



ZOZO研究所の森下(@IshyMore)です。本記事では、数式とソースコードを含む教材を用いてテレワーク環境下で輪講を実施した際に、スムーズに輪講を進められるよう工夫した点について紹介します。
目次
輪講の目的
ZOZO研究所では日々の研究開発の傍ら、論文の輪読会、興味・関心事を紹介する勉強会、研究者を招待しての講演会など行っています。輪講も開催しており、メンバー同士で互いに議論しながら教材を読むことで、基礎知識の定着を図っていました。
ところが、昨今の新型コロナウィルスの感染拡大に伴い弊社では在宅勤務が中心になりました。それまで開催していた輪講は、オフィスに置いてある本を利用して同じ場に集って実施していましたが、新型コロナウィルスのためオフィスに出社することが困難となりました。
そこで、それまで開催していた輪講を中断し、新しい教材で輪講を開始することにしました。しかし、普段であれば同じ場所でホワイトボードを使いながらしていたような議論ができなくなり、新たな輪講の形式を模索する必要がありました。
教材の選定理由
まず輪講の教材として、統計的機械学習の数理100問 with Pythonという本を選びました。この教材はタイトルの通り、機械学習の基本的な内容を全100問の問題を解きながら身につけようという内容になっています。
今回こちらの本を採用した理由は以下の3つです。
- 内容が基本的で、応用範囲が広い
- 数式に対応したソースコードが載っている
- 演習問題が大量にある
内容が基本的で、応用範囲が広い
今年度はZOZO研究所に新卒のMLエンジニアが配属されたため、機械学習の基本的な内容を学べる教材が適していました。また、ZOZO研究所には様々なバックグラウンドの研究者が集まっており、専門も機械学習に限らず数理最適化・制御理論・コンピュータグラフィクスなど幅広いです。それらの最新の知見は別途論文の輪読会や技術共有会などを開催して常にキャッチアップしています。
そのため、輪講ではより基本的なレベルでかつ多くのメンバーに役立つような内容を扱うよう意識しました。
数式に対応したソースコードが載っている
ZOZO研究所は機械学習に関するシステムを開発することも多く、理論と実装の両方を学べる教材が望ましいです。採用した教材は、Bitbucketのリポジトリに本文中の登場するソースコードを全て公開しており、そのような用途に適していました。
演習問題が大量にある
演習問題を解くためには、自然と教材を読み込まざるを得ないので理解が捗ります。過去に別の輪講を主催していた際には演習問題がない教材を扱っていたのですが、流し読みで終わる人と、実際に手を動かす人では内容の理解度に差がついていました。
そこで、演習問題が大量にある教材を選び毎回1人1問をノルマに演習問題の解答を作成してもらうことで、曖昧な理解なままで終わるのを防止しました。
輪講の進め方
輪講は週1回90分の時間をとって開催しました。以下が1回の流れです。
- 事前準備
- 該当範囲の本文を読む
- 担当の演習問題を解いて、解答をGitHubにPull Requestとして提出
- 疑問点を社内Wikiに記載
- 輪講当日
- 各自が担当した問題の解答を画面共有しながら解説
- 社内Wikiに記載された疑問点を全員で議論
- 輪講後
- その日の議論の内容を社内Wikiに記載
- Pull Requestの解答に問題がなければマージ
上述の事前準備を参加者全員がすることで輪講をスムーズに進めることができました。作成した解答はGitHubリポジトリのmainブランチへ、Pull Requestとして提出してもらいますが、詳細は後述します。なお、輪講後のタスクは、幹事である私が担当していました。
以上の形式で進めると、議事録である社内Wikiには、我々がハマった箇所とそれに対する解決策が全て記載されることになります。これにより、輪講へ途中参加する際のキャッチアップが容易になるだけでなく、輪講終了後にも教材を独学する人の助けとなる資料が完成します。
また、今回上記の教材を読むにあたって、問題を解くと同時に本文中のソースコードのリファクタリングも行いました。特にコーディングスキルの高いメンバーはよりスマートな実装や、より速い実装を提案してくれます。それらを共有することで、ベテランから開発経験の浅いメンバーに対してうまく技術を伝達する機会を作ることができました。
輪講運用のための仕組みづくり
テレワーク環境下では気軽にホワイトボードを使って議論ができません。今回採用した教材はソースコードを書くだけでなく数式を使って計算・証明をする演習問題も多く、それらをどのように参加者間でスムーズに共有するかという点に課題がありました。
そこで、以下に述べる工夫をしました。
Jupyter Notebookによる統一
数式の記述であればTeXファイルが望ましいですが、GitHub上でTeXファイルの数式は表示できません。
そこで、各自担当する演習問題の解答は、全てJupyter Notebookファイルで作成するようにしました。Jupyter Notebookファイル上でLaTeX記法を用いることにより、GitHub上で数式を表示できるためです。なお、本文中のソースコードは全てJupyter Notebookファイルで公開されていたことも理由に含みます。
Jupyter Notebook用diffツールの採用
