



はじめに
こんにちは。WEARバックエンド部SREブロックの春日です。普段はWEARというサービスのSREとして開発・運用に携わっています。本記事では、約60%のコスト削減に成功したNATゲートウェイの通信内容の調査方法と通信量の削減方法についてご紹介します。
目次
背景
ZOZOではより効果的な成長を目指してコストの最適化を進めています。コストの増大はサービスの拡大を鈍化させる原因となるため、常に最適な状態に保つことが必要です。WEARでも不要なコストを可能な限り削減し適正化すべく、コスト把握と対応を続けています。
コストの把握
まずはコストを把握します。AWSのコストはAWS Cost Explorer(以下、Cost Explorer)で確認できます。WEARでは『Elastic Container Service for Kubernetes』『S3』『CloudFront』に次いで『EC2その他』に料金がかかっていました。『EC2その他』の料金がそこまで高いことは想定外だったため、『EC2その他』の内訳を確認します。フィルターのサービスを『EC2 - Other』、グループ化の条件のディメンションを『APIオペレーション』とすることで、API単位で料金を確認できます。結果は以下のグラフの通りです1。
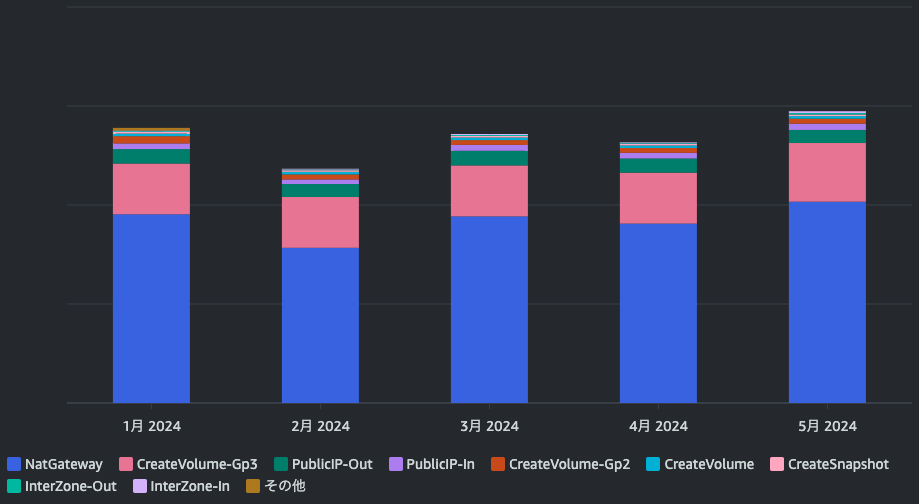
内訳を確認すると、コストの3分の2ほどがNATゲートウェイのコストでした。さらに詳細に内容を確認します。先ほどまでのレポートパラメータを解除し、フィルターの『APIオペレーション』を『NatGateway』、グループ化の条件のディメンションを『使用タイプ』にします。
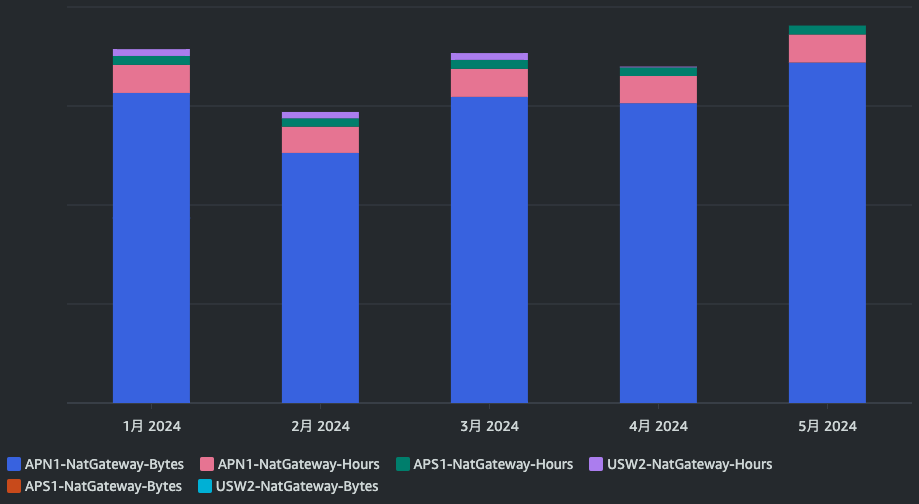
NATゲートウェイの料金に関するドキュメントを確認すると、『NATゲートウェイあたりの料金(USD/時)』と『処理データ1GBあたりの料金 (USD)』で構成されています。グラフを見ると、NATゲートウェイの起動時間による料金よりも、NATゲートウェイのデータ処理に関する料金が圧倒的に高いことがわかります。つまり、NATゲートウェイを経由して大量の通信が行われているということが読み取れます。
次章では、NATゲートウェイを経由する通信を詳しく調査します。
NATゲートウェイの通信内容の把握
CloudWatchメトリクスでの確認
まずはAmazon CloudWatch(以下、CloudWatch)でNATゲートウェイのCloudWatchメトリクスを確認します。メトリクスの詳細は公式ドキュメントに記載があります。
WEARでは、BytesOutToDestinationがBytesInFromDestinationの2倍ほどの量でした。これは、NATゲートウェイを経由した外向きの通信量が、NATゲートウェイを経由した内向きの通信量の2倍あることを示します。
VPCフローログでの確認
次に、VPCフローログを用いて、より詳細な通信内容を確認します。VPCフローログにはVPC内部のネットワークインターフェイス間の通信内容が記録されています。Amazon S3(以下、S3)バケットに出力されたVPCフローログをAmazon Athena(以下、Athena)でクエリして通信内容を確認します2。
VPCフローログのAthenaテーブルは以下の内容で作成したことを前提に説明します。
VPCフローログテーブル作成クエリ
CREATE EXTERNAL TABLE `vpc_flow_logs_table`( `version` int COMMENT '', `account_id` string COMMENT '', `interface_id` string COMMENT '', `srcaddr` string COMMENT '', `dstaddr` string COMMENT '', `srcport` int COMMENT '', `dstport` int COMMENT '', `protocol` bigint COMMENT '', `packets` bigint COMMENT '', `bytes` bigint COMMENT '', `start` bigint COMMENT '', `end` bigint COMMENT '', `action` string COMMENT '', `log_status` string COMMENT '', `vpc_id` string COMMENT '', `subnet_id` string COMMENT '', `instance_id` string COMMENT '', `tcp_flags` int COMMENT '', `type` string COMMENT '', `pkt_srcaddr` string COMMENT '', `pkt_dstaddr` string COMMENT '', `region` string COMMENT '', `az_id` string COMMENT '', `sublocation_type` string COMMENT '', `sublocation_id` string COMMENT '', `pkt_src_aws_service` string COMMENT '', `pkt_dst_aws_service` string COMMENT '', `flow_direction` string COMMENT '', `traffic_path` int COMMENT '') PARTITIONED BY ( `logdate` string COMMENT '') ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '$LOCATION_OF_LOGS' TBLPROPERTIES ( 'projection.enabled'='true', 'projection.logdate.format'='yyyy/MM/dd/HH', 'projection.logdate.interval'='1', 'projection.logdate.interval.unit'='HOURS', 'projection.logdate.range'='2022/01/01/00,NOW', 'projection.logdate.type'='date', 'skip.header.line.count'='1', 'storage.location.template'='$LOCATION_OF_LOGS/${logdate}', 'typeOfData'='file')
