




こんにちは。ZOZOテクノロジーズ開発部SREの田島(@katsuyan121)です。 弊社ではJBoss Data Grid(以下JDG)という分散キャッシュサーバーをマーケティングオートメーションシステムに導入し、キャンペーンのリアルタイム配信を実現しています。
JDGは複数台のサーバーでクラスタを組んでおり、先日そのクラスタがSplitBrainを起こしました。 SplitBrainとは、1つのクラスタが2つ以上のクラスタに分断することをいいます。 例えば、クラスタのノード間で通信が分断された場合などに、ノード同士で通信できなくなりSplitBrainが発生します。
調査の過程でJDGはどのような仕組みで動作しているのか、どのような原因でSplitBrainが発生したのか知見が溜まったのでそれを紹介します。 また、実際にSplitBrainの再現を行い対策を行ったのでそれについても紹介します。
JDGについて
インメモリDataGrid
最初にJDGを分散キャッシュサーバーと紹介しましたが、実際にはその名前の通りDataGridのPlatformになります。また、データはすべてメモリに保持されるためインメモリDataGrid Platformと呼ばれています。インメモリDataGridとは参考記事によると以下のことが実現できるものを指すらしいです。参考記事は本記事の最後に載せています。
- インメモリなデータストアである
- 複数サーバー間でデータを共有し協調動作が可能
- 分散実行が可能
それぞれの項目に対してJDGではどのようになっているかを紹介します。
インメモリなデータストアである
JDGのデータはすべてオンメモリとなっています。 そのため、swap等が発生しない限りは高速にデータへアクセスできます。
複数サーバー間でデータを共有し協調動作が可能
JDGでは複数サーバーでクラスタを組み分散してデータを保持できます。1つのデータを何台のサーバーで保持するかを設定でき、1台のサーバーで障害が発生したとしてもデータが失われない仕組みとなっています。また、クラスタにノードが追加・削除された場合はそのノードが保持していたデータを各サーバーに自動でリバランスする機能を備えています。
分散実行が可能
JDGではクラスタの中でアプリケーションを動かすことができます。JDGのデータを利用するようなアプリケーションの場合、データを持っている該当のノードでJavaの特定の処理を行うことができます。これによりデータのアクセスが高速になり、高速なスループットを実現することが可能となっています。また、クラスタ内でMapReduceを行うことができ集計のような処理も高速に行うことが可能です。
Server-Client modeとEmbedded mode
JDGには以下の2つのモードがあります。
- Server-Client mode
- Embedded mode
Server-Client mode
Server-Client modeはアプリケーションとJDGを別に動作させて、HTTPなど任意のプロトコルを利用してJDGにアクセスします。 Server-Client modeを利用することでアプリケーションとデータを分離して管理できます。
Embedded mode
Embedded modeはJavaアプリケーションとJDGを同一のJVMで動かします。これにより上記で示したような任意のJavaアプリケーションを分散して動作させることが可能となります。これによりデータ処理を高速化しスループットの高速化を実現できます。
私達のサービスでは高速なスループットが求められるためEmbedded modeを利用しています。例えば膨大な商品データの中から商品の値段が下がったことをリアルタイムで検知しユーザーにお知らせをするということをしています。
しかし、Embedded modeはアプリケーションとデータが同一のJVM上に乗っているのでアプリケーション等の障害でJVMが停止するとデータも失われてしまいます。 また、JVMの再起動つまりアプリケーションの再起動をするとデータが失われるためデプロイのたびにデータを各サーバーでリバランスして回る必要があります。
JDGとInfinispan
JDGはOSSで開発されているInfinispanというアプリケーションのエンタープライズ版となっています。 そのため基本的にはInfinispanのソースコードを読むことでアプリケーションの中身を直接把握することが可能です。
JDGクラスタの仕組み
JDGでは複数のサーバーでクラスタを組み分散してデータを保持していると紹介しました。 サーバー同士のクラスタ管理はJGroupsというOSSライブラリを使用しています。 JGroupsではクラスタ管理に必要な仕組みを、それぞれのプロトコルとして分けて管理をします。
プロトコルは以下のようなXMLで設定を記述します。以下は実際に私達のシステムで使われている設定ファイルを少しいじったものです。
