



はじめに
こんにちは、Selenium 4の正式版がなかなかリリースされなく、ソワソワしている品質管理部・自動化推進ブロックの木村です。
私が所属する品質管理部は、ZOZOTOWNやWEARなどの開発プロジェクトに対してテスト・検証を行い、完成品がユーザーの手に届いても問題ないかを確認する部署です。その品質管理部では、先日、部署で開発運用しているSeleniumによる自動テストのシステムをオンプレからAWSに移行しました。自動テストの書き方や、個々のAWSサービスの使い方の記事は多く存在するので、本記事では自動テスト全体の概要を紹介します。単純な移行だけでなく、サーバレスやマネージドサービスを活用しているので、部分的にでも参考になる点があれば幸いです。
背景
品質管理部が行っていたリグレッションテストやシステムテストを部分的に自動化するために、Seleniumによる自動テストのシステムを開発し、複数台のオンプレサーバで運用してきました。しかし、それらのサーバを撤去する必要が出てきたため、運用のしやすさや将来的な拡張性を考えてクラウド移行することにしました。
クラウド環境の選定
最初に、クラウド環境を選定する必要があります。社内で主に利用されているAWSかGCPのどちらに寄せるのかを検討しました。
検討の結果、AWSを選定しました。その理由は、スマートフォンのアプリのテストの存在にあります。これまでもAppiumを使ったスマートフォンアプリのテストを行っています。クラウド移行に際し、AWSであればAWS Device Farmを利用すれば、ある程度既存のソースコードを流用したまま移行できる可能性があると考えました。一方、GCPの場合は、Firebase Test Labではソースコードを完全に切り分け、新しく用意する必要が出てくることが懸念点でした。
