



こんにちは、アーキテクト部の廣瀬です。
弊社ではサービスの一部にSQL Serverを使用しています。以前の記事でSQL Serverのスナップショット分離レベルを導入した事例を紹介しました。
この段階で、スナップショット分離レベルの導入によってデータ基盤連携の課題は解決できていました。しかし、今度はスナップショット分離レベル特有の問題が発生しました。本記事では、そこで発生した問題と、どのように調査・対応していったのかを紹介します。
発生した問題
あるDBに対する全クエリの内、一部のクエリでタイムアウト多発が約20分間ほど継続した後、自然解消しました。スナップショット分離レベルの導入から約2週間経過していたため、最初は障害との関連性は低いと考えていました。
しかし、今まで経験したことがない種類のエラーだったので、スナップショット分離レベルを導入したことに留意しつつ、調査を進めていくことにしました。なお、調査は以前紹介した障害調査フローに従って実施したので、併せてご覧ください。
調査の流れ
パフォーマンスモニタの主要メトリクス
最初に、パフォーマンスモニタの主要なメトリクスを確認していきました。特に着目したメトリックを紹介します。
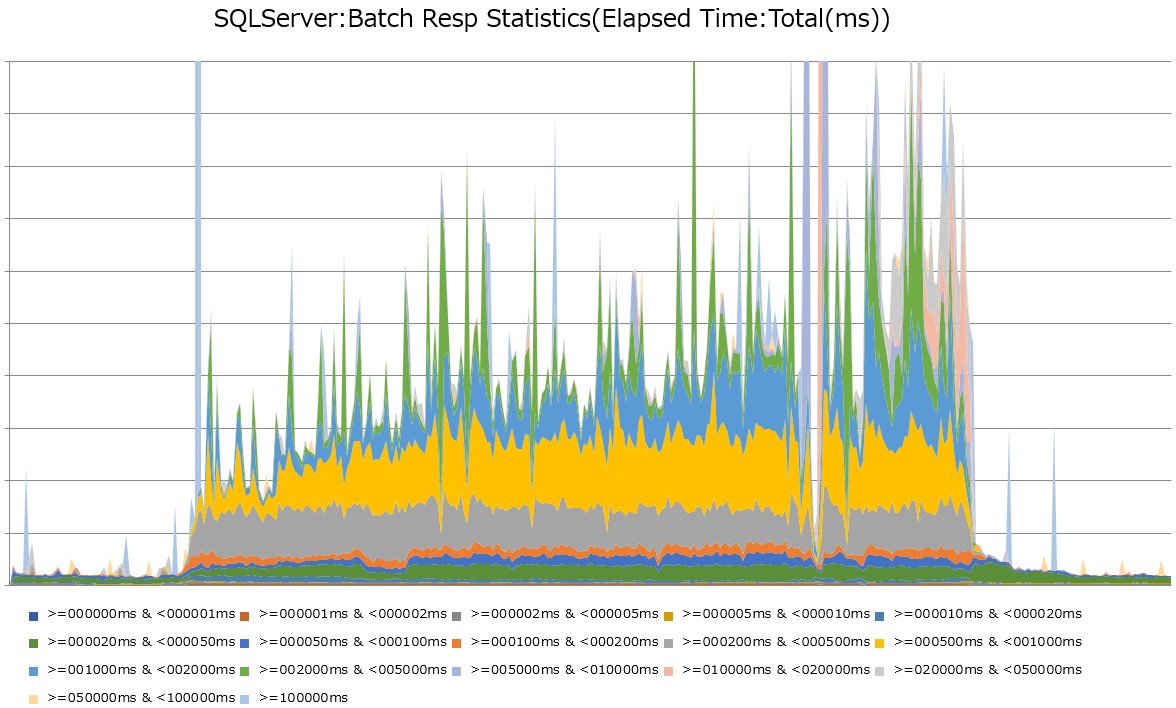
上図、Batch Resp StatisticsのElapsed Time:Total(ms)では、例えば「応答時間が0ミリ秒以上1ミリ秒未満の全クエリの実行時間を足し合わせると5秒になる」といったことが分かります。各値を積み上げた面グラフにすることで、クエリの総実行時間の推移を確認できますが、障害発生中は急激に増加しています。
次に、インスタンス全体のクエリパフォーマンスに影響があったかを確認するために、ワーカースレッド数の推移も確認しました。
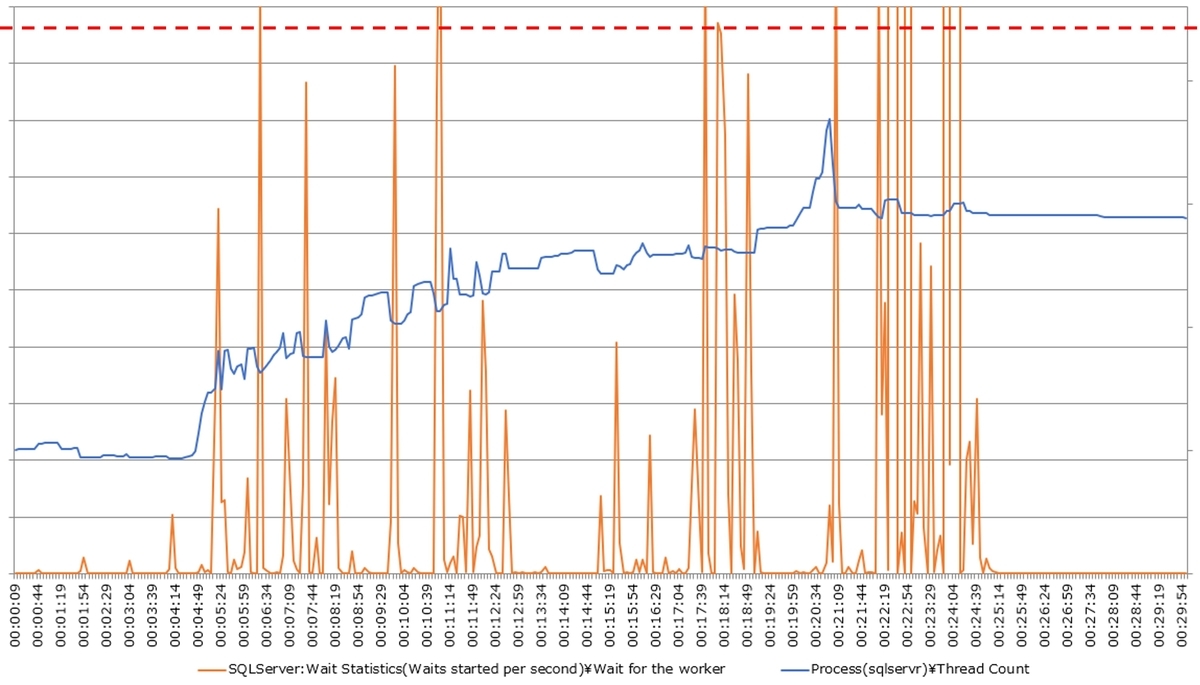
上図はワーカースレッド数のグラフであり、ワーカースレッド数が上昇し、ワーカースレッドの確保待ちは発生しているものの、上限(赤色の点線)には達していないことが分かります。従って、ワーカースレッド枯渇によりインスタンス全体が著しくスローダウンしているわけではありませんでした。
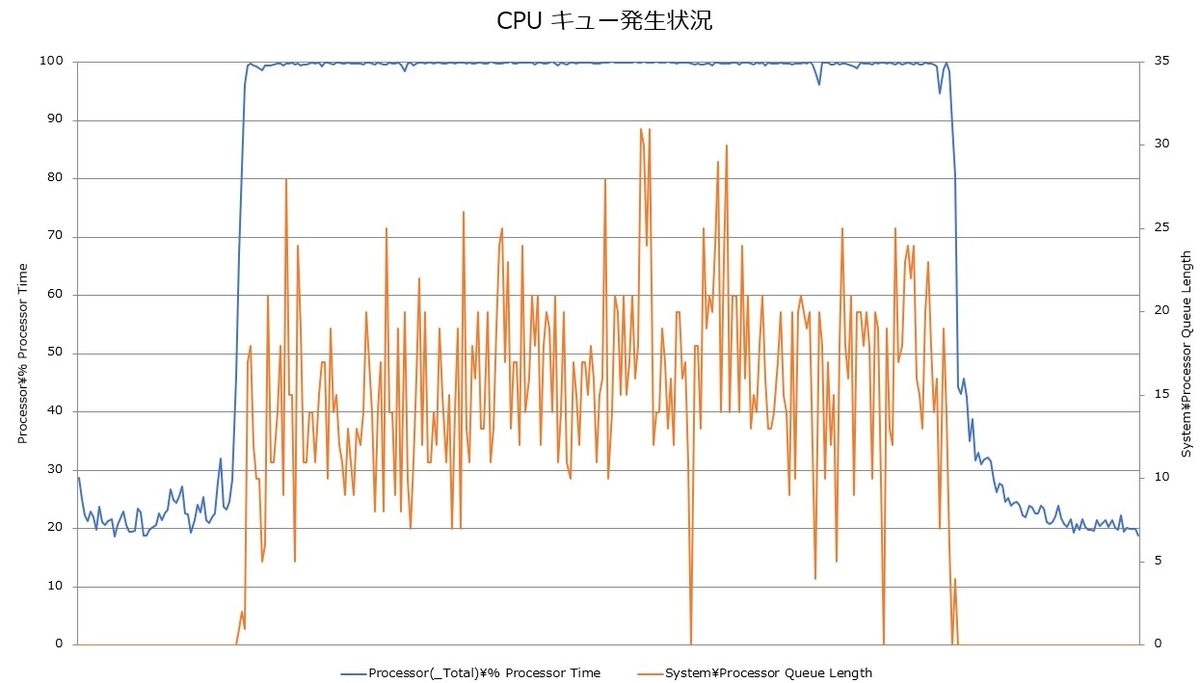
上図はCPU使用率のグラフです。障害発生中はCPU使用率が100%にほぼ張り付いている状況でした。また、CPUキューの発生も確認できました。
