




こんにちは、SRE部ZOZO-SREチームに2020年新卒入社した秋田です。普段はZOZOTOWNのオンプレミスとクラウドの運用・保守・構築に携わっています。
ZOZOTOWNのオンプレミスは17年の歴史があり、BIG-IP、FortiGate、vSphereなどの様々なベンダーの製品が稼働しています。さらに、ZOZOTOWNのサービスが大きくなるにつれてオンプレミスでの拡張も続けていました。
そのようなZOZOTOWNですが、VMware Cloud on AWSを活用することでオンプレミスとパブリッククラウドを掛け合わせた柔軟なインフラを構築しています。実際に、昨年から大規模なセール時に、オンプレミスを拡張するのではなくVMware Cloud on AWSを活用したサーバー増強をしています。
本記事では、ZOZOTOWNのオンプレミス環境の自動化で利用しているAWXについて、チーム内での活用方法や運用方法を実際のセールの事例を用いて紹介します。なお、その一環でOSSとしてaction-ansiblelintの公開も実現しています。
AWXとは
まず初めにAWXについて紹介します。AWXは、AnsibleをWebアプリケーションで管理し、REST APIやタスクエンジンを提供しているOSSです。
また、AWXは商用版のRed Hat Ansible Tower(以下、Ansible Tower)のアップストリームプロジェクトです。
AWXとAnsible Towerの大きな違いとしては、専門的サポートが受けられる点や安定かつ安全に利用できる点です。AWX/Ansible Towerでは、日本語のドキュメントも提供されており、日本のユーザーはインストールガイドやユーザーガイドなど様々な情報を容易に得ることができます。
私たちのチームでは、コスト面やAnsibleの利用経験が浅いことを考慮し、商用版のAnsible TowerではなくOSSのAWXを利用しています。
取り組み以前のAWXに関する課題
今回紹介する取り組み実施前は、AWXを導入した前任者が別チームに異動したこともあり、いくつかの課題がありました。
- Ansible Playbookがローカル管理されていた
- 確立された運用方法がなかった
各課題についてどういったアプローチをとったか説明します。
課題1:Ansible Playbookがローカル管理されていた
オンプレミスではAWX検証環境とAWX本番環境の2つの環境があり、それぞれでコードも違う状態でした。AWX検証環境とAWX本番環境のコードは同じ状態が望ましいため、AWX検証環境のコードをAWX本番環境のコードに統一することとしました。
そして、ローカルで管理されていたAnsible Playbookのコードは、GitHubへ移行することにしました。しかし、チームにおけるGitHubの利用ルールや使い方が定まっていなかったので、同時に策定する必要がありました。
まず、新規作成したリポジトリでAWX検証環境用のブランチ(例:dev)とAWX本番環境用のブランチ(例:prd)を用意し、それぞれGitHub上にコードを上げました。AWX本番環境用のブランチをAWX検証環境用のブランチにマージすることで、差分があった箇所はAWX本番環境のコードに統一できました。
また、git-flowとGitHub Flowを参考にチームでGitHubの利用ルールを作成しました。利用ルールと同時にGitHubの使い方についてもまとめました。これは、今後、都度修正していく前提で作成しています。
利用ルールとして定めたものを一部紹介します。
- mainブランチは常に本番稼働・実行できる状態にする
- 作業用ブランチをmainブランチから作成する
- 作業用ブランチは定期的にプッシュする
- プルリクエストによるレビューを必須とする
- プルリクエストでレビューが完了したらmainブランチへセルフマージする
- releaseブランチを用いて本番リリースする
- reset、cherry-pickはしない
ルールをさらに具体化するために、使い方として以下のような流れをまとめました。
- mainブランチから作業用ブランチを作成して、開発する
- 開発が完了したら、ローカル上で作業用ブランチに作業内容を日本語で簡潔に記載したコミットメッセージを添えてコミットし、GitHub上にプッシュする
- プルリクエストを作成する
- レビュー内容に応じて必要があればコードを修正して再度コミットとプッシュする