自動テストの仕組み
今回の移行対象となる自動テストを行うシステムは、テスト処理だけではなく運用面の機能も含め、主に下記5つの機能を有しています。
- Seleniumによるテスト処理
- 実行管理とスケジュール
- 設定と結果の管理
- 結果の閲覧
- ソースコード管理とビルド
これらの全ての機能をそのままEC2に移行してしまえ、という話もありました。しかし、AWSに移行する良い機会なので、移行期間の短縮よりもAWSの特性を活かした移行を実現させることを優先させ、移行対応を機能ごとに分けて進めました。
Seleniumによるテスト処理
移行前後でテストの仕組みがどのように変わったのかを下図で示しています。
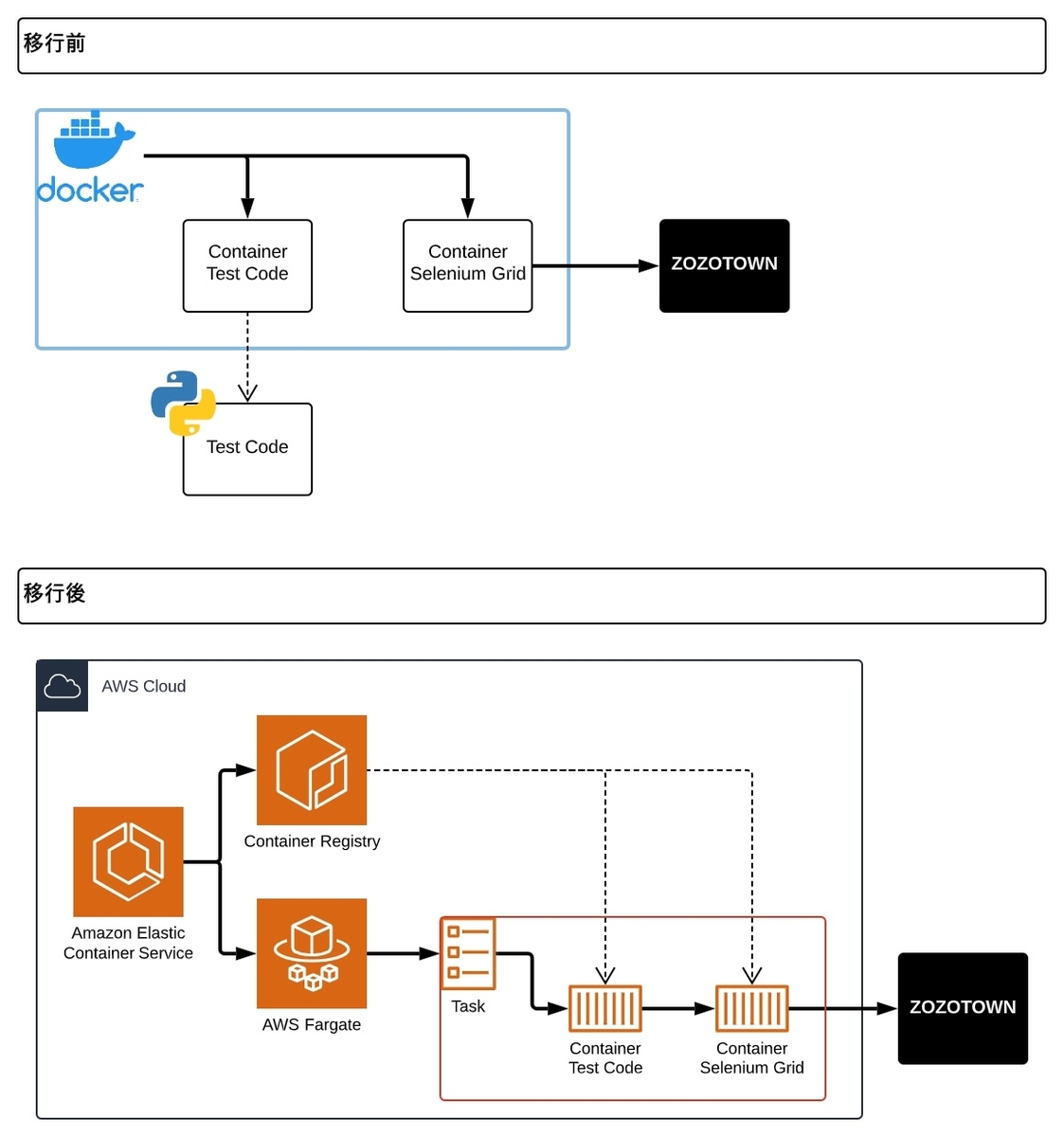
移行前はSeleniumのテストコードをマウントしたDockerコンテナを起動し、別コンテナで起動したSelenium Gridを利用してブラウザを操作していました。
その構成を、移行後はECS(Elastic Container Service)のFargateを利用することにしました。Dockerを利用していたので、移行自体は簡単に行えました。
ECSがタスクを起動し、ECR(Elastic Container Registry)からコンテナイメージを取得してコンテナを起動します。テストコードが実行されるとSelenium Gridコンテナに接続し、ブラウザを利用したテストが実施されます。
なお、テストコード用のコンテナには複数のテストが含まれており、実施するテストによって起動時に渡す環境変数で使い分けています。