Jupyter Notebookファイルの中身はJSON形式なので、リファクタリング前後の差分をGitHubのWeb画面上では綺麗に表示できません。
そこで、Jupyter Notebookファイルの差分を綺麗に表示できる、nbdimeを導入しました。

上図は、nbdimeでリファクタリング前を左半分に、リファクタリング後を右半分に表示したものです。
ライセンスの明記
公開されているソースコードのリファクタリングを試みる場合、複製・配布・改良の範囲はOSSライセンスによって決定されます。今回選んだ教材のソースコードには、ライセンスが未記載だったため、そのまま使用すると著作権侵害に該当する恐れがありました。
そこで、教材の著者に公開されているソースコードのライセンスを明記していただきました。これにより、社内のリポジトリへの複製が可能になり、ソースコードを改変できるようになりました。
演習問題ごとにファイルを新規作成
演習問題1問につき、1つのJupyter Notebookファイルを新規作成し、そこへ解答を記載するようにしました。教材の演習問題は100問と非常に多いので、章ごとにJupyter Notebookファイルを作成することも考えました。しかし、同じJupyter Notebookファイルを共同編集することでコンフリクトが発生しかねないので、このような方針としました。
また、公開されているソースコードは章ごとに1つのJupyter Notebookファイルでまとめられており、それを元にリファクタリングしたJupyter Notebookを新規作成しました。
Pythonの環境構築
Pythonのバージョンを指定し、必要なパッケージはrequirements.txtを配布することで、参加者全員が同一の環境でコーディングできるようにしました。Pythonのバージョンを指定したのは、公開されているソースコードのJupyter Notebookファイルのメタデータに実行されたPythonのバージョンが記載されていたためです。
ここで考慮すべき点は、全ての公開されているソースコードが動作するようなrequirements.txtを作成することです。
公開されているソースコードはJupyter Notebookファイルのみで構成されており、その中でimportが適宜記載されているスタイルでした。また、我々はnbdimeなど教材に記載されていないパッケージも利用していたため、requirements.txtが自明ではありませんでした。
試しに、パッケージのバージョン指定をせずにrequirements.txtを手動で作成したところ、依存関係でインストールエラーが発生しました。そこで、Poetryで依存関係を解決しrequirements.txtを作成しました。なお、pandasなどのバージョンが変わるとメソッドが変わってしまうパッケージはマイナーバージョンまで固定しました。
ちなみに、Pythonパッケージの依存関係を解決するだけでは、パッケージが問題なく動作するとは限りません。例えば、LightGBMはインストールでエラーにはなりませんが、import実行時にエラーが発生します。この場合、事前にbrew installで必要なパッケージをインストールする必要あったので、その旨をGitHubリポジトリに明記しました。
Poetryを利用したのはあくまでも、初めの段階でパッケージの依存関係を解決するためだけであり、参加者各自が環境構築する際はrequirements.txtで行っていました。後になって考えると、Pythonのバージョンを明示的に指定できて、仮想環境も自動作成されるPoetryで環境構築した方が良かったのかもしれません。今後の改善ポイントです。
フォーマッタの検討
解答の作成やリファクタリングは、各メンバーが個別に行うため、コーディングスタイルに細かい差が出てしまいます。
そこで、Jupyter Notebookファイルのフォーマッタとしてnb_blackを導入することでコーディングスタイルの統一を目指しました。
nb_blackを使うには、それをインストールした上で、%load_ext nb_blackまたは%load_ext lab_blackという文字列が入力されたセルを実行します。すると、後に実行されるセルに対してBlackのフォーマットが適用されます。なお、上記nbdimeの使用例の図の右側は、nb_blackを実行済のソースコードです。
他の選択肢としてJupyter Blackもありましたが、これはGUIで実行するものであり、後述するGitHub ActionsやGitHub Webhooksと相性が悪かったので見送りました。
フォーマットチェックの自動化
nb_blackが適用されていることをレビュアが毎回確認する手間を減らすため、GitHub Actionsを用いてフォーマットチェックを自動化しました。
実際に使用したワークフローを以下に示します。
Pull Requestが作成される度に、%load_ext nb_blackまたは%load_ext lab_blackがJupyter Notebookファイルに含まれているかチェックしています。チェックを通過しないPull Requestはmainブランチへのマージができないようにしました。