$LOCATION_OF_LOGSはVPCフローログの出力先S3パスに読み替えてください。
WEARではAthenaテーブルの作成をTerraformのaws_glue_catalog_tableで行っています。上記のクエリはaws_glue_catalog_tableから作成されたテーブルをSHOW CREATE TABLEで出力したクエリのため、公式ドキュメントとは表現が一部異なっています。
次のようなクエリ3でVPC内部からNATゲートウェイを経由した外向きの通信を確認します。SQL内にコメントしてある箇所は適宜自分の環境に読み替えてください。
SELECT pkt_dst_aws_service, SUM(bytes) AS bytesTransferred FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 調査対象の日付(UTC) GROUP BY pkt_dst_aws_service ORDER BY bytesTransferred DESC
このクエリでは、特定の日付でVPC内部からNATゲートウェイ経由で送信したトラフィック量をAWSサービス4ごとに確認しています。この例では1日で調査していますが、Athenaはスキャンしたデータ量に料金が比例します5。サービスの規模によってはまず時間単位でクエリし、スキャン量が許容できることを確認してください。
結果の例を以下の表に記載します。pkt_dst_aws_serviceが-である箇所はAWSが管理していないIPに向けた通信です。表の数値はWEARの実際の値ではなくダミーデータです。今後出てくるAthenaのクエリ結果はすべて実際の値ではなく、ダミーデータを記載します。
| pkt_dst_aws_service | bytesTransferred |
|---|---|
| AMAZON | 106000 |
| EC2 | 4500 |
| - | 2000 |
| DYNAMODB | 1000 |
| CLOUDFRONT | 3 |
| GLOBALACCELERATOR | 1 |
続いて、NATゲートウェイを経由してVPC内部で受信するトラフィックも確認します。
SELECT pkt_src_aws_service, SUM(bytes) AS bytesTransferred FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr NOT LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 調査対象の日付(UTC) GROUP BY pkt_src_aws_service ORDER BY bytesTransferred DESC
| pkt_src_aws_service | bytesTransferred |
|---|---|
| EC2 | 21000 |
| AMAZON | 6000 |
| - | 5000 |
| CLOUDFRONT | 1500 |
| DYNAMODB | 1000 |
| GLOBALACCELERATOR | 1 |
この時点でAmazon DynamoDB(以下、DynamoDB)のゲートウェイエンドポイントが不足しており、NATゲートウェイを経由して通信してしまっていることが読み取れます。Datadogのように、IPアドレス範囲を公開しているサービスを利用している場合、VPCフローログのpkt_dstaddr(送信先IPアドレス)だけで把握も可能です6。しかし、VPCフローログのみではAMAZONの内訳など、具体的にどのエンドポイントに向けて通信しているかがわかりません。これらを把握するため、VPC内部の名前解決の際のクエリログを活用してより詳細に調査します。
リゾルバーでのクエリログでの確認
リゾルバーでのクエリのログ記録を設定すると、VPC内部で行われた名前解決のクエリログをS3に保存できます。VPCフローログで確認できる送信先のIPアドレスとクエリログの名前解決の結果を突き合わせることで、NATゲートウェイを経由して行われた通信先のドメインが把握できます。ドキュメントに従ってクエリログのAthenaテーブルを作成します。
リゾルバーのクエリログのAthenaテーブルは以下の内容で作成したことを前提に説明します。
リゾルバーのクエリログテーブル作成クエリ