初めてECSを触った時は、コンテナ同士の接続はどうなるのだろうと疑問でした。しかし、同一タスクで立ち上げられたコンテナは同じ環境内に起動されるようでした。そのため、同一タスク内でテストコード用のコンテナとSelenium Grid用のコンテナを立ち上げれば、テストコードからは定番のlocalhost:4444でブラウザに接続できます。
その他にもいくつか検討・工夫した点があるので紹介します。
ブラウザの起動方法
前述の通り、検討初期段階ではコンテナ間の接続は困難だろうと思い、PythonとChromeブラウザをインストールした1つのコンテナにテストコードを入れる形式にしていました。しかし、この方法だとSeleniumでありがちなバージョン管理が煩雑になるという問題がありました。
そもそもこの問題を解決するためにSelenium Gridを利用しています。そして、調査を進めていくうちに接続が問題なく可能なことも分かったので、最終的にはコンテナを分けた構成にしています。
AWSのIPからの開発環境へのアクセス方法
当然のことながら、AWSに移行すると社内ネットワークから外れます。テスト対象が接続元IPで制限されている可能性を考慮し、NAT Gatewayを一時的に構築しました。結論としては、テスト対象が全てインターネット上に公開されているものだったため、NAT Gatewayは廃止しました。テストの要件次第で柔軟に対応する必要がある注意ポイントです。
実行管理とスケジュール
移行前後で実行管理の仕組みがどのように変わったのかを下図で示しています。
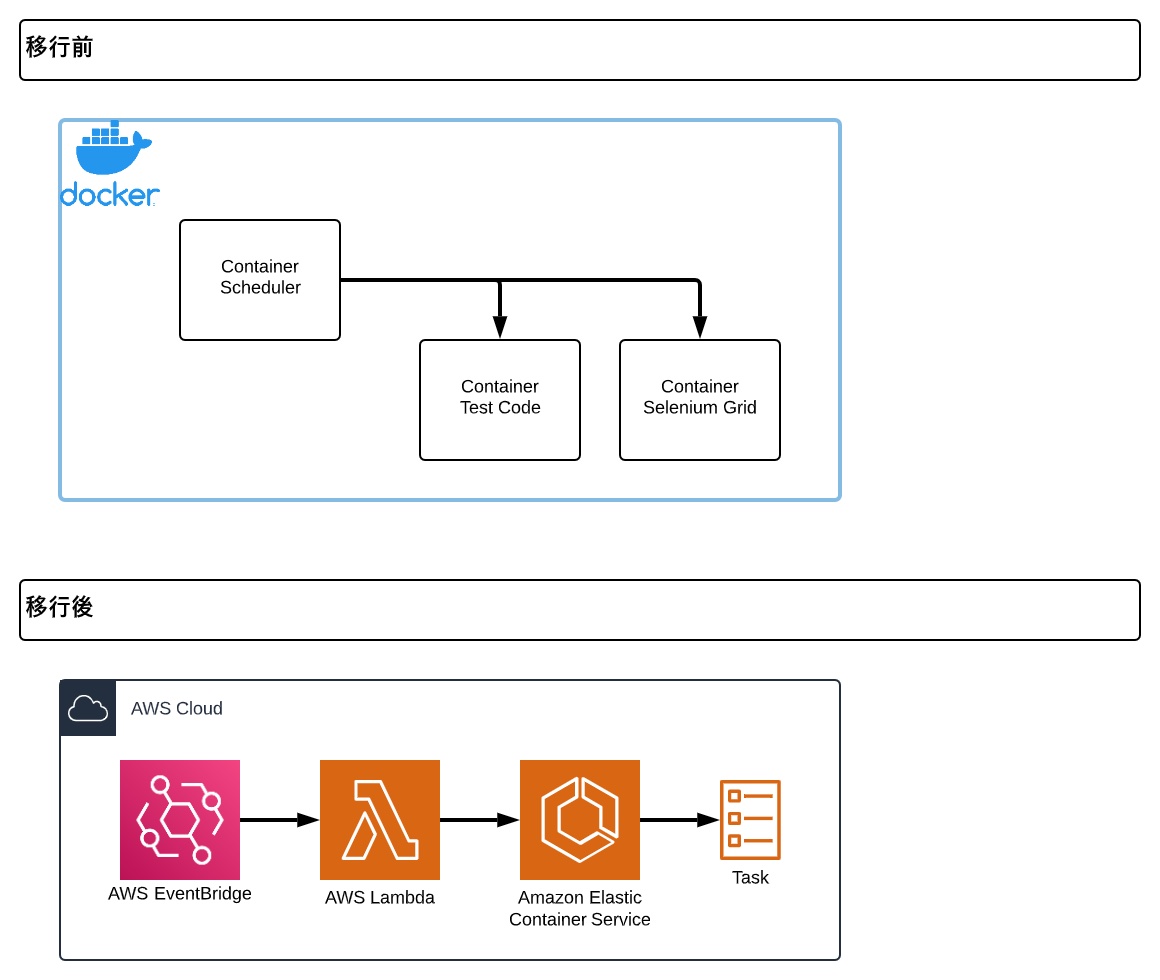
移行前はスケジュール管理のためのソースコードが入ったDockerコンテナを起動しておき、そのコンテナからSeleniumのテストを実行するコンテナを立ち上げる構成でした。