name: Python nb_black on: push: branches: [ main ] pull_request: branches: [ main ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python 3.7 uses: actions/setup-python@v2 with: python-version: 3.7 - name: Check code style with nb_black run: | count=0 for file in $(find . -not -path "*/\.*" -and -not -name "textbook_??.ipynb" -and -type f -name "*.ipynb"); do chk_nb_black=$(cat $file | jq '.cells[] | select(.cell_type == "code").source[] | contains("%load_ext nb_black")') chk_lab_black=$(cat $file | jq '.cells[] | select(.cell_type == "code").source[] | contains("%load_ext lab_black")') if [[ $chk_nb_black == *true* ]] || [[ $chk_lab_black == *true* ]]; then echo OK : $file elif [ -z "$chk_nb_black" ]; then echo OK : $file else count=$(( count + 1 )) echo NG! : $file fi done if [ $count -gt 0 ]; then exit 1 fi
実は、ここで行われている判定はあくまで文字列が存在するかどうかについてであり、実際にフォーマッタが実行されているかどうかは確認していません。
例えば、コーディングを全て終えてから%load_ext nb_blackとセルに入力すると、Blackが実行されていないもののGitHub Actionsのチェックを通過してしまいます。Blackが実行されたかどうかを厳密にチェックすることも考えましたが、そこを厳格化するための費用対効果は低そうだったので、このような簡易的な確認で十分と判断しました。
なお、Pull Request時に自動判定する機能はGitHub Actionsの他にGitHub Webhooksもありますが、今回は実装が容易なGitHub Actionsを採用しています。
コミュニティへの貢献
他の参加者に解説できるくらい教材を丁寧に読み込んでいくなかで、細かい誤植を見つけることがありました。このような誤植は社内Wikiで逐次報告されるため、社内のメンバーに対しては誤植が原因で進まないという状況は減らせました。しかし、同じ教材を読み進めている社外の方たちは同じ問題に直面するはずです。
そこで、教材の著者が主催しているFacebookグループにも、逐次報告しました。すべての報告を著者自身に確認していただき、その都度、疑問を完全に解消していきました。
その結果、報告した内容は全て公式の正誤表に掲載され、新しく出版された英語翻訳版ではその箇所が修正されました。この貢献を認めていただき、英語翻訳版の謝辞には私の名前が掲載されています。
なお、弊社はOSS活動を推奨しており、OSS活動は職務として認められています。
これは余談ですが、過去1か月以内にFacebookグループで最もエンゲージメントの高い投稿をした人に与えられる「Facebookの盛り上げ達人」という謎のバッジを獲得しました。また、著者が出版した続編の帯には「Facebookページが盛り上がっています」と記載されているのですが、この盛り上がりの一端を担っているのは我々ZOZO研究所のメンバーであろうと想像しています。

参加者への事後アンケート
輪講終了後、参加メンバーに対してアンケートを実施しました。「参加してよかったか」と「業務に(直接的でも間接的にでも)活かせそうか」を、5段階で評価してもらった結果が以下の図です。
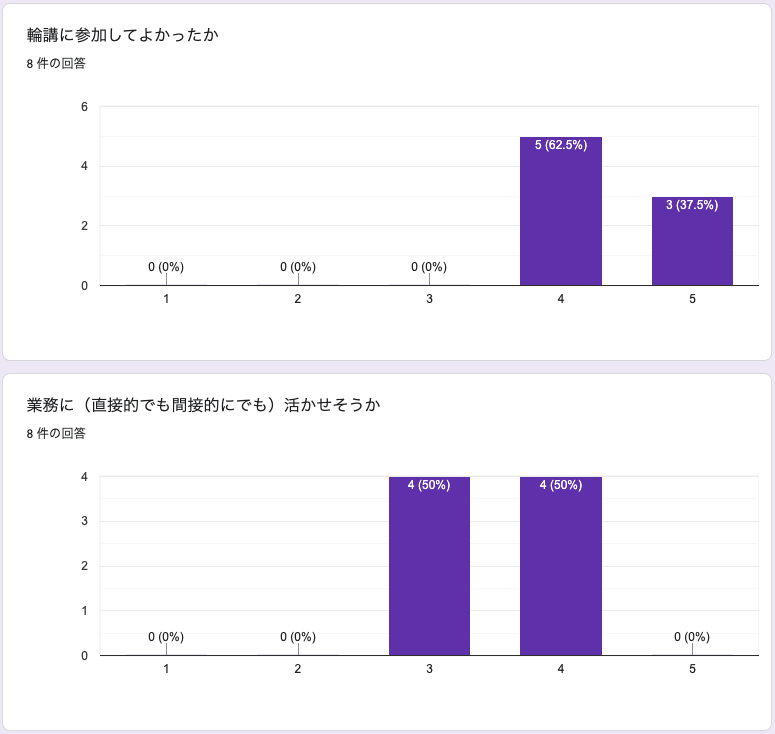
多くの参加者が「参加してよかった」とポジティブに感じてくれたようです。実際に、議事録やGitHubを上手く使いこなすことで議論が白熱したり、詳しい人からの知識の伝授が発生したりとテレワーク環境下でも問題なく輪講が実施できました。
業務に活かせるかに関しては、控えめな結果となりました。教材の内容が機械学習の基本的な内容であるため、特定のタスクに特化した知識は得られないことと、機械学習の数理部分が機械学習システムの開発のごく一部でしかないことを反映しているのだと考えています。
まとめ
テレワーク環境下で初めて輪講を行い、そこで得られた知見を本記事にまとめました。また、輪講のシステムのために幹事として準備したこともまとめ、結果として教材の謝辞に名前が載ることになりました。
そして、輪講参加メンバーに対するアンケートでも、概ね好意的な評価が得られました。読者の皆様がテレワーク環境下で輪講や勉強会を開催する際に、本記事の内容が少しでも参考になれたら幸いです。
おわりに
ZOZOテクノロジーズでは、各種エンジニアを募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。