CREATE EXTERNAL TABLE `vpc_dns_query_logs_table`( `version` string COMMENT '', `account_id` string COMMENT '', `region` string COMMENT '', `vpc_id` string COMMENT '', `query_timestamp` string COMMENT '', `query_name` string COMMENT '', `query_type` string COMMENT '', `query_class` string COMMENT '', `rcode` string COMMENT '', `answers` array<struct<rdata:string,type:string,class:string>> COMMENT '', `srcaddr` string COMMENT '', `srcport` int COMMENT '', `transport` string COMMENT '', `srcids` struct<instance:string,resolver_endpoint:string> COMMENT '', `firewall_rule_action` string COMMENT '', `firewall_rule_group_id` string COMMENT '', `firewall_domain_list_id` string COMMENT '') PARTITIONED BY ( `logdate` string COMMENT '') ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '$LOCATION_OF_LOGS' TBLPROPERTIES ( 'projection.enabled'='true', 'projection.logdate.format'='yyyy/MM/dd', 'projection.logdate.interval'='1', 'projection.logdate.interval.unit'='DAYS', 'projection.logdate.range'='2022/01/01,NOW', 'projection.logdate.type'='date', 'storage.location.template'='$LOCATION_OF_LOGS/$VPC_ID/${logdate}', 'typeOfData'='file')
$LOCATION_OF_LOGSはリゾルバのクエリログの出力先S3パス、$VPC_IDはログを記録しているVPCのIDに読み替えてください。
VPCフローログテーブルと同様にAthenaテーブルの作成をTerraformで行っており、上記はSHOW CREATE TABLEで出力したクエリです。そのため、公式ドキュメントとは表現が一部異なっています。
次のようなクエリでVPCフローログとリゾルバーのクエリログを突き合わせます。
SELECT R.query_name, SUM(F.bytesTransferred) AS bytes_day, ROUND(SUM(F.bytesTransferred) * 30.0 / (1000 * 1000 * 1000), 2) AS GB_months FROM ( SELECT pkt_dstaddr, SUM(bytes) AS bytesTransferred FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 調査対象の日付(UTC) AND pkt_dst_aws_service = 'AMAZON' GROUP BY pkt_dstaddr ) F LEFT JOIN ( SELECT DISTINCT query_name, answer.rdata FROM "vpc_dns_query_logs_database"."vpc_dns_query_logs_table" -- リゾルバーのクエリログテーブルが存在するデータベース.リゾルバーのクエリログテーブル CROSS JOIN UNNEST(answers) as st(answer) WHERE answer.type = 'A' AND logdate = 'YYYY/MM/dd' -- 調査対象の日付(UTC) ) R ON F.pkt_dstaddr = R.rdata GROUP BY R.query_name ORDER BY bytes_day DESC
このクエリでは、大きく分けて3つのことを行っています。
- VPCフローログテーブルからNATゲートウェイを経由するトラフィックの送信先IPアドレスを取得(クエリの
F部分) - リゾルバーのクエリログテーブルからドメインとIPアドレスの対応表を作成(クエリの
R部分) - 1と2をIPアドレスで結合し、送信先ドメインごとのトラフィック量を取得
クエリの結果を確認すると、firehose.ap-northeast-1.amazonaws.com.とsqs.ap-northeast-1.amazonaws.com.に対するトラフィック量が多いことを確認できました。WEARでは、アプリケーションのログをaws-for-fluent-bitを用いてAmazon Data Firehose(以下、Firehose)に送信しています。このサービスに対する送信がほとんどであり、インターフェイスVPCエンドポイントが不足していることに気付けました。Amazon Simple Queue Service(以下、SQS)も同様に、VPCエンドポイントが不足していることが判明しました。
他の箇所についても同様に調査すべく、pkt_dst_aws_service = 'EC2'などに変更しながらトラフィック量を確認していきます7。
その結果、以下のドメインに対しての通信量が多いことを確認できました。d5l0dvt14r5h8.cloudfront.net.に見覚えはありませんでしたが、AWSサポートに確認したところ、Amazon ECR パブリックリポジトリ(以下、ECRパブリックリポジトリ)であることが判明しました(2024年7月現在)。
*.datadoghq.com- WEARのAPI
d5l0dvt14r5h8.cloudfront.net.