移行後は、EventBridgeを活用する構成に変更しています。EventBridgeから直接ECSを呼び出すことも可能ですが、臨時でテストを実行したい場合に、ECSのコンソールからタスクを起動することが手間だったのでLambdaを経由する構成にしました。
そして、EventBridgeは指定の時刻になったらLambdaを実行します。この際に実行するテスト情報をJSONで渡します。Lambdaは受け取ったテスト情報を環境変数に入れた上で、ECSのタスクを起動します。
また、臨時でテストを実行したい場合には、LambdaのコンソールからワンクリックでECSタスクを起動できます。さらに、API Gatewayなどを用意しておけば外部からの実行も可能です。
なお、EventBridgeを利用していて気になる点は、Webコンソールのフォームデザインです。EventBridgeの入力設定で定数(JSONテキスト)を使用していますが、その入力がテキストエリア(複数行)ではなくテキストフィールド(一行)になっているため、多少の使いにくさがあります。
設定と結果の管理
移行前後で設定と結果の管理の仕組みがどのように変わったのかを下図で示しています。
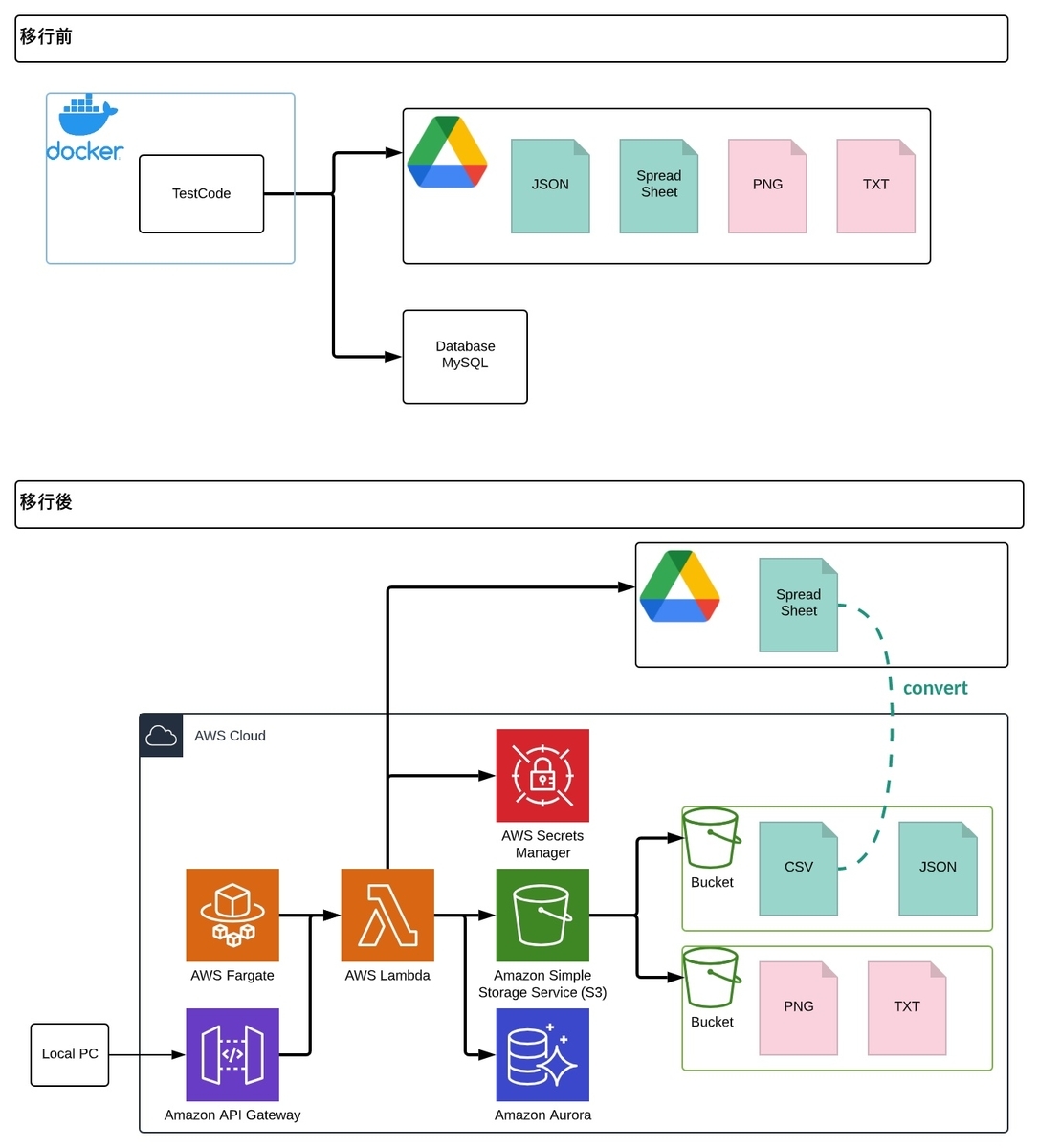
移行後の仕組みを、順を追って説明します。
- 設定の保存先
- 結果の保存先
- 設定と結果の取得
設定の保存先
設定に関する情報は、「テスト設定」と「ケース設定」の2種類が存在します。
前者の「テスト設定」はテスト全体に影響する情報、例えばテスト対象URLなどが含まれるJSONファイルです。このJSONファイルはそのままS3に保存します。