一部のクエリが突然タイムアウトしてCPU負荷が急激に上昇する場合、典型的な原因は「クエリプランの後退」です。「クエリプランの後退」とは、通常時は高速なプランが採用されているのに、リコンパイル時のパラメータ等が原因で低速なプランが生成されることを指します。
この事象はSQL Server 2017以降では「自動プラン選択修正」という機能を有効にしておくと自動復旧されます。しかし、問題が発生したDBは2016以前のバージョンだったため、代わりに自動リコンパイルによる簡易的な自動チューニング機能を実装していました。これは、「クエリプランの後退」が疑われる際に該当クエリを自動でリコンパイルするというものです。
リコンパイルが多発していたストアドプロシージャ
今回の障害発生時にリコンパイルのログが出ていないか確認しました。すると、障害発生と同タイミングでリコンパイルの発生が確認できました。
しかし、リコンパイルが走ってもクエリのスローダウンは解消されず、エラーが多発し続けていました。そして、リコンパイルされていたクエリは特定のストアドプロシージャだけでした。このストアドプロシージャがどのステートメントでスローダウンしているのかを収集しておいたログを使って調査すると、以下のことが分かりました。
- カーソルのオープン処理で非常に時間がかかっている
- 遅いステートメントの
last_wait_typeはSOS_SCHEDULER_YIELD
このカーソルは以下のようなシンプルなクエリで宣言されていました。
DECLARE my_cursor CURSOR FAST_FORWARD FOR SELECT col1 ,col2 ,col3 ,... ,colN FROM tableA JOIN tableB ON tableA.col1 = tableB.col2 JOIN tableC ON tableB.col2 = tableC.col3 ... JOIN tableN ON ... WHERE col4 = @col4 ORDER BY col5
何度もリコンパイルはされているので、非典型パラメータがコンパイル時に使用されたことで「クエリプランの後退」が発生したわけでは無いと判断しました。
他に考えられる原因として「統計情報が何度リコンパイルしてもスロークエリになってしまう状態であった」可能性を疑いました。そのため、関連テーブルの障害前後の統計情報の更新日時をログで確認しましたが、明確な関連性は見られませんでした。
実行プランはロギングの対象外にしているため後追いできませんが、タイムアウトしたクエリが通常時にどのようなプランで実行されているのかを確認しました。