これで通信内容が判明しました。NATゲートウェイ経由で大量に通信しており、削減効果が見込めそうな宛先は以下の通りです。
- AWSサービス
- Datadog
- WEARのAPI
- ECRパブリックリポジトリ
次章からはこの結果を元に、可能な限りNATゲートウェイを経由せずに済むように対応します。
調査結果をもとにNATゲートウェイ経由での通信量を削減する
AWSサービスとの通信
AWSサービスをNATゲートウェイ経由で通信させないためには、VPCエンドポイントが必要です。ただし、通信するすべてのAWSサービスに対してVPCエンドポイントを用意すればいいとは限りません。VPCエンドポイントにも起動時間による料金と、データ処理による料金が発生するためです。インターフェイスエンドポイントの料金を確認し、NATゲートウェイで通信する場合の料金との損益分岐点を確認します。
NATゲートウェイはすでに存在し、外部への通信に利用しています。NATゲートウェイは削除できないため、NATゲートウェイの起動時間に関するコストは考慮しないことにします。また、インターフェイスエンドポイントはAZごとに起動時間の料金がかかります。WEARでは3AZを利用しているため、3つとして計算します。
ap-northeast-1リージョンの料金は以下のようになっています(2024年7月現在)。
NATゲートウェイの料金表
| NAT ゲートウェイあたりの料金 (USD/時) | 処理データ 1 GB あたりの料金 (USD) |
|---|---|
| USD 0.062 | USD 0.062 |
インターフェイスエンドポイントの料金表
| 各 AZ の VPC エンドポイント 1 つあたりの料金 (USD/時間) |
|---|
| USD 0.014 |
| AWS リージョンで 1 か月に処理されるデータ | 処理データ 1 GB あたりの料金 (USD) |
|---|---|
| 最初の 1 PB | 0.01 USD |
| 次の 4 PB | 0.006 USD |
| 5 PB以上のもの | 0.004 USD |
1か月あたりの通信量(GB)をとし、以下の式を満たす
を計算します。VPCエンドポイントの起動時間は
24時間*30日*3AZで計算しています。また、調査時に概算した結果、1ヶ月に1PB以上は使っていないため、最初の1PBの料金で計算します。
するととなるため、月に581GB以上通信するのであればNATゲートウェイ経由よりもVPCエンドポイント経由の方が安いということが導けます。
そのため、WEARではFirehoseとSQSのインターフェイスエンドポイントを追加で作成することにしました。ゲートウェイタイプのVPCエンドポイントの場合は追加料金なしで利用できる8ため、DynamoDBのVPCエンドポイントも作成します。
Datadogとの通信
DatadogはAWS PrivateLink(以下、PrivateLink)を経由して通信する方法を提供しています9。ただし、調査の過程でWEARではこの方法は断念しました。
Datadogにはサイトという概念があります。各サイトは完全に独立しており、サイト間でデータの共有はできません。WEARではAmazon Elastic Kubernetes Service(以下、EKS)のリージョンと使用しているDatadogサイトの場所が異なっていました。その場合、『VPCピアリングを使用した他のリージョンからの接続』ですが、リージョン間の通信は、2024年7月時点で1GBあたり$0.09かかってしまいます。そのため、WEARではDatadogへの通信に関してはNATゲートウェイを経由することを許容しました。ご利用中のDatadogサイトのPrivateLinkとデータ送信元が同一リージョンにある場合はPrivateLinkを用いる方法を検討してみてください。
WEARのAPIとの通信
調査結果から、WEARのWebアプリケーションからAPIへの通信がNATゲートウェイを経由して行われていることがわかりました10。通信経路の概略は以下の図の通りです。AWS間の通信のためインターネットには出ていませんが、NATゲートウェイを経由して通信してしまっています。
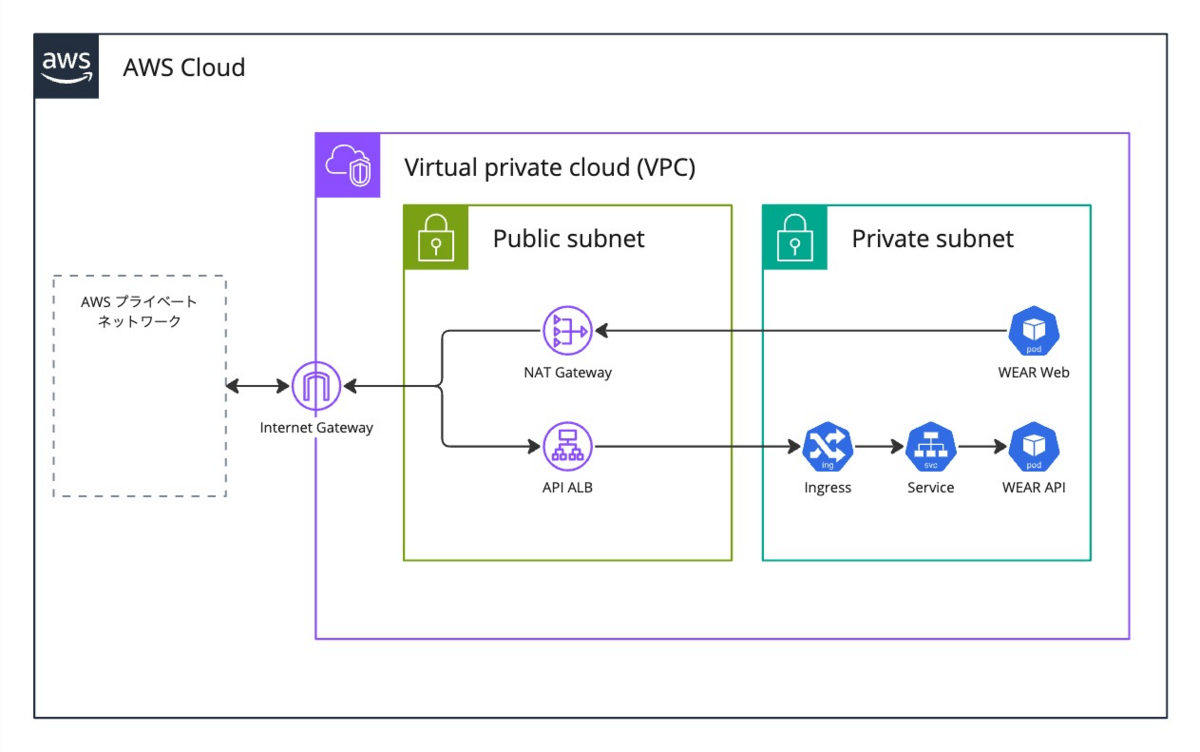
