 更新対象の取得、(3) データ返却
(1) で得られたCDCだけでは変更されたレコードの情報しかなく、用途にも書いた通り検索可能なデータにするためには別のテーブルと結合する必要があります。弊社では以前からDWHとしてBigQueryを使用しており、本システムに要求される大規模データを素早く処理するという要件に適していました。そのためBigQuery上でCDCを処理し、そこから得られた情報と、ある時点のスナップショットからなる元テーブルを結合し最新のテーブルを構築しています。
またBigQueryは構築されたテーブル同士の結合や配列への変換、データ整形も行っており、スケールしにくいバッチ側の負担を抑える役割も担っています。
(4) 更新
(2)、(3) の処理はストリームではなくバッチで行われており、データを取得した後はElasticsearchに対してリクエスト可能な形に変換し送信しています。このバッチはAppEngine上で動作しており、AppEngineではcron.yamlを用いて定期的に処理を実行する事が可能です。今回のシステムでは変更差分を定期的に確認・処理する目的で使用するほか、定期的に行うデータ更新バッチのトリガーとして使用しています。
以上のシステムを用いることで、商品がマスタテーブルに登録されてから、もしくは売り切れ等でステータスが変わった場合でも平常時約10分以下のリードタイムでユーザに情報を届けることが可能となりました。
Elasticsearch故の苦労/Elasticsearch故にできること
これまでRDBで補っていた部分をElasticsearchで全て完結しなくてはならなかったため、かなり苦戦した箇所もありました。またその逆で、RDBから解放されたことによって制約が外れ、自由にできることも増えました。今回はその中から特に印象的だった2つを紹介します。
JOINが難しい
ZOZOTOWNではファッションECならではの機能として、「サイズ感が分かりづらい」という課題に対して、mm単位で指定可能なこだわりサイズ検索を提供しています。

これまで、この機能はRDB内でサイズに関するサマリテーブルを作成しJOINして検索することで実現していました。この機能を実現するためにはこれまでと同様にサイズのテーブルをJOINするか1アイテムに対して複数サイズの情報を持たせ、それぞれの情報に対して絞り込めることが必須条件でした。しかし、Elasticsearchではインデックス間のJOINの機能がないため、必然的に後者での実装を行う事となりました。
データ型としてJoin datatypeといういかにもそれっぽいものが存在していますが、このデータ型には以下のような制約が存在しています。
- 同一shard上にparent/child documentが存在しなければいけない
- child documentがparent documentのIDを把握しなくてはいけない
そこで、Join datatypeの代わりとしてNested datatypeを用いることにし、1ドキュメント内にJOIN対象のデータを子要素として合わせて持たせることにしました。Nested datatypeではnested queryを用いることでそれぞれの子要素に対する検索をかけることができるため、SQLでいうJOINの動作が再現できます。
例 : 身長・体重を過去の履歴含めて検索する
/* Mapping Definition */
PUT /health_index
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"data": {
"type": "nested",
"properties": {
"weight": {
"type": "float"
},
"height": {
"type": "float"
},
"created_at": {
"type": "date"
}
}
}
}
}
}
/* Create Data */
POST /health_index/_doc/
{
"id": 1,
"name": "Mike",
"data": [
{
"weight": 50,
"height": 160,
"created_at": "2020-01-01"
},
{
"weight": 55,
"height": 160,
"created_at": "2020-02-01"
}
]
}
POST /health_index/_doc/
{
"id": 2,
"name": "John",
"data": [
{
"weight": 53,
"height": 162,
"created_at": "2020-01-01"
},
{
"weight": 55,
"height": 165,
"created_at": "2020-02-01"
}
]
}
/* Search for matching document */
GET /health_index/_search
{
"query": {
"nested": {
"path": "data",
"query": {
"bool": {
"filter": [
{
"range": {
"data.weight": {
"gte": 50.0,
"lte": 52.0
}
}
},
{
"range": {
"data.height": {
"gte": 160
}
}
}
]
}
}
}
},
"_source": "name"
}