その結果、1点気になる箇所がありました。基本的にはIndex Seekでデータを読み取り、Nested Loopsで結合するという操作を繰り返すだけでしたが、1か所だけIndex Scanになっていました。なお、Index Scanになっていたテーブルをここでは「テーブルA」とします。
テーブルAの調査
テーブルAを詳しく調査したところ、以下のような特殊なデータ更新が毎日1回行われていました。
- テーブルAと同じ構造のテーブルA'を全件DELETE
- テーブルA'に日次のデータをINSERT
- テーブルAとテーブルA'をリネームすることで入れ替え
障害発生中のテーブルAのインデックス容量の推移を確認してみたところ、不思議な事象が起きていました。
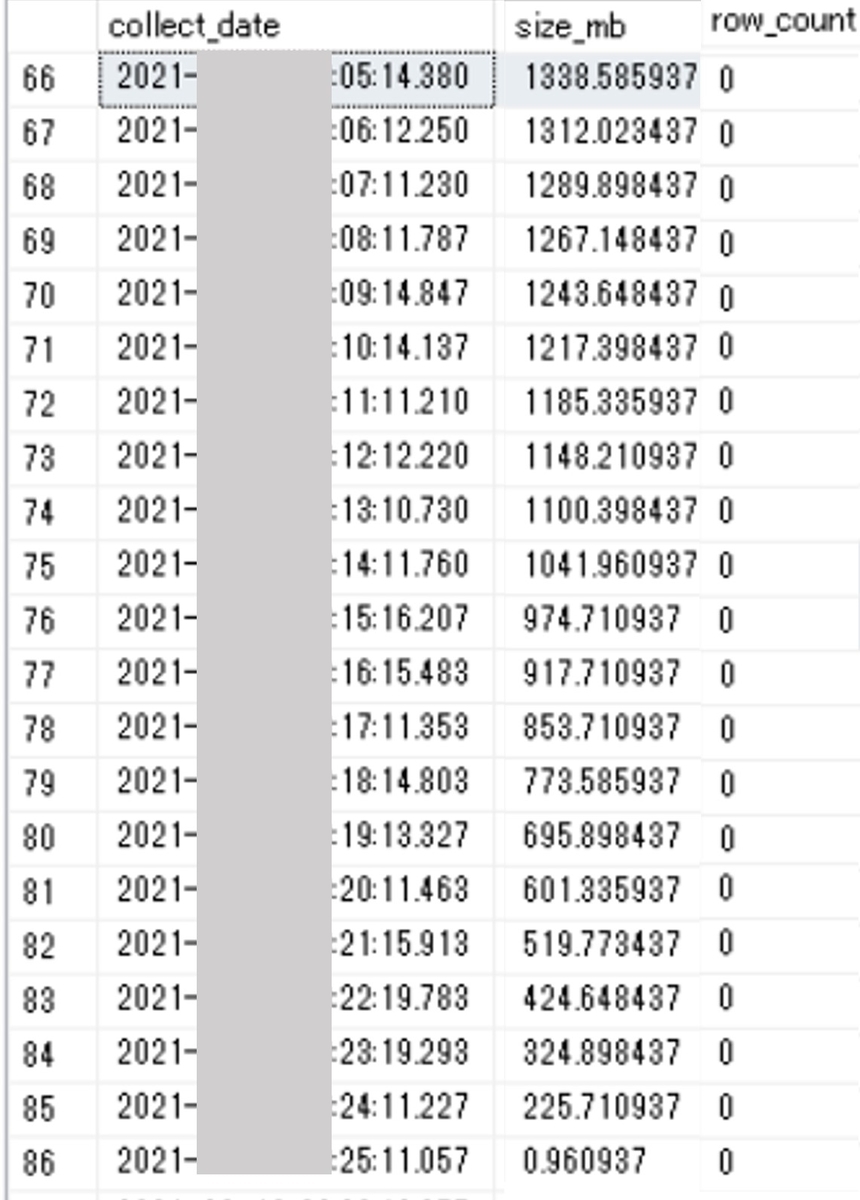
上図は、1分間ごとの容量推移です。1分ごとに少しずつ容量が少なくなっており、最終的に1.3GBから約1MBまでサイズが減少しています。
しかし、日次のデータ洗い替え処理は05分台には完了しておりこの日は0レコード(row_count=0)でした。レコード数が0なのに容量が1.3GBで、かつ徐々にサイズが減少していく不思議な事象です。理由は不明でしたが、障害発生時もテーブルAへのアクセスがIndex Scanなら最大約1.3GBのデータ読み取りが発生するため、スロークエリ化も納得がいきます。
Skipped Ghosted Records/sec
この事象を説明できるメトリクスが無いか再度パフォーマンスモニタのデータを調査したところ、「Skipped Ghosted Records/sec」というメトリックを見つけました。
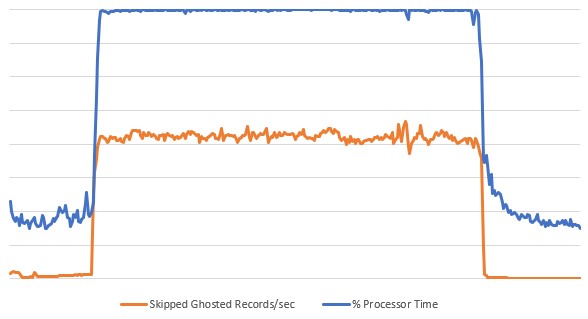
上図のように、障害発生中に顕著な上昇を示していたCPU負荷と同じタイミングで数値が上昇しています。
ドキュメントによると、「スキャン中にスキップされた1秒あたりの非実体レコードの数」という説明が書かれていました。そして、他のドキュメントには、ゴーストレコードは以下の内容で説明されていました。
インデックス ページのリーフ レベルから削除されたレコードは、物理的にはページから削除されません。代わりに、レコードに "削除対象" (つまり、ゴースト) としてマークされます。 つまり、行はページで保持されますが、行ヘッダーのビットが変更され、行が実際にはゴーストであることが示されます。 これは、削除操作中のパフォーマンスを最適化するためのものです。 ゴーストは行レベルのロックに必要ですが、古いバージョンの行を維持する必要があるスナップショットの分離にも必要です。