後者の「ケース設定」は、テストの中に含まれる個々のケース(手順)が記載されるものです。Googleスプレッドシートで管理し、利用時にCSV形式でS3へ保存します。実際にケースを管理するチームが品質管理部とは別なため、誰でも気軽に触れられるという理由でスプレッドシートを採用しています。
なお、ケース情報のCSVをそのままS3に置いた場合、S3上ではファイルの編集が行えないため、毎回ダウンロードする必要があります。一方、DBで管理しようとするとDBやクエリに関する知識が必要になってしまい、運用メンバーへの負担となってしまいます。そのため、スプレッドシートを使って複数人で気軽に編集できる状態は維持しつつ、Lambda経由でCSVへ変換できるよう、その仕組みを実装しました。
結果の保存先
結果として出力されるものにも2種類あり、テストの実行時に取得されるスクリーンショット画像やログなどの「出力結果」と、最終的にテストが成功・失敗したのかの情報がまとまった「テスト結果」が存在します。
前者の「出力結果」は、前述の通りスクリーンショット画像やログなどが含まれます。テスト結果がNGの場合に調査に利用するファイル群なので、運用するチームなら誰でも見れるよう環境である必要があります。なお、このファイル群は編集する必要性がなく、閲覧のみで問題ないのでS3に保存しています。
後者の「テスト結果」は、テストケース毎に成功・失敗したのかの結果を含んだ情報であり、DBに保存しています。この情報を元に、後述の結果を表示するWebページの作成や通知に利用しています。なお、このDBはMySQLを利用していたので、そのままAurora MySQLに移行しています。