<config xmlns="urn:org:jgroups" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups-4.0.xsd"> <TCP bind_addr="${jgroups.bind_addr:SITE_LOCAL}" bind_port="${jgroups.tcp.port:7800}" port_range="30" recv_buf_size="10m" send_buf_size="640k" enable_diagnostics="false" sock_conn_timeout="2000" thread_naming_pattern="pl" bundler_type="no-bundler" thread_pool.min_threads="50" thread_pool.max_threads="10000" thread_pool.keep_alive_time="60000" /> <org.jgroups.aws.s3.NATIVE_S3_PING region_name="ap-northeast-1" bucket_name="${jgroups.s3.bucket}" /> <FD_SOCK/> <FD timeout="60000" max_tries="10"/> <VERIFY_SUSPECT timeout="3000"/> <pbcast.NAKACK2 use_mcast_xmit="false" xmit_interval="1000" xmit_table_num_rows="100" xmit_table_msgs_per_row="1000" xmit_table_max_compaction_time="10000"/> <UNICAST3 xmit_interval="500" xmit_table_num_rows="20" xmit_table_msgs_per_row="1000" xmit_table_max_compaction_time="10000"/> <pbcast.STABLE stability_delay="500" desired_avg_gossip="5000" max_bytes="1m"/> <pbcast.GMS print_local_addr="true" join_timeout="3000" max_join_attempts="400"/> <MFC max_credits="2m" min_threshold="0.50"/> <FRAG3 frag_size="8000"/> </config>
各プロトコルの役割についての概要はこちらのブログにすごくわかりやすくまとめられているのでご参照ください。
https://kazuhira-r.hatenablog.com/entry/20130209/1360426003
ここでは、特に重要なディスカバリープロトコル、グループメンバーシッププロトコル、障害検知プロトコルについて紹介します。
ディスカバリープロトコル
ディスカバリープロトコルは、JGroupsのクラスタへの参加時に他ノードやコーディネータを探すときに使われるプロトコルです。
私達のシステムでは、各ノードにEC2を利用しているため NATIVE_S3_PING というプロトコルを利用しています。
NATIVE_S3_PING
NATIVE_S3_PING はS3上のファイルを利用することでディスカバリープロトコルの実現を行います。
S3を使ったディスカバリープロトコルはもともと公式で開発されている S3_PING というプロトコルがあります。しかし、最新のバージョンでは S3_PING が非推奨となっており NATIVE_S3_PING を使うように勧めています。そのような経緯から私達のプロジェクトではサードパーティ製のNATIVE_S3_PINGを利用しています。
https://github.com/belaban/JGroups/blob/master/src/org/jgroups/protocols/S3_PING.java#L30
NATIVE_S3_PINGを利用しクラスタを作成すると、指定したS3バケットに以下のようなファイルが生成されます。
AP-1-24102 4f8adfd5-4c86-55ce-cfe3-4fb11dfa145a 10.160.4.1:7800 T AP-2-31780 8db77c66-79fd-93f5-d72f-b718438a6061 10.160.4.2:7800 F AP-3-42443 532qfd3d-543d-fda3-l3rf-ljl35dfahlh5 10.160.4.3:7800 F AP-4-53254 0401172a-201e-a875-dac3-04b74a9f8812 10.160.4.4:7800 F