これらは以下のテーブル、SQLと同じような意味合いになります。
User
| userId | name |
|---|---|
| 1 | Mike |
| 2 | John |
HealthData
| dataId | userId | weight | height | created_at |
|---|---|---|---|---|
| 1 | 1 | 50 | 160 | 2020-01-01 |
| 2 | 2 | 53 | 162 | 2020-01-01 |
| 3 | 1 | 55 | 160 | 2020-02-02 |
| 4 | 2 | 55 | 165 | 2020-02-02 |
SELECT name FROM User INNER JOIN HealthData ON User.usedId = HealthData.userId WHERE HealthData.weight BETWEEN 50 AND 52 AND HealthData.height >= 160 GROUP BY name
このように、JOINが必要となるデータに関してはあらかじめ1つのdocument内に併せ持つことによって、シャードの考慮等必要なくデータの再現が可能となりました。一方デメリットとして、Nested datatypeを使用した場合、親要素 + 子の要素分のドキュメントが生成されます。これによってKibana上のMonitoring > Indicesから見た際のDocument Countとインデックスに対して/_countで問い合わせた際の件数とで差異が生じます。
www.elastic.co
定義の追加なくA/Bテストが可能に
RDBのみで検索を運用していた際のA/Bテストでは、事前にパターン分のカラム・データをテーブルに追加する作業が発生していました。
対してElasticsearchではRDBと異なり、明示的に定義されていないフィールドも受け入れ可能にするDynamic Mappingがデフォルトで有効化されています。更にこの設定はフィールドのトップレベルだけの設定だけでなく、子要素にも指定可能となっています。そのため、トップレベルではインデックスの構造を保護するためにDynamic Mappingをstrictに、A/Bテスト用の自由フィールドだけ子要素をdynamicにといった構造にすることも可能です。
/* テンプレート登録 */
PUT /_template/ab_index
{
"index_patterns": [
"ab_index_*"
],
"mappings": {
"properties": {
"ab_params": {
"dynamic": true,
"properties": {}
}
},
"dynamic_templates": [
{
"ab_params": {
"path_match": "ab_params.*",
"mapping": {
"type": "float"
}
}
}
],
"dynamic": "strict"
}
}
/* 許可されていないドキュメント */
POST /ab_index_1/_doc
{
"param1": 0.00
}
=>
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [param1] within [_doc] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [param1] within [_doc] is not allowed"
},
"status": 400
}
/* 許可されているドキュメント */
POST /ab_index_1/_doc
{
"ab_params.param1": 0.00
}
=>
{
"_index" : "ab_index_1",
"_type" : "_doc",
"_id" : "8t2RSnIBqlQNXy6Wvovk",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
/* 検索 */
GET /ab_index_1/_search?filter_path=hits.hits._source
{
"query": {
"range": {
"ab_params.param1": {
"lte": 2.0
}
}
}
}
=>
{
"hits" : {
"hits" : [
{
"_source" : {
"ab_params.param1" : 0.0
}
}
]
}
}
この設定によってデータの構造が正常であることを担保しつつ、1インデックスで必要に応じてA/Bテスト用のパラメータが追加・検索可能な状態になりました。また、背景の箇所に書いた他部署による任意のデータを受け入れ可能な状態もこれによって実現されています。実際に現在ZOZOTOWNの検索の一部でこの機能が使われており、データ分析を行うような専門のチームによって作成されたスコアを用いた評価が行われています。
まとめ
本記事では、ZOZOTOWNすべての検索をElasticsearch移行した事例と、その最中に行った印象的な設定について紹介しました。新規の検索基盤に移り変わったばかりですが、様々なA/Bテスト案や改善案が立ち上がっており移行の恩恵を早々と受けています。
最後に、ZOZOテクノロジーズでは検索をさらに改善する検索エンジニアを募集しています。ご興味のある方は、以下のリンクからぜひご応募ください!