これらは同一VPCに存在しているため、VPC内部のみで通信を完結させたいところです。WEARのEKS内のPodはApplication Load Balancer(以下、ALB)の配下に存在します。調査時点ではインターネット向けのALBのみ存在しましたが内部向けのALBも作成し、VPC内部からの通信は内部向けのALBに対して行うようにします。
WEARでは、ALBとALBのエイリアスレコードの作成をAWS Load Balancer ControllerとExternalDNSを用いてIngressに専用のアノテーションを付与することで行っています。
既存のIngressを踏襲し、新たに内部向けALB用のIngressを作成します。alb.ingress.kubernetes.io/schemeアノテーションのデフォルト値はinternalですが、後述する理由により明示的にinternalを設定しておきます。
以下に内部向けALB作成のサンプルIngressを記載します。また、内部向けALBを作成するプライベートサブネットに自動検出用のタグ11が付与されていることを確認してください。
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: api-internal namespace: api annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internal external-dns.alpha.kubernetes.io/hostname: api.wear.jp # インターネット向けIngressのものと同じ # (以下略) spec: rules: - http: paths: - path: / pathType: Prefix backend: service: name: api port: number: 80
次に、作成する内部向けALBのエイリアスレコードを登録するためのプライベートホストゾーンと、プライベートホストゾーン用のExternalDNSを新たに作成します。プライベートホストゾーン名はエイリアスレコードのレコード名と一致させます。
ここで1つ注意しなければならないことがあります。すでに通信が行われているドメインに対して新たにプライベートホストゾーンを作成する場合は、エイリアスレコードを作成するまではEKSのVPCにプライベートホストゾーンを関連付けてはいけないということです。
プライベートホストゾーンを作成した時点で、関連付けされているVPC内部の通信はそのプライベートホストゾーンで名前解決を試みます。しかし、プライベートホストゾーンの作成とエイリアスレコードの作成は同時にできないため、名前解決に失敗してしまいます。プライベートホストゾーンは作成時に必ず1つ以上のVPCを関連付けなければならないため、使用していないVPCのみを一時的に関連付けておきます。
以下にTerraformを用いたサンプルコードを記載します。ここでは、使用していないデフォルトのVPCを一時的にプライベートホストゾーンに関連付けしています。
resource "aws_route53_zone" "private_api" { name = "api.wear.jp" vpc { # 一時的にdefault VPCを指定。 vpc_id = data.aws_vpc.default.id vpc_region = "ap-northeast-1" } force_destroy = false } # 一時的にdefault VPCを指定するためのデータソース data "aws_vpc" "default" { default = true }
同じドメインでパブリックホストゾーンとプライベートホストゾーンを出し分けるためにプライベートホストゾーン用のExternalDNSを新たに作成します12。以下のオプションで起動します。
--aws-zone-type=private--annotation-filter=alb.ingress.kubernetes.io/scheme=internal--domain-filter=${プライベートホストゾーン名}
内部向けALBのためのアノテーションがついているリソースのみを対象に設定しています。これが、デフォルト値にもかかわらず明示的にIngressにアノテーションを設定する理由です。