- 再度コードレビューをしてもらいアプルーブであれば、mainブランチにセルフマージする
ルールや使い方をまとめておくことで、チームメンバーにGitやGitHubの経験に差があったとしても、GitHubを使うことやGit操作に対してのハードルを下げることができます。
課題2:確立された運用方法がなかった
前任者が書いた構築・運用に関するドキュメントがあったので、そのドキュメントを参考に以下の方針を立て、運用方針の策定とドキュメント化を実施しました。
- 検証・本番環境ごとのAWX作業手順
- Ansible Playbookの記述方法
- 秘匿情報の扱い方
- AWXのメンテナンス方法
各方針について、以下で説明していきます。
検証・本番環境ごとのAWX作業手順
これまではAnsible Playbookがローカル管理だったこともあり、AWX検証環境とAWX本番環境の作業手順は以下のようになっていました。
- ローカルにProjectから参照できるAnsible Playbookを配置
- AWX上でテンプレートの作成
- テンプレートの実行、エラーがあれば修正
AWX本番環境では、AWX検証環境で作成したものをコピーして同様に作業していました。この方法では、AWX検証環境で検証はしているとはいえコードのAnsible Playbookで間違いがあった場合には、AWX本番環境でそれを実行して事故を起こしかねない状態でした。
Ansible Playbookの管理をGitHubへ移行すると同時に、作業手順と利用方法を見直しました。
まず初めに、GitHubをAWX検証環境とAWX本番環境に連携する設定をしました。具体的には、AWXのProjectのSource Code Management(以下、SCM)の機能を利用してGitHub上のAnsible PlaybookをProjectに反映させます。Projectの設定は、以下のドキュメントを参考にしています。
見直したAWX検証環境とAWX本番環境での作業手順が以下の通りです。
AWX検証環境での作業手順
- AWX検証環境用ブランチを最新の状態にする
- AWX検証環境用ブランチから作業用ブランチを作成する
- Ansible Playbookを作成し作業をする
- AWX検証環境で利用するためにコミットとプッシュを行う
- AWX検証環境でテンプレートを作成し、トライ&エラーを繰り返して開発を進める
- AWX検証環境で検証が完了後、検証環境用ブランチに対してプルリクエストを作成する
- プルリクエストをレビューしてもらい問題なければ検証環境用ブランチにセルフマージする
- プロジェクトを更新し、テンプレートのSCMブランチを削除する
レビューを必須とすることでAnsible Playbookの確認をチームで行い、作業ミスを減らすことができます。また、AWX上ではSCMの機能を使ってテンプレートを以下のように設定し、5.のステップを作業用ブランチで実行できるようにしています。
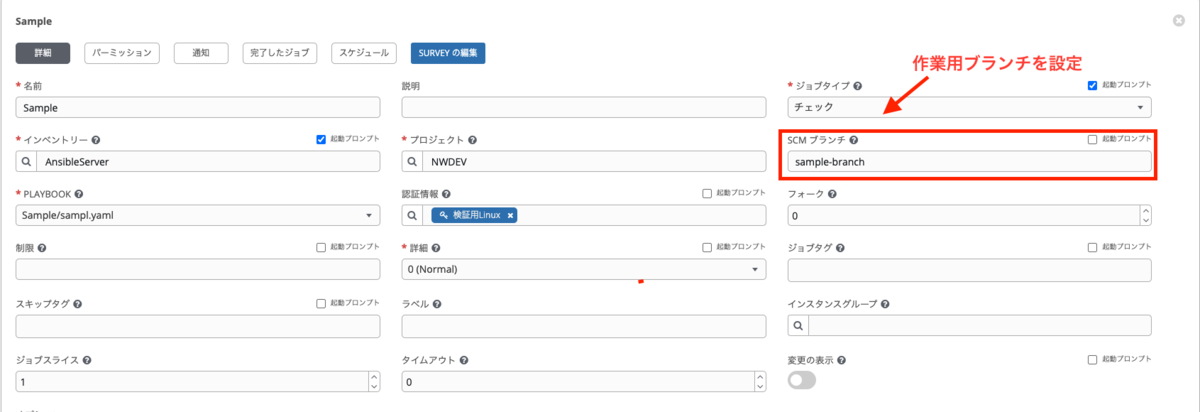
AWX本番環境での作業手順
- AWX検証環境用ブランチにマージされたタイミングで、GitHub ActionsによりAWX本番環境用ブランチへのプルリクエストが自動作成される
- 作成されたプルリクエストをセルフマージする
- AWX本番環境でテンプレートの作成、実行する
検証とレビューで問題ないことが保証されているため、セルフマージするようにしています。AWX本番環境では、AWX検証環境で作ったテンプレートをコピーするテンプレートを用意しており、同じものを作成する手間を省いたりしています。
Ansible Playbookの記述方法
これまでは、ローカル管理されていたこともあり、自由にAnsible Playbookが記述されていました。GitHub管理に移行したので、これを気にLinterを用いてAnsible Playbookの統一化することにしました。Ansibleでは、ansible-lintがLinterとして提供されています。
GitHub Actionsでプルリクエストにある差分のAnsible Playbookに対してLinterを実行するようにしています。reviewdogを用いることでプルリクエストにある差分のAnsible Playbookに対してLinterの実行が可能です。