移行先のAurora MySQLはサーバレスを選択しています。そのため、プロビジョニングされたDBクラスタと比べ、制約も多くあります。しかし、アクセスが低頻度や断続的、または予測がつかない場合には有効な選択です。クラスタ自体の運用も不要になるメリットがあります。今回も、社内の自動テストのための環境なので、アクセス数には大きな波があります。少々接続に時間を要したとしても、許容可能です。これらを踏まえ、サーバレスを選択しました。
設定と結果の取得
テストの定期実行以外にも、WebコンソールからトリガーとなるLambdaを実行すれば、任意のタイミングでテストを開始できます。とはいえ、実際の運用では手元のPC上で実行したいものです。そこで、各種設定や結果はAWS内だけではなく、ローカルからのアクセスも考慮しています。
その考慮のために、下記の処理をLambdaで1つずつ作成し、API Gatewayから実行できるようにしました。
- 指定したスプレッドシートからCSVをダウンロードする処理
- 渡されたファイルをS3に保存する処理
- テスト結果をAuroraにインサートする処理
なお、Googleスプレッドシートへのアクセスに必要な接続情報や、Auroraへの接続情報はAWS Secrets Managerに保存しています。
結果の閲覧
移行前後で結果の閲覧の仕組みがどのように変わったのかを下図で示しています。
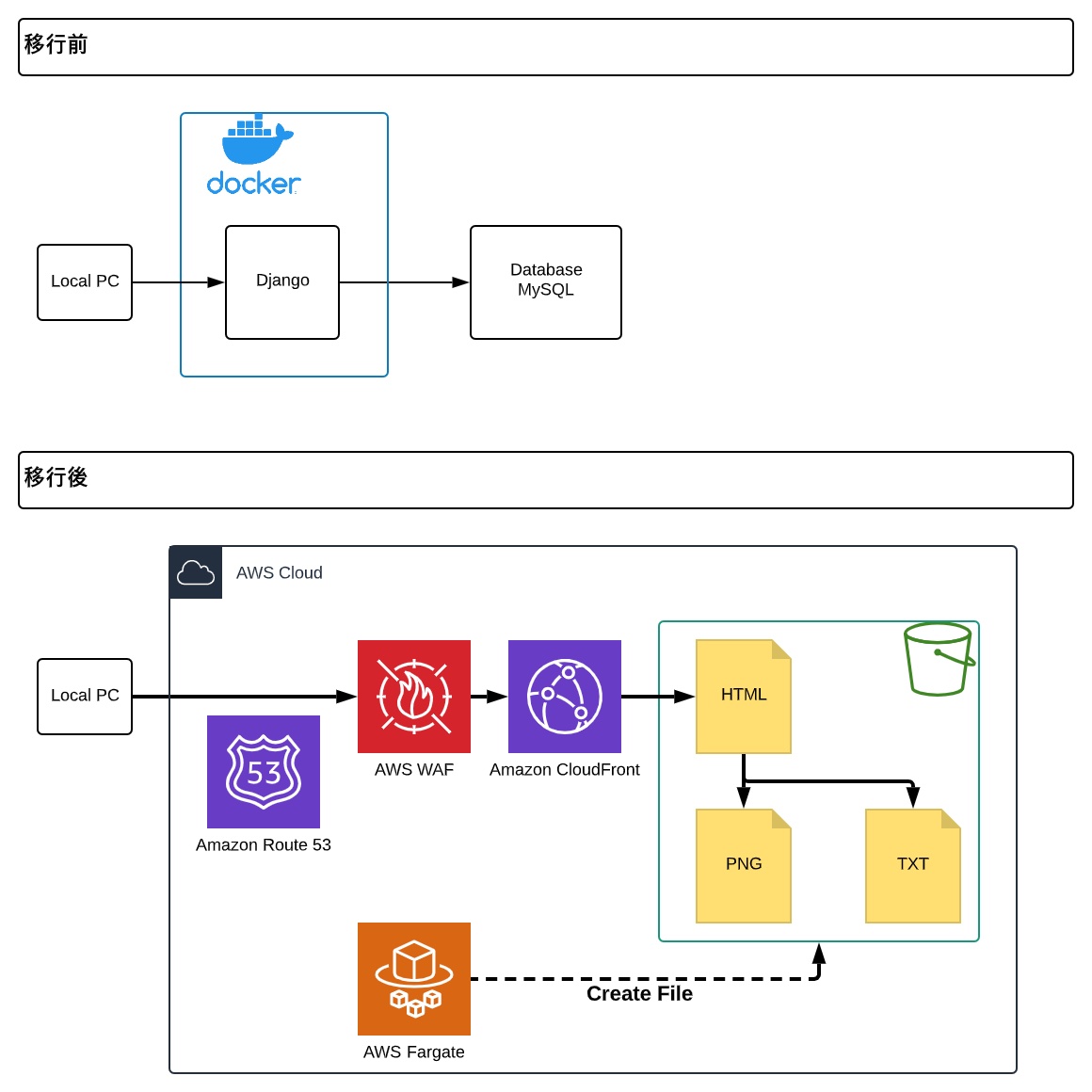
移行前の構成では、DBに保存された結果を閲覧できるようにDjangoを使って簡易的なWebページを作成していました。このWebページは結果閲覧だけでなく、設定変更やスケジュール変更といった機能も有していました。しかし、この仕組みはクラウド移行前から廃止する方向で検討していたこともあり1、移行後は用途を結果閲覧だけに絞ることにしました。最終的に、移行後はS3で静的Webサイトを表示する仕組みになりました。