元々起動していたパブリックホストゾーン用のExternalDNSには--annotation-filter=alb.ingress.kubernetes.io/scheme=internet-facingを用いて再起動し、インターネット向けALB用のリソースのみを対象にします。
ExternalDNSの準備ができたら内部向け用IngressをEKS内に作成し、内部向けALBとALBのエイリアスレコードが作成されていることを確認します。一時的に関連付けておいたVPC内部からdigコマンド等で名前解決し、プライベートアドレスに解決されることも確認しておきます。確認後、プライベートホストゾーンをEKSのVPCに関連付けし、一時的なVPCの関連付けは解除します。
以下にサンプルコードを記載します。ここでは、プライベートホストゾーンに関連付けされているVPCを、使用していないVPCからvariablesに設定されたEKSのVPCに変更しています。
variable "vpc_id" { type = string description = "EKSのVPC ID" } resource "aws_route53_zone" "private_api" { name = "api.wear.jp" vpc { vpc_id = var.vpc_id vpc_region = "ap-northeast-1" } force_destroy = false }
最終的な通信経路の概略は以下の図の通りです。これで、WEARのWebアプリケーションからAPIへの通信がVPC内部で完結するように設定できました。
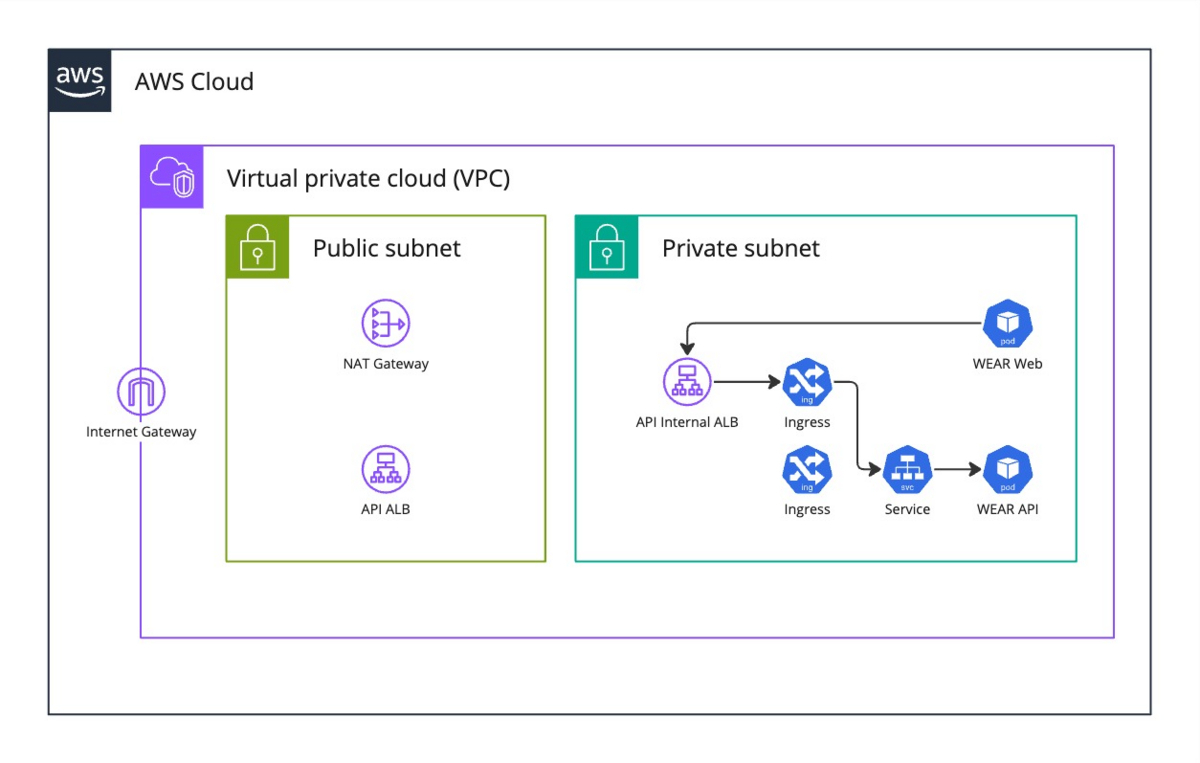
ECRパブリックリポジトリとの通信
WEARでは、aws-for-fluent-bitを初めとする、複数のコンテナイメージでECRパブリックリポジトリのものを多用しています。ドキュメントには以下のような記載があります。
現在、VPC エンドポイントは Amazon ECR パブリックリポジトリをサポートしていません。プルスルーキャッシュルールを使用して、VPC エンドポイントと同じリージョンにあるプライベートリポジトリでパブリックイメージをホストすることを検討してください。
上記の案内通り、プルスルーキャッシュルールを使用することにします。プルスルーキャッシュルールを使用すると、DockerHubやECRパブリックなどにあるリポジトリを自分のAWSアカウントのプライベートリポジトリにキャッシュしておくことができます。あらかじめ手動でイメージをプッシュしておく必要はなく、自分のリポジトリからプルしようとした際にイメージが存在しなければ、自動的に設定先のリポジトリからプルしてイメージを格納しておいてくれます。
詳細はドキュメントをご参照ください。また、WEARではAmazon Elastic Container Registry(以下、ECR)用のVPCエンドポイントはすでに作成してあったため、新たに作成する必要はありませんでした。
以下にTerraformを用いたサンプルコードを記載します。
resource "aws_ecr_pull_through_cache_rule" "ecr_public" { ecr_repository_prefix = "ecr-public" upstream_registry_url = "public.ecr.aws" }
設定完了後、マニフェストのイメージを以下のように書き換えます。$ACCOUNT_IDはプライベートリポジトリが存在するAWSアカウントのIDです。また、WEARでは元々DatadogのコンテナイメージをHelmのデフォルト値であるgcr.io/datadoghqからプルしていましたが、このタイミングでECRに切り替えました13。
- image: public.ecr.aws/aws-observability/aws-for-fluent-bit + image: $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com/ecr-public/aws-observability/aws-for-fluent-bit
これで、初回プル時にはNATゲートウェイを経由してイメージがプルされますが、その後はVPCエンドポイント経由でプライベートリポジトリからプルされるようになりました。