(引用:ゴースト クリーンアップ プロセスのガイド - SQL Server | Microsoft Docs)
テーブルAの日次データ入れ替え処理で、テーブルA'を全件DELETEします。このとき大量のゴーストレコードが発生しますが、クリーンアップタスクによるゴーストレコードの削除に何故か時間がかかっているようでした。そのため、Index Scan時のデータ読み取りサイズが非常に大きくなっています。
日次データの入れ替え処理は以前から運用していたので、DBに加えた他の変更が挙動の変化をもたらしたのではと考えました。そのため、直近で設定を追加したスナップショット分離レベル有効化の影響を疑い、さらに調査することにしました。
スナップショット分離レベルとゴーストレコードの関連性を明らかにする実験
スナップショット分離レベルを有効化した状態と無効化した状態とで、「Skipped Ghosted Records/sec」の発生状況を比較しました。
比較手順を順に説明します。手順はドキュメントの以下の記述を考慮して作成しています。
ゴーストは行レベルのロックに必要ですが、古いバージョンの行を維持する必要があるスナップショットの分離にも必要です。
(引用:ゴースト クリーンアップ プロセスのガイド - SQL Server | Microsoft Docs)
スナップショット分離レベルが有効な場合
1. スナップショット分離の有効化
ALTER DATABASE sample_db SET ALLOW_SNAPSHOT_ISOLATION ON
2. テストテーブルの作成とデータのINSERT
ランダムな整数値を100レコード分INSERTします。
DROP TABLE IF EXISTS sample_table CREATE TABLE sample_table (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 INT, c2 INT) GO INSERT INTO sample_table (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT)) GO 100
3. 別のテストテーブルの作成とデータのINSERT
トランザクションを開いたまま1件だけINSERTします。
CREATE TABLE sample_table_2 (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 INT, c2 INT) BEGIN TRAN INSERT INTO sample_table_2 (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT))