クラスタはコーディネータノード(マスタノード)1台とそれ以外のノードで構成されます。クラスタにノードが参加・退出するとコーディネータノードが上記ファイルを編集します。 上記ファイルでTがついているものがコーディネータノードです。参加したいノードは上記のファイルを参照しコーディネータノードに対して「参加させてくれ」といったメッセージを送ります。
実際にコーディネータノードがクラスタにノードを追加するのは以下のグループメンバーシッププロトコルで行います。クラスタがない初期状態の場合、最初のノードはS3にファイルがないと判断し自身がコーディネータノードとなりS3にファイルを作成します。
グループメンバーシッププロトコル
グループメンバーシッププロトコルは、クラスタのメンバー管理を行うプロトコルです。各ノードのクラスタへの参加や退出を管理します。グループメンバーシッププロトコルには特に種類がなく GMS として設定されるもののみとなっています。
障害検知プロトコル
障害検知プロトコルはその名前の通り、クラスタ内のノードに障害が発生した場合にそれを検知するためのプロトコルです。 私達のシステムではFD_SOCKとFDというプロトコルを組み合わせて利用しています。また、VERIFY_SUSPECTというプロトコルも障害検知に必要なプロトコルとなります。
FD
まず、FDではクラスタ内で円形になるように以下のように隣接グラフを作成します。
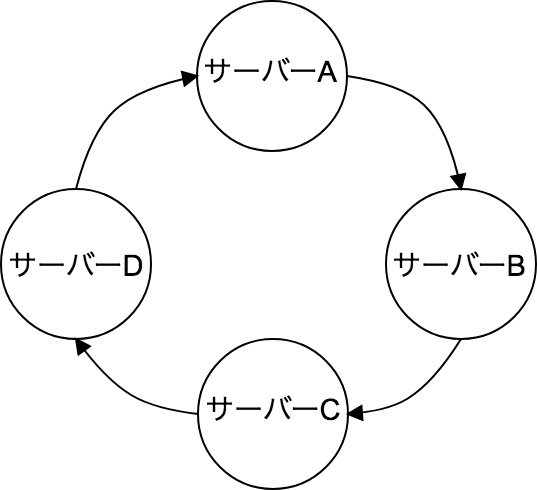
そして隣のノードで障害が発生していないかどうかを監視します。FDでは定期的に隣のノードに対してハートビートを行います。定めた「リトライ回数xタイムアウト時間」の間、隣のノードから応答がなかった場合はそのノードが死んでいるかもしれないと判断します。リトライ回数とタイムアウト時間はXMLの設定の max_tries と timeout で設定できます。
<FD timeout="60000" max_tries="20"/>
隣のノード死んでいるかもしれないと判断すると、それをマスタノードに通知します。この死んでいるかもしれないと疑うことを「SUSPECT」といいます。
FD_SOCK
FD_SOCKでもFDと同じように円形の隣接グラフを作成します。FD_SOCKでは隣のノードの障害検知にはTCPコネクションを利用します。そしてTCPコネクションが切られた場合隣のノードが死んだと判断し「SUSPECT」を行います。
VERIFY_SUSPECT
VERIFY_SUSPECTはSUSPECTされた状態のノードが本当に死んでいるのかを確認するプロトコルです。 VERIFY_SUSPECTはコーディネータノードによって行われ、SUSPECTされたノードにpingし生きているかを確認します。生きていた場合はSUSPECTされたノードのSUSPECTフラグを消します。死んでいた場合はクラスタから対象のノードを削除します。
SplitBrainの発生
以上のようにプロトコルを組み合わせることでJDGはクラスタを実現しています。しかし、設定が甘かったりするとSplitBrainを起こすことがあります。 今回実際にSplitBrainが発生し調査対応を行ったので紹介します。
SplitBrain
冒頭でも説明しましたがSplitBrainとは、1つのクラスタが2つ以上のクラスタに分断することをいいます。 冒頭ではクラスタのノード間で通信が分断された場合などに、ノード同士で通信できなくなりSplitBrainが発生すると紹介しました。 しかし今回の場合は通信障害が原因ではありませんでした。以下で今回SplitBrainが発生した原因・その流れを紹介します。
SplitBrain発生までの流れ
今回の根本的な原因はGCに起因するstop the world発生が原因でした。 以下のような4台のサーバーによるクラスタ(実際のサーバー台数とは異なります)について考えます。 障害検知プロトコルでは以下のようにノード同士を監視していると仮定した、SplitBrain発生までの流れです。
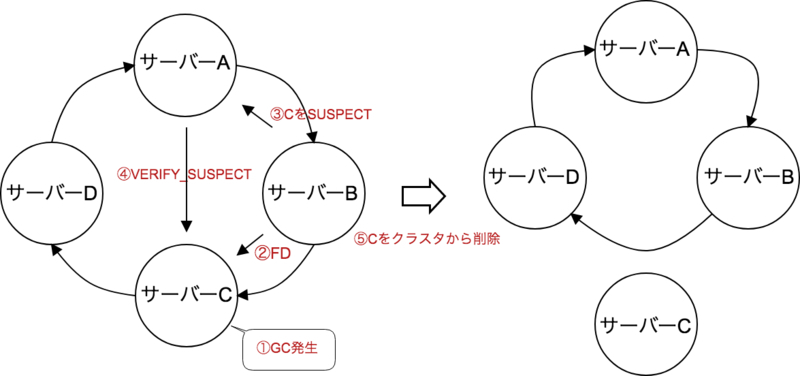
- CノードでGCによる10分以上のstop the worldが発生
- BノードがFDプロトコルでCノードが生きているかを確認する
- CノードはGCによるstop the worldが発生しているためFDに対するレスポンスができない
- BノードはCノードが死んでいると判断しマスタノードAに通知
- マスタノードAはVERIFY_SUSPECTプロトコルによってCノードが実際に死んでいるのか確認
- CノードはGCによるstop the worldが発生しているためVERIFY_SUSPECTに対するレスポンスができない
- マスタノードAはCノードが死んだと判断しCノードをクラスタから外す
- CノードのGCが終了
- Cノードはクラスタから外されているとは気づかない
- Cノードは他のノードに通信ができないため死んだと判断し自分がマスタノードになる