結果
対応完了後、NATゲートウェイを経由する通信量がどのくらい減ったのかを確認します。まずは、以下のクエリでVPC内部からNATゲートウェイを経由した外向きの通信に対して対応前後の削減量を確認します14。
SELECT B.pkt_dst_aws_service AS pkt_dst_aws_service, ROUND(CAST(B.bytes_day-COALESCE(A.bytes_day, 0) AS double)/B.bytes_day*100, 2) AS Reduction_percentage FROM ( SELECT pkt_dst_aws_service, SUM(bytes) AS bytes_day FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 対応前の日付(UTC) GROUP BY pkt_dst_aws_service ) B LEFT JOIN ( SELECT pkt_dst_aws_service, SUM(bytes) AS bytes_day FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 対応後の日付(UTC) GROUP BY pkt_dst_aws_service ) A ON B.pkt_dst_aws_service = A.pkt_dst_aws_service ORDER BY B.bytes_day DESC
| pkt_dst_aws_service | Reduction_percentage |
|---|---|
| AMAZON | 99.91 |
| EC2 | -2.82 |
| - | -2.14 |
| DYNAMODB | 100.0 |
| CLOUDFRONT | 93.75 |
| GLOBALACCELERATOR | 100.0 |
結果を確認すると、AMAZONへの通信量が99.91%、CLOUDFRONTが93.75%、DYNAMODBへの通信量が100.0%削減できていることがわかりました。VPCエンドポイントがうまく作用しているようです。増えている箇所もありますが、通信量は日によって誤差があるため対応によるものではありません。NATゲートウェイを経由してVPC内部に受信する通信に関しても確認します。
NATゲートウェイを経由する内向き通信の削減量確認クエリ
SELECT B.pkt_src_aws_service AS pkt_src_aws_service, ROUND(CAST(B.bytes_day-COALESCE(A.bytes_day, 0) AS double)/B.bytes_day*100, 2) AS Reduction_percentage FROM ( SELECT pkt_src_aws_service, SUM(bytes) AS bytes_day FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr NOT LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 対応前の日付(UTC) GROUP BY pkt_src_aws_service ) B LEFT JOIN ( SELECT pkt_src_aws_service, SUM(bytes) AS bytes_day FROM "vpc_flow_logs_database"."vpc_flow_logs_table" -- VPCフローログテーブルが存在するデータベース.VPCフローログテーブル WHERE srcaddr NOT LIKE 'x.y.%' -- VPC CIDRのネットワーク部分(例:VPC CIDRが`172.168.0.0/16`の時、`172.168.`) AND dstaddr in ('x.y.a.b', 'x.y.c.d', 'x.y.e.f') -- NatGateway IP AND action = 'ACCEPT' AND logdate BETWEEN 'YYYY/MM/dd/00' AND 'YYYY/MM/dd/23' -- 対応後の日付(UTC) GROUP BY pkt_src_aws_service ) A ON B.pkt_src_aws_service = A.pkt_src_aws_service ORDER BY B.bytes_day DESC