4. 別のクエリウィンドウで全レコードの50%をDELETE
DELETE FROM sample_table WHERE (pk%2) = 0
5. さらに別のクエリウィンドウで、以下のクエリ(フルスキャン)を連続実行
SELECT COUNT(*) FROM sample_table WITH(NOLOCK)
100件のデータをINSERTし、50件のデータをDELETEしたため、実行プラン中の読み取り行数は50行となります。ただし、実際には「Skipped Ghosted Records/sec」が発生するので、100行分のデータ読み取りが発生し、削除済みの50行がスキップされています。
6. 「Skipped Ghosted Records/sec」の変化を確認

上図のように、「Skipped Ghosted Records/sec」が発生し続けていることが確認できます。そして、手順 3. で開いたトランザクションをコミットすると、数秒後に「Skipped Ghosted Records/sec」の値が0になり、クリーンアップタスクによるゴーストレコードの削除を確認できます。
スナップショット分離レベルが無効な場合
1. スナップショット分離の無効化
ALTER DATABASE sample_db SET ALLOW_SNAPSHOT_ISOLATION OFF
手順 2. から 5. は「スナップショット分離レベルが有効な場合」の手順と同じクエリを実行します。
6. 「Skipped Ghosted Records/sec」の変化を確認
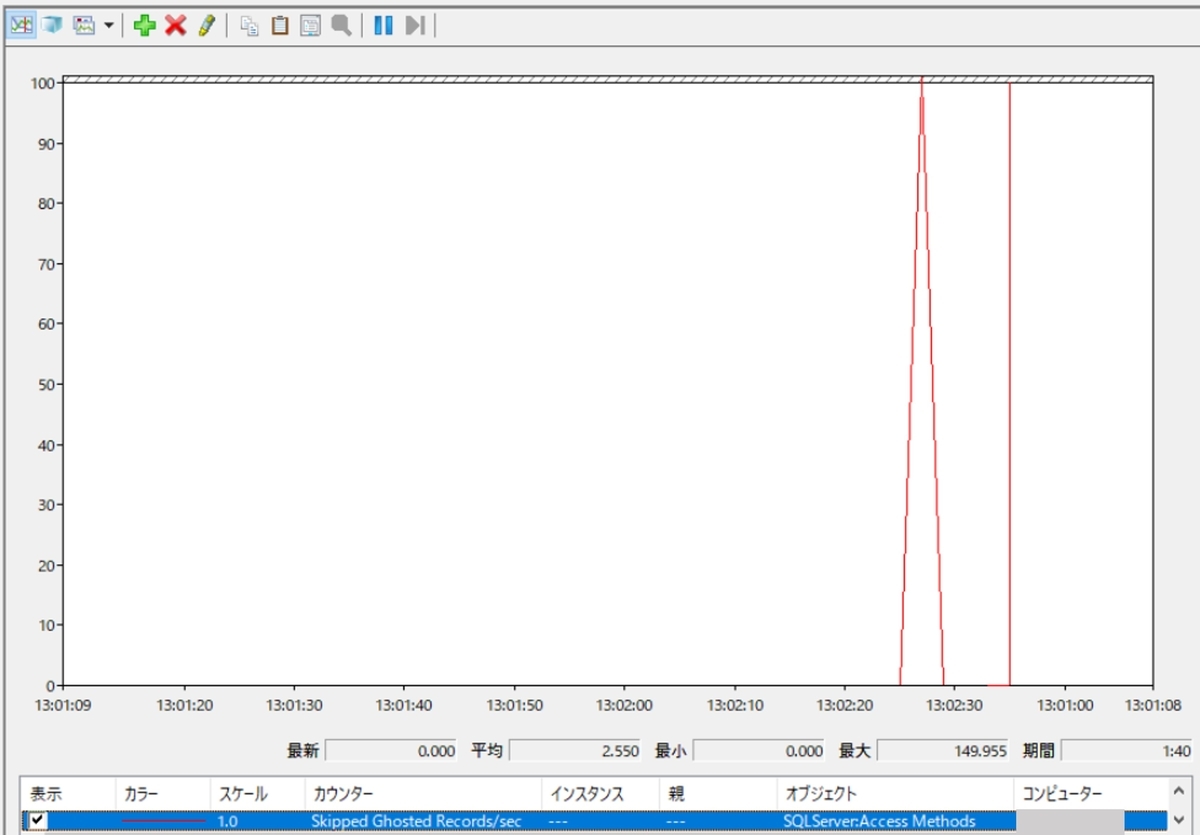
上図のように、「Skipped Ghosted Records/sec」の値が一瞬上昇しますが、すぐに元に戻ることが確認できます。つまり、クリーンアップタスクによってゴーストレコードが即座に削除されたということです。
両者の挙動の考察
スナップショット分離レベルを有効化すると、各レコードが必ずバージョン管理されるようになります。
この環境でゴーストレコードが削除されるための条件として、sample_tableへのDELETEが実行されたタイミングより前にOPENされたトランザクションがCOMMITされる必要があるようです。この条件は、トランザクション内でアクセスしているテーブルがsample_tableでなくても当てはまります。
スナップショット分離レベルでのSELECTでも同様の挙動になる