テスト実行時のSeleniumのテストコードを改修し、最終結果が記載されたHTMLファイルを出力する処理を追加しました。出力されたHTMLファイルは、テスト結果のファイルと同様にS3 Bucketに保存します。WAF、CloudFrontを経由して接続を制限しながら、外部からHTMLファイルにアクセスできる環境を構築しました。
現状の要件では、結果の閲覧のみで良いのでこの形式を採用しています。今後、他の機能を拡充する必要が出てきたら、改めて動的な処理が必要となることが見込まれます。
ソースコードの管理とビルド
移行後に新しく導入した、ソースコード管理とビルドの仕組みを下図で示しています。
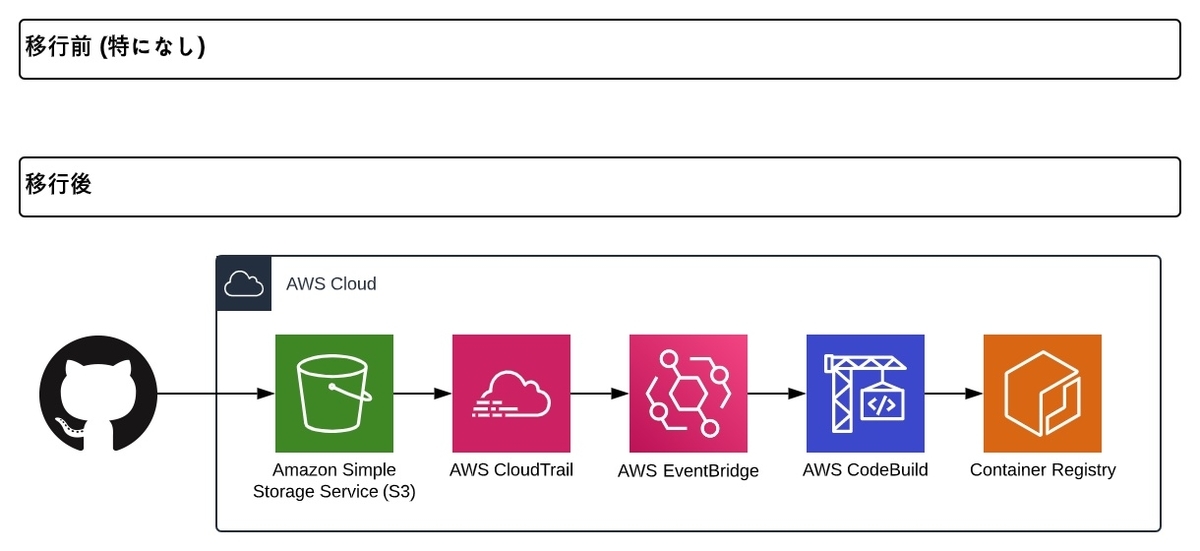
移行前は特に仕組みを用意しておらず、GitHubから更新されたソースコードをサーバ内でgit pullしていました。しかし、移行後はECSを利用するため、コンテナイメージを作成してECRにpushする必要があります。そのため、GitHubと連携させ、ビルド作業を効率化させました。
手順の大きな流れは以下の通りです。
- GitHub Actionsを利用してテストコードをZIP化
- ZIPファイルをS3に保存
- CodeBuildがZIPファイルからコンテナイメージをビルド
- ビルドしたコンテナイメージをECRにpush
なお、CodeBuildはS3のイベント通知を受け取れないので、ビルドの自動開始のためにEventBridgeやCodePipeline、Lambdaなどを挟む必要があります。今回は扱いやすさを優先し、EventBridgeを選択しました。