以上のような流れでマスタノードが2つ出来上がり、クラスタが2つに分断しました。
SplitBrainの再現
本当にGCに起因するstop the world発生によるFD発生が原因でSplitBrainが発生したかについてはあくまでも予測でした。そこで今回FullGCを発生させ、FDが発生することによってSplitBrainが起こるかを再現しました。
以下が検証の手順です。
- FDのタイムアウト時間を短くした設定
- デバッグモードでアプリケーションを起動
- JDGのキャッシュに対して大量のデータをinsert
- JConsoleを利用してFullGCを発生させる
- 実際にSplitBrainが発生したか確認
FDのタイムアウト時間を短く設定
検証で10分以上のFullGCを発生させるのは難しかったので、以下のようにFDのタイムアウトを短くしました。これにより1分くらいのFullGCが発生するとFDのタイムアウトが発生すると考えられます。
<FD timeout="6000" max_tries="10"/>
デバッグモードでアプリケーションを起動
FDが発生したログはデバッグモードでしかログが吐き出されません。そのため実際にFDが発生しているのかもつかめていない状態でした。そこで検証ではFDが本当に発生するかどうかを確認するためにデバッグモードでアプリケーションを起動します。
JDGのキャッシュに対して大量のデータをinsert
一定期間のFullGCを走らせるために大量のオブジェクトを生成させる必要がありました。JDGのキャッシュは実際にはJavaのオブジェクトなので、ダミーデータをJDGに大量にinsertしました。
JConsoleを利用してFullGCを発生させる
次にFullGCを発生させます。FullGCが発生するまで待つということをしていると日が暮れてしまいます。そこでJConsoleというツールを利用しFullGCを発生させました。以下のように「GCの実行」というボタンを押すとFullGCが走ります。
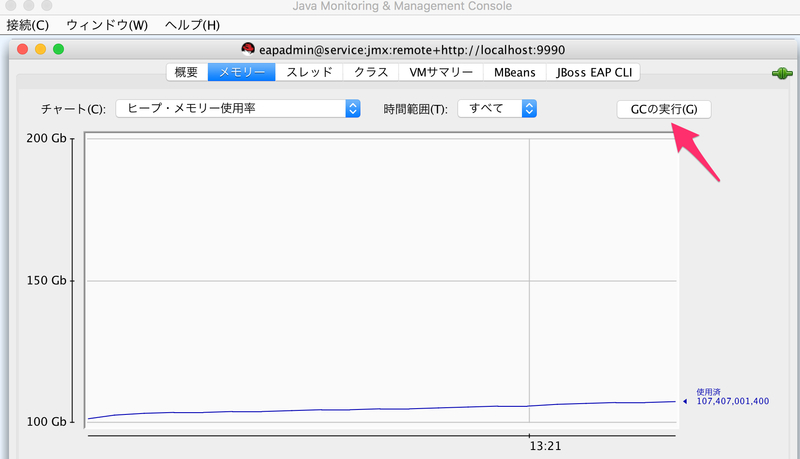
実際にSplitBrain・FDが発生したか確認
最後にFDのタイムアウトが実際に発生しSplitBrainが発生したかを確認します。 以下のようにS3に2つのファイルが作られたことからSplitBrainが発生していることが確認できました。各ノード名は「SplitBrain発生までの流れ」で説明したノードに対して、「A=AP-1, B=AP-2, C=AP-3, D=AP-4」のように対応しています。
クラスタ1
AP-1-24102 4f8adfd5-4c86-55ce-cfe3-4fb11dfa145a 10.160.4.1:7800 T AP-2-31780 8db77c66-79fd-93f5-d72f-b718438a6061 10.160.4.2:7800 F AP-4-53254 0401172a-201e-a875-dac3-04b74a9f8812 10.160.4.4:7800 F
クラスタ2
AP-3-42443 532qfd3d-543d-fda3-l3rf-ljl35dfahlh5 10.160.4.3:7800 F
また、以下のログからFDが発生していることが確認できました。
AP-2によるFDのログ
また、以下のログからFDのタイムアウトが発生していることが確認できました。
2019-04-10 16:27:27.625 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=1) 2019-04-10 16:27:33.625 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=2) 2019-04-10 16:27:39.626 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=3) 2019-04-10 16:27:45.628 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=4) 2019-04-10 16:27:51.629 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=5) 2019-04-10 16:27:57.630 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=6) 2019-04-10 16:28:03.632 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=7) 2019-04-10 16:28:09.633 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=8) 2019-04-10 