reviewdogは、Linterの結果をプルリクエストのコメントに出力したりできます。詳しく知りたい方はREADMEや以下のドキュメントを参考にしてください。
reviewdogのコミュニティでは、GitHub Actionsで利用できるように多くのエンジニアが、それぞれの言語向けのLinterのActionを作成しています。
そこで、ansible-lint用のAction、action-ansiblelintを作成しました。
GitHub Actionのコードと実行結果を以下に示します。
name: Check Source Code on: [pull_request] jobs: ansible-lint: name: runner / ansible-lint runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-python@v2 with: python-version: 3.6 - name: Execute Ansible Lint uses: reviewdog/action-ansiblelint@v1.2.1 with: github_token: ${{ secrets.github_token }} reporter: github-pr-review

構文に間違いがあるとプルリクエストにエラー箇所をコメントしてくれるように設定しています。
OSSの開発については、弊社ではOSSポリシーがあり、スムーズに開発・公開でき、とても良い経験ができました。action-ansiblelint公開後はOrganizationをreviewdogに移す対応を行い、メンテナンスを定期的に行っています。
action-ansiblelintを作成したことで、誰でも簡単に利用できるようにする、かつコードの統一化といった最初の目的を果たすことができました。
秘匿情報の扱い方
当然のことですが、秘匿情報はGit上で管理せずAWXの認証情報で管理しています。認証情報ではSSHやネットワーク機器、クラウドのログイン情報などをサポートしています。
ローカル管理だった際には、認証情報でサポートされていない部分は直接Ansible Playbookに記述されていましたが、今回はその直接の記述を外す必要があります。
その際に、認証情報でサポートできない項目も出てきます。そのような時に便利なのがカスタム認証情報タイプです。
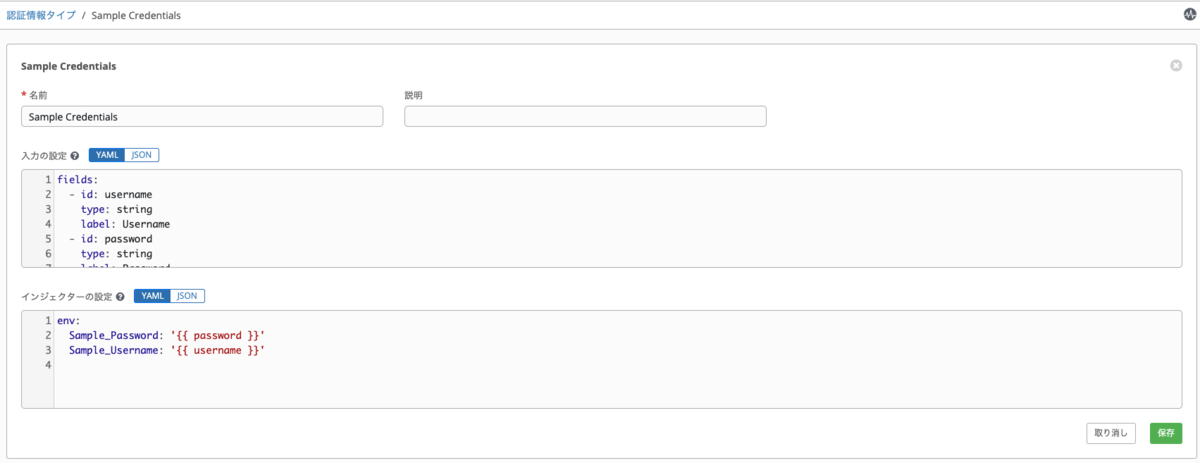
入力設定のところでYAML形式かJSON形式で以下のような認証情報を作成できます。
fields: - id: username type: string label: Username - id: password type: string label: Password secret: true required: - username - password
インジェクターの設定では以下のように記述します。
env: Sample_Password: '{{ password }}' Sample_Username: '{{ username }}'
設定すると以下のような表示になります。
作成した認証情報をAnsible Playbookで利用する場合は、Lookupプラグインを使うことで呼び出しが可能です。
- name: Set Fact
set_fact:
username: "{{ lookup('env', 'EXECUTION_USERNAME') }}"
password: "{{ lookup('env', 'EXECUTION_PASSWORD') }}"
このカスタム認証情報タイプを用いて、直接Ansible Playbookに記述していたユーザー名とパスワードを認証情報で管理できました。
AWXのメンテナンス方法
AWXのメンテナンスは、KerberosやDocker Composeを含んだ環境構築自動化のためのAnsible Playbookを用いて行います。そうすることで、新しいバージョンが出た際にも、別VMで環境を作成し検証できます。AWXの環境構築で使っているAnsible Playbookでは、インベントリーファイルの変数を使ってAWXなどのバージョンを切り替えられるようにしています。その他の部分も変数化しておくことで、柔軟な環境構築ができるようにしています。