結果は以下の通りです。WEARのAPI(EC2)への通信がVPC内部で完結したこと、プルスルーキャッシュルールによってCLOUDFRONTや外部サービスへの通信回数が減ったことで通信量が大幅に減っています。
| pkt_src_aws_service | Reduction_percentage |
|---|---|
| EC2 | 89.15 |
| AMAZON | 98.22 |
| - | 63.65 |
| CLOUDFRONT | 99.14 |
| DYNAMODB | 100.0 |
| GLOBALACCELERATOR | 100.0 |
Cost Explorerで対応前後の1日毎のグラフを確認します。最終的に対応が完了したのは6/6頃です。グラフの通り、大幅にコストを減らせました。NATゲートウェイのコストだけで言うと、80%ほど削減できました。
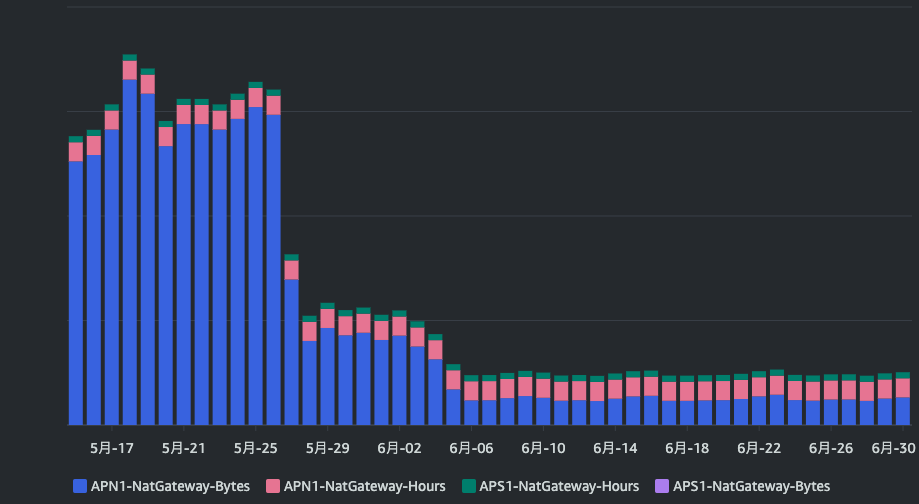
しかし、NATゲートウェイを経由しなくなった分、VPCエンドポイントのコストが増えているはずです。そちらも確認します。APIオペレーションに『VpcEndpoint』も追加し、グラフを確認します。
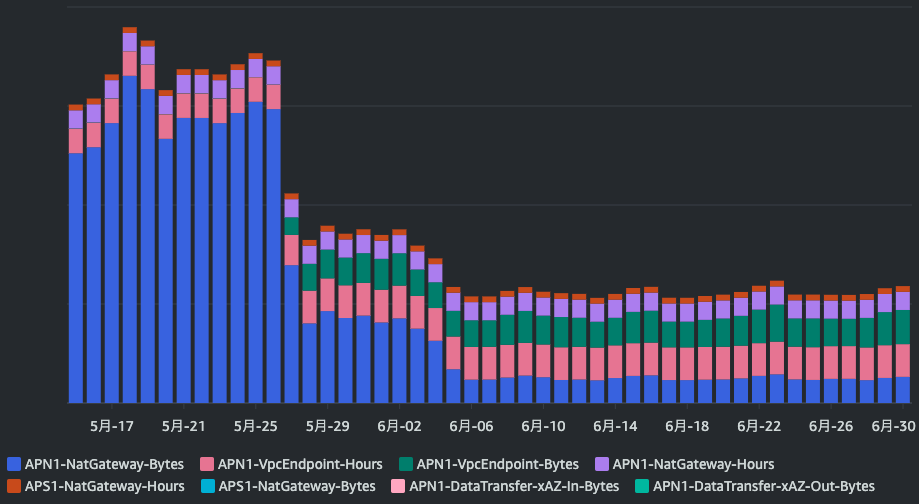
VPCエンドポイントの通信コストを加味しても、コストを大幅に削減できています。対応前のNATゲートウェイとVPCエンドポイントの総額で計算すると、最終的には60%ほど削減できました。
まとめ
本記事ではNATゲートウェイの通信内容の調査と通信量の削減方法について紹介しました。VPCフローログとリゾルバーのクエリログを確認することで詳細な通信内容を把握できました。通信内容に応じて適切な対応をした結果、約60%のコストを削減できました。NATゲートウェイのコスト削減を検討している方がいれば、ぜひ参考にしてみてください。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。
- 結果画像のy軸はマスク処理を施してあります。今後出てくるCost Explorerの画像はすべてy軸がマスク処理済みのものです。↩
- Amazon VPC フローログのクエリ↩
- 参考:サンプルクエリ - Amazon CloudWatch Logs↩
-
ここでのAWSサービスはすべてのサービス名ではなく、VPCフローログの
pkt-src-aws-serviceフィールドの値で表示されるもの(参考:VPC フローログを使用した IP トラフィックのログ記録 - Amazon Virtual Private Cloud)↩ - Amazon Athena の料金↩
-
Datadogへの通信は、ほとんどが
pkt_src_aws_service = 'EC2'に内包されています。↩ -
わかりやすさのため
pkt_dst_aws_serviceごとにクエリを実行していますが、このカラムにはパーティションが設定されていないため、この条件句によってスキャン量を減らすことはできません。Athenaのスキャン量による料金を減らしたい場合、pkt_dst_aws_serviceにパーティションを設定することを検討するか、この条件を削除し、1回のクエリですべてを出力してください。↩ - ゲートウェイエンドポイント - Amazon Virtual Private Cloud↩
- AWS PrivateLink を介して Datadog に接続する↩
- 背景:WEAR Webフロントエンドリプレイスのアーキテクチャ選定とNext.jsへの移行↩
-
キー名:
kubernetes.io/role/internal-elb、値:1のタグが必要(参考:Amazon EKS でのアプリケーション負荷分散)↩ - 参考:ExternalDNSでPrivate Hosted ZoneとPublic Hosted Zoneにレコードを出し分ける | DevelopersIO↩
- Docker 環境のコンテナイメージ↩
- わかりやすさのために1つのクエリにしていますが、対応前の結果は最初にクエリした際どこかにメモしておき、対応後の日付だけクエリして手動で比較する方がAthenaの料金上良いと思います。↩