手順 3. を以下の2パターンに置き換えて実施しても、挙動が異なります。
ゴーストレコードがクリーンアップされるためには、DELETE処理よりも前に実行された「スナップショット分離レベルでのSELECTクエリ」も完了する必要があります。
--パターン1 SET NOCOUNT ON CREATE TABLE sample_table_2 (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 INT, c2 INT) GO INSERT INTO sample_table_2 (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT)) GO 100000 --長時間実行させるためのcross join SELECT COUNT_BIG(*) FROM sample_table_2 a CROSS JOIN sample_table_2 b CROSS JOIN sys.all_objects CROSS JOIN sys.all_columns
--パターン2 SET NOCOUNT ON CREATE TABLE sample_table_2 (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 int, c2 int) GO INSERT INTO sample_table_2 (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT)) GO 100000 --スナップショット分離レベルで実行 SET TRANSACTION ISOLATION LEVEL SNAPSHOT --長時間実行させるためのcross join SELECT COUNT_BIG(*) FROM sample_table_2 a CROSS JOIN sample_table_2 b CROSS JOIN sys.all_objects CROSS JOIN sys.all_columns
TRUNCATEだと再現しない
手順 3. を以下の2パターンに置き換えると、挙動の差異は生まれなくなりました。どちらも「Skipped Ghosted Records/sec」が発生しません。