localhost ansible_connection=local ansible_python_interpreter="/usr/bin/python3" [all:vars] # AWX version awx_version=17.0.1 # containerd.io containerd_io='https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.2.13-3.2.el7.x86_64.rpm' # Docker Compose Version docker_compose_version=1.26.0 # OS ## uname -s os_system=Linux ## uname -m os_architecture=x86_64 # 環境ごとに変更 server_env=dev
同時にバックアップ方法の確立も必要です。
AWX/Ansible Towerでは、APIを利用したCLIが提供されています。なお、AWXのCLIは、pip install awxkitでインストールできます。
CLIの基本的な使い方は以下のドキュメントに記載されています。
このCLIを用いてバックアップスクリプトを作成していた際に、エクスポート機能にinventoryのhostが取得できないバグを発見しました。そこで、issueを書いて以下のバグレポート上げました。
バージョン 15.0.0で対応され、エクスポート機能が利用できるようになりました。
このエクスポート機能を用いて、以下のようにエクスポートすることでバックアップを取得できます。
$ awx export > backup.json
このコマンドを実行するスクリプトを作成し、Cronで毎日バックアップを取得するように実行しています。
インポートもエクスポート同様、以下のコマンドで実行できます。インポートする際の注意点は、パスワードなどの秘匿情報はエクスポートされていないのでインポートした際には、手動でパスワードなどを再設定する必要がある点です。
$ awx import < backup.json
チーム内で勉強会を実施
上述した新しい運用方針を策定したので、それに伴って今までのAWXの利用方法に加えてGit/GitHubに関する勉強会を行いました。この勉強会の目的は、AWXの新しい作業手順を知ってもらいGit操作やGitHubに慣れてもらうことです。
勉強会内容は以下の内容です。
- BIG-IPの操作が可能なPlaybookの作成方法
- AWXのテンプレート、インベントリー、認証情報の作成方法
- Git/GitHubの利用方法
- AWXの検証環境と本番環境の利用方法
Red Hat社が定期的に開催しているワークショップに参加し、得られた知見はこの勉強会に反映しています。また、GitHub上にそのワークショップで利用するドキュメントが公開されているのでそちらの内容を参考にしています。
2021年の冬セール準備での実例
2021年の冬セールは、コロナ禍ということもあり、トラフィック量の予想がしづらい状況でした。そのため、去年の冬セールの2倍以上のサーバーをオンプレミスとVMware Cloud on AWSを組み合わせて準備することにしました。
新規サーバーの構築後、サービスインできる状態にするまでには、いくつかのステップが必要です。
- 新規作成したサーバーの設定ファイル変更
- ファイル配布サーバーの設定変更
- 新規作成したサーバに対して現行サーバーからのコンテンツ同期
- BIG-IPのノードにサーバーを追加
- BIG-IPのプールにサーバーを追加
この5つのステップの中で、2.は自動化が難しい部分ですが、3.に関しては既に自動化されていました。今回の冬セールに向けて1.・4.・5.の自動化を実施することにしました。
1.の自動化は、各サーバーに決まった値を設定値として指定するものでした。そのため、設定する値のリストを用意し、AWXで各サーバーに設定しました。
一方で、4.と5.ではbigip_nodeとbigip_pool_memberモジュールを利用して新しいサーバーを追加できるようにしました。
これらの自動化により、約10時間以上かかっていた作業が約2時間ほどに短縮されました。
また、これら以外にも、AWXのインベントリーに数百台規模のホストを追加する作業があります。インベントリーの作成でクラウドプロバイダーから同期する方法もありますが、弊社の環境ではグループごとに変数などを設定していたことから既存のインベントリーに追加する必要がありました。