また、EventBridgeでS3のputを検知するために、CloudTrailも利用しています。なお、その設定の際に必要な項目は、EventBridgeのイベントパターンや、S3バケットのバージョニング有効化など多岐に渡ります。詳細は下記のドキュメントを参照してください。
- チュートリアル: EventBridge を使用した Amazon S3 オブジェクトレベルの操作のログを記録する - Amazon EventBridge
- Using dynamic Amazon S3 event handling with Amazon EventBridge | AWS Compute Blog
また、本来ならGitHub Actionsでコンテナイメージをビルドし、そのままECRにプッシュする方がシンプルで綺麗です。しかし、将来利用を予定しているDevice Farmは実行時にテストコードのZIPファイルが必要です。そのため、上記のようにコンテナイメージとZIPファイルの両方を揃える形式にしています。記事の冒頭でも触れた、Appiumを使ったテストのDevice Farm対応は順次対応中です。
まとめ
本記事で紹介した、AWS上のSelenium自動テストシステムの構築図は以下の通りです。
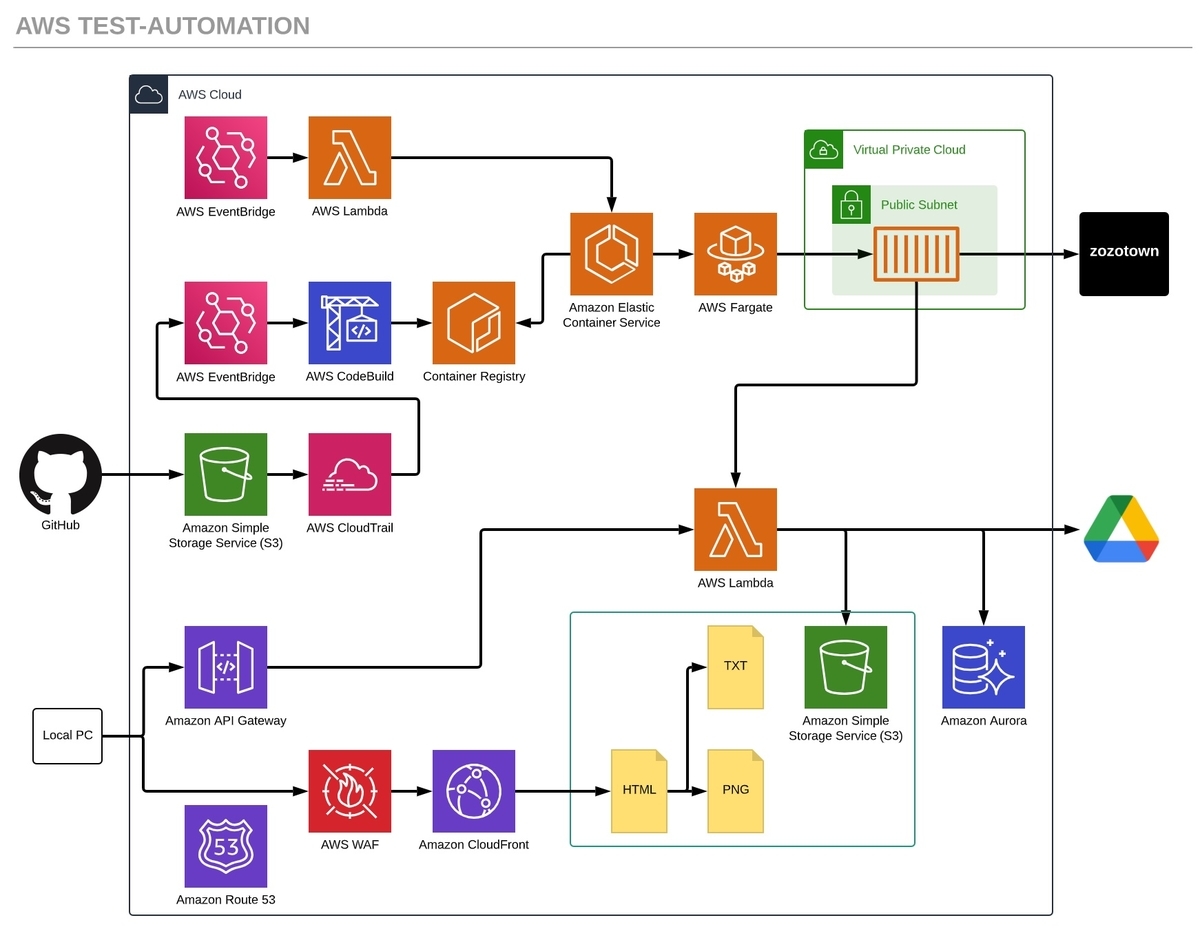
まだ不足部分もあるため、現在も取り組みを続けています。設計段階で、各処理を小分けにしたことで部分的な改修や切り替えが行いやすくなったと実感しています。
最後に
ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからご応募ください!
-
チームメンバーの全員がDjangoを扱えるわけでもなく、筆者一人で開発運用していた状態でした↩