16:28:15.634 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: heartbeat missing from AP-3-42556 (number=9) 2019-04-10 16:28:21.636 DEBUG [org.jgroups.protocols.FD] (Timer runner-1,AP-2-31780) AP-2-31780: received no heartbeat from AP-3-42556 for 10 times (60000 milliseconds), suspecting it 2019-04-10 16:28:21.638 DEBUG [org.jgroups.protocols.FD] (jgroups-50,AP-2-31780) AP-2-31780: suspecting [AP-3-42556]
コーディネータノードによるVERIFY_SUSPECTのログ
最後にVERIFY_SUSPECTによりノードCがクラスタから削除対象となっていることを確認しました。
2019-04-10 16:28:24.753 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (VERIFY_SUSPECT.TimerThread-55,AP-2-31780) ISPN000094: Received new cluster view for channel framework: [AP-2-31780|10] (1) [AP-2-31780] 2019-04-10 16:28:24.753 INFO [org.infinispan.CLUSTER] (VERIFY_SUSPECT.TimerThread-55,AP-2-31780) ISPN100001: Node AP-3-42556 left the cluster
以上のようにFullGCの発生により実際にFDのタイムアウトによるSplitBrainが発生していることが確認できました。これにより今回のSplitBrainの根本原因がGCによるstop the worldであると判断できました。
対策
今回SplitBrainが発生するまで異常に気づかなかった原因の一番の問題は監視にありました。 システムの監視はもともとしっかりと行われていたのですが、私達が使い慣れているようなものではなくメトリクス等が簡単に参照できるようになっていませんでした。 そこで、Datadogを導入しメトリクスを可視化、それを元にした監視設定を行いました。 それ以来なにか異常が発生した場合すぐに対応し、システムを見直すというサイクルが生まれました。
また、JVMのパラメータ見直しやJVMの定期的な再起動を行い長時間のGCが起こりにくくなるように対策を行っています。 こちらについては実際に効果があるか長期的に検証を行っています。
本システムの課題
- キャッシュとアプリケーションが一緒に載っていてる
- JDGの情報があまりない
キャッシュとアプリケーションが一緒に載っている
JDGの説明の中でも説明しましたが、私達のシステムではEmbedded modeを利用しています。そのためキャッシュとアプリケーションが同じJVM上で動いています。JDGは大量のキャッシュデータをJavaオブジェクトとして保持するため長時間のGCが発生することもあります。今回の10分以上のGCも大量データのGCが要因と考えています。これは、JDGキャッシュだけではなくJDGクラスタ上のアプリケーションにも影響を与えてしまいます。
また、アプリケーションのデプロイ時には毎度1台1台キャッシュをリバランスしながら行っています。その結果デプロイに時間がかかってしまうという問題があります。これは時間だけではなくデータのロストの危険性もあります。そこでこの問題を解決するためにキャッシュの切り離しや別サービスの利用等を検討しています。しかし、スループットの問題がありなかなか難航しています。
JDGの情報があまりない
JDGの情報を調べていると情報が少ないか、あっても古い情報が多いとわかりました。今回の調査でも公式ドキュメントを参照する方法以外の情報がほとんどありませんでした。そして公式ドキュメントに書かれていないものについての詳細はソースコードを読む以外方法がありませんでした。これも相まって別サービスの利用を検討しています。
まとめ
今回JDGという分散キャッシュサーバーのSplitBrainの発生から、その調査と再現・対策を行いました。 そして、その過程で得た知見についてご紹介しました。
弊社では未知の領域であっても一歩ずつ調査を行い問題解決ができるエンジニアを募集しております。興味がある方は以下のリンクからぜひご応募ください。
また分散システム・リアルタイム分析システムに興味がある、こんな仕組みじゃなくてもっとこうするべきでしょとのお考えがある方はぜひお話しましょう!