そこで、カスタムインベントリースクリプトを利用しました。カスタムインベントリースクリプトを利用することで独自のインベントリーソースが作成でき、特定のグループに追加ができます。
PythonやShellなどで記述し、スクリプトとして実行できます。出力をJSON形式にすることで数百台をインベントリーのホストに登録できます。ここで示すスクリプトのサンプルは以下の記事を参考に作成しました。
スクリプトのサンプルと実行結果を以下に示します。なお、実行結果は一部省略しています。
#!/usr/bin/env python
from collections import defaultdict
import json
class SampleInventory(object):
def __init__(self):
self.inventory = {}
self.inventory = self.sample_inventory()
print(json.dumps(self.inventory, indent=2))
def sample(self, number):
# ホスト名
sample = "Sample" + str(number)
# 追加する台数
sample_num = 200
samples = []
for n in range(1, sample_num+1):
if len(str(n)) == 1:
# Sample0001 ~ Sample0009
samplexxxx = sample + "00" + str(n)
samples.append(samplexxxx)
elif len(str(n)) == 2:
# Sample0010 ~ Sample0099
samplexxxx = sample + "0" + str(n)
samples.append(samplexxxx)
else:
# Sample0100 ~ Sample0200
samplexxxx = sample + str(n)
samples.append(samplexxxx)
return samples
def sample_inventory(self):
multi_dimension_dict = lambda: defaultdict(multi_dimension_dict)
inventory = multi_dimension_dict()
inventory["sample_group"]["hosts"] = self.sample(0)
for sample in self.sample(0):
inventory["_meta"]["hostvars"][sample] = {}
return inventory
SampleInventory()
{ "sample_group": { "hosts": [ "Sample0001", "Sample0002", "Sample0003", #省略 "Sample0199", "Sample0200" ] }, "_meta": { "hostvars": { "Sample0001": {}, "Sample0002": {}, "Sample0003": {}, #省略 "Sample0199": {}, "Sample0200": {} } } }
このスクリプトでは、ホスト名Sampleの部分が共通部分で、そこに適宜数値を結合し、その結果をJSON形式で出力するようにしています。今回のサンプルでは取り入れていませんが、vSphereのAPIを活用すればもっといい書き方ができるでしょう。
まとめ
本記事ではZOZOTOWNのオンプレミス環境の自動化で利用しているAWXについて、チーム内での活用方法や運用方法を実際のセールの事例を用いて紹介しました。
Ansible Playbookのローカル管理を、GitHubでの運用へ移行することでコードの管理が容易になりました。また、CI/CDの導入によりコードの統一も実現できました。
運用方法の策定では、新しく利用方法や運用方法に関するドキュメントを作成し、チーム内でドキュメントの展開とAWXの勉強会をすることでAWXの知識の浸透を実現させました。
最後に
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!