



こんにちは、基幹システム部USEDチームの柳瀬です。現在は主にZOZOUSEDで取り扱う商品の価格算出に関するシステムの開発・運用を中心に担当しています。
先日、とある案件でAmazon Aurora上のPostgreSQLに新規でのテーブル作成を伴う機能を開発する機会がありました。そのテーブルは3億件ほどのレコードを格納し、高頻度の参照および日次でのデータ追加が行われるものでした。
大量データを扱ううえでクリアすべき点として「処理速度など性能面での問題が発生しない事」があります。実装にあたってこの問題をクリアするために工夫した際に、パーティションテーブルを活用する事で解決する事ができましたので、その時の経験談をお伝えしたいと思います。
なお、今回の記事ではPostgreSQLを対象に説明しております。パーティションテーブルが実装されている他のRDBMSに関してもある程度は参考にできるかと思いますので、ご自身で担当されておりますシステムのDBに置き換えて読み進めていただければと思います。
そもそもなぜPostgreSQLを採用したのか
今回紹介する機能で使っているデータベース(以下DB)ですが、リリース当初はAWS上のMariaDBで稼働していました。しかしながら、その直後の追加改修においてwindow関数を使用したい場面が出てきました。
当時AWSで利用可能だったMariaDBのバージョン(10.2)においてwindow関数の動作を確認したところ、こちらが期待した通りの動作をせず、実用に耐えうるものでない事が判明しました。
window関数を使用しない方法で実装しようと思えばそれ自体は可能です。ただ今回は処理が複雑化して工数が大幅に増加する事が予見できたため、分析・集計系の処理に強いとされるPostgreSQLへ切り替えた方が速いという判断になりました。
やろうとした事
そもそも今回のテーブルは、別のチームが別のDBで運用していたものを巻き取る形で追加する事になったテーブルでした。そこで、移行するにあたって現状を確認したところ、データが増えすぎたせいでインデックスの追加が1日で終わらなくなっていた事が判明しました。
今回のテーブルでも同じような事が起こったら、移行する意味がありません。上位のインスタンスに置き換えてDBの性能を上げる事は費用の関係で難しかったため、テーブルの構成を工夫する必要に迫られました。
そこで採用したのがパーティションテーブルです。
外からは1つの大きなテーブルに見えているのですが、実際にはより小さなテーブルにデータが分けて入れられています。そのためアプリケーション側から見た場合、テーブルが分けられている事を意識させないような構造になっていると言えます。
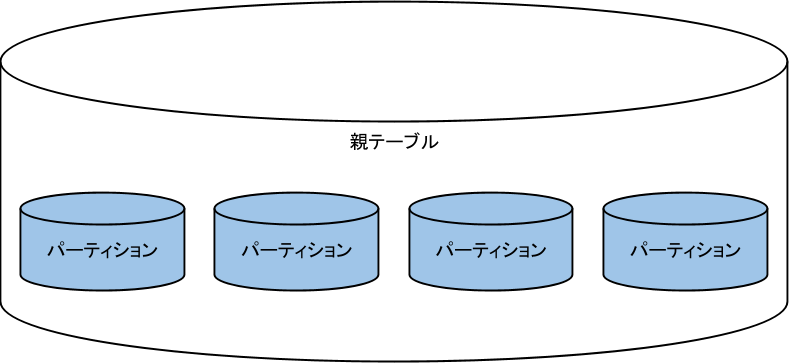
利点としてあげられるのは処理の高速化です。
通常の検索・更新処理については参照する物理領域を減らせる事で速くなる場合があります。またバッチ処理で大量にデータを追加・削除する場合も、パーティション自体を操作すれば時間をかけずに実施する事が可能です。
パーティションテーブルの作り方
それでは作ってみましょう。まずは「親テーブル」を以下のSQLで作成します。
CREATE TABLE sample_table ( id serial, partition_column int, -- 中略 ) PARTITION BY RANGE (partition_column);
カラム定義の括弧を閉じるところまでは普通のテーブルを作るのと同じで、括弧を閉じた後にPARTITION BYでパーティションの種類と対象の列を指定するのが普通のテーブルと異なるところです。
指定の仕方には範囲パーティション、リストパーティション、ハッシュパーティション(PostgreSQL 11以降)の3通りの指定方法がありますが、今回は範囲パーティションで説明を進めます。
次に、親テーブルに紐づけるパーティション(以下「子テーブル」)を以下のSQLで作成します。
CREATE TABLE sample_table_partition_1 PARTITION OF sample_table FOR VALUES FROM (0) TO (1000000);
テーブル名のすぐ後にPARTITION OFで親テーブルを指定し、FOR VALUESで分割する値の範囲を指定します。この指定の仕方でセットされる値は 0 <= partition_column < 999999 になります。TOで指定した値より1小さくなる事に留意してください。
ちなみにパーティションに対するインデックスの設定ですが、自力で全ての子テーブルに作成しています。これは検証時のAurora PostgreSQL最新バージョン(10)にて親テーブルへインデックスが追加できなかったためです。
なお、PostgreSQL 11からは親テーブルへの指定で自動的に全ての子テーブルに反映させる事ができるようになっております。AuroraでもPostgreSQL 11が利用可能です。
この辺りは機会があれば改めて検証してみたいと思います。
インデックス作成時間の比較
上記のような手順で3億件のデータを10分割したパーティションテーブルに対し、PARTITION BYで指定したカラムに対するインデックスを作成してそれにかかった時間を計測してみました。
また、比較のため全く同一のデータが入った単一のテーブルを用意し、そのテーブルに対しても同様のインデックスを作成して比較してみました。
以下がその結果です。
- 単一テーブル:396.819秒
- 10分割パーティション:39.729秒(1パーティションあたり)
パーティションテーブルの場合、単一のテーブルと比較して1/10の時間で作成できている事がわかります。物理テーブル1個あたりのデータ量が単一テーブルと比較して1/10になっていますのでほぼ想定通りです。
また、各パーティションのインデックスは並列で作成・再構築する事が可能なため、並列処理する事で単一テーブルに対するインデックス作成よりも短時間で作業を完了する事ができました。
また、作成したインデックスのサイズは、1パーティションあたりのサイズが単一テーブルのインデックスと比較して1/10になっていました。サイズが小さいほどINSERTや再構築にかかる時間も短縮されますので、より高速に動作する事が期待でき、単一のテーブルで作成するよりも運用面での負担が少ないと言えます。
実際にリリースしてから今日まで、大きなトラブルは発生しておりません。また、特定の条件でSELECTした場合も高速になるようですが、こちらも今後改めて検証したいと思います。
まとめ
今回得られた知見は他のテーブルやDBでも応用が可能です。特に今後は大量データを活用する場面がさらに増えると想定されますので、それに呼応して活用の場面が増えるものと考えられます。
ZOZOテクノロジーズでは、共にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は以下のページをご確認ください!