--パターン1 SET NOCOUNT ON CREATE TABLE sample_table_2 (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 INT, c2 INT) GO INSERT INTO sample_table_2 (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT)) GO 100000 TRUNCATE TABLE sample_table_2
--パターン2 SET NOCOUNT ON CREATE TABLE sample_table_2 (pk INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, c1 INT, c2 INT) GO INSERT INTO sample_table_2 (c1, c2) VALUES (CAST(RAND() * 100 AS INT),CAST(RAND() * 100 AS INT)) GO 100000 --スナップショット分離レベルで実行 SET TRANSACTION ISOLATION LEVEL SNAPSHOT TRUNCATE TABLE sample_table_2
調査結果のまとめ
前述の調査結果をまとめると、障害の原因は以下のように推測できます。
- テーブルAの日次データの入れ替え処理で、テーブルA'が全件DELETEされる
- テーブルA'のDELETEより前に実行されていた更新処理またはスナップショット分離レベルでのSELECTによってゴーストレコードが削除されにくい状況になる
- テーブルA'をリネームしたテーブルAは、統計情報としては0レコードなのでIndex Scanするプランになるが、フルスキャンの際に「Skipped Ghosted Records/sec」が多発する
- データ読み取り量が多いため、普段より低速となりタイムアウト多発に繋がった
そのため、以下の3つを満たす環境では注意が必要です。
- 様々なトランザクションが同時に実行されており、タイミングもバラバラである
- スナップショット分離レベルが有効になっている
- 大量のレコードを全件DELETEする処理がある
対応策の実施
実験結果から、テーブルAの日次データの入れ替え処理におけるテーブルA'の全件DELETE処理をTRUNCATEに変更しました。この変更により同様の障害が発生することは無くなりました。
まとめ
本記事では、スナップショット分離レベルを有効にした環境で発生した障害と、その原因調査から対応策の実施までの流れを紹介しました。同様の事象で困っている方の参考になれば幸いです。
最後に
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!