



はじめに
こんにちは。ZOZOテクノロジーズBtoB開発部の三好です。
今回はServerlessなシステムの監視、保守、運用を行う中で、これまでやってきたことや、その反省点などを紹介します。マネージドサービスでの開発・運用で同じ苦悩をされている、もしくはこれからマネージドサービスを利用して構築する方々の参考になれば幸いです。
サービス紹介
私の所属するBtoB開発部は、Fulfillment by ZOZO(以下FBZ)を提供しています。FBZはZOZOBASEと自社EC、店舗の在庫を一元化し、在庫切れの無い世界を実現するためのサービスです。
その中で、ZOZOBASEと自社ECをつなげるためのデータ連携API開発を担っています。
なぜ監視をするのか
私たちは、日々APIが正常に稼働しているか、不正なデータが発生していないかを監視してます。マネージドなサービスを使って、Serverlessなシステムと聞くと、保守は不要と思われる方もいらっしゃるかもしれません。
しかし、想定していない運用によるイレギュラーデータへのリカバリ対応や、プログラムのバグはありえます。さらに、高負荷による処理遅延の発生などシステムの監視、保守は必要になります。
安定したユーザー体験を実現するために私たちは日々システム監視を続けています。
監視の基本的な仕組み
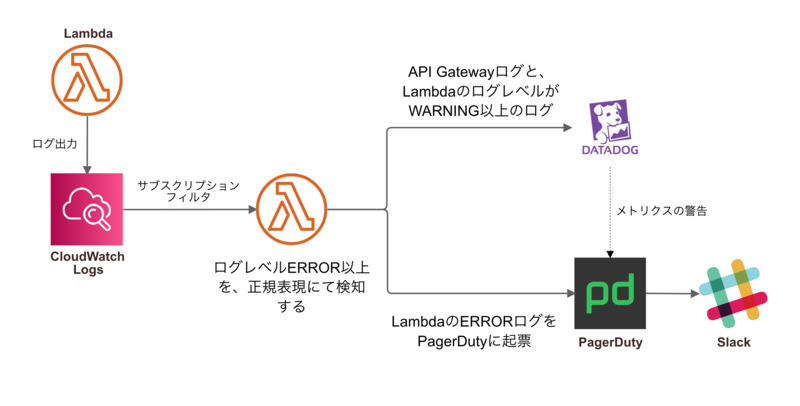
私たちはAPIサービスを開発し運用をしておりますが、FBZのAPIは、AWSのLambda + API Gateway + その他マネージドサービスにて構成されています。その中でも今回はLambdaのログ監視について紹介させていただきたいと思います。
Lambdaでは、CloudWatch Logsにログを出力してます。Lambda内でINFO、WARNING、ERROR等のログレベルを設定した上でCloudWatch Logsにログ出力をするような仕組みになっています。
CloudWatch Logsではロググループに対し「サブスクリプションフィルタ」を設定できます。サブスクリプションフィルタにLambdaを設定すると、出力されたログをLambdaで処理する事ができます。
FBZのAPIではこの機能を使ってERRORログを検知し、検知したERRORログをPagerDuty、Datadogに通知する仕組みを組んでいます。
これをベースにエラーを検知し監視対応を行っています。
運用で発生した課題
この仕組みでしばらく運用した結果「エラーのノイズが多く対応しきれない」といった課題が発生しました。
サービスの成長と共にエラーが増大していきました。一番多い時では一日に起票されるエラーが何百というレベルで、常にPagerDutyの通知がされているような状態でした。
こういった状況が続くと以下のような状態になってきます。
- 数が多すぎる上に、ほとんどノイズなので次第に見なくなる
- 本当に対応すべきエラーが埋もれる
- リカバリや修正対応が遅くなり、外部や運用者に迷惑をかけてしまう
エラーノイズが増えてしまっていた原因
なぜノイズが増えてしまっていたのかを考察した結果、主な原因は以下の3つでした。
- そもそものログレベル設定が間違っている
- ログレベルの変更で対応できないエラーの存在
- ノイズをフィルタをすることへのハードルが高い
1. そもそものログレベル設定が間違っている
WARNINGやINFOで良いものまでERRORで出力されている状態でした。例外が発生した場合はほぼ全てがERRORログとして出力されている状態で、適切なログレベルが設定されている状態ではありませんでした。
2. ログレベルの変更で対応できないエラーの存在
Lambdaに記述したコード内でハンドリングできているエラーの場合は適切にログレベルが設定され通知されます。しかし、開発者がエラーハンドリングできない部分で発生したエラーについては、そもそもログレベルが設定できません。
例えば、メモリエラーやタイムアウトエラー、importエラーなどがこれに該当します。これらはログレベルが設定できないエラーであるため、発生を知らせる特定の文字列を元に検知する仕組みでした。
Lambdaのタイムアウトであれば、Task timed out after X secondsが検出されたらエラーとして通知するといった仕組みでした。そのため、Lambda関数毎に検知する、しないの制御ができていませんでした。
3. フィルタを適用することへのハードルが高い
元々エラー検知されてノイズと判定されたものは、PagerDutyのフィルタ機能を使ってフィルタを行なっていました。
しかし、PagerDutyのフィルタではシンプルな条件でしかフィルタをできないため、特定のLambdaの特定のエラーのみフィルタするなど細かな制御ができませんでした。
また、PagerDutyでは実際にフィルタされたものの確認ができません。本来検知するべきだったエラーまでフィルタしてないだろうかという不安が常にありました。
上記のような理由から、PagerDutyのフィルタ機能は積極的には利用されず、結果ノイズとして残ってしまっている状態でした。
解決に向けたアクション
これらの課題を解決するために、以下の2つのアクションをとりました。
- ログレベルの見直し
- フィルター機能の強化
根本的な解決としては、ログレベルを適切に設定する事を目標としました。ただ、ログレベルの見直しでは改善できないノイズを削減するために、フィルタ機能を強化するアクションも合わせて行いました。
ログレベルの見直し
まず行ったのは、ログレベルの見直しです。ほぼ全てがERRORとして出力されている状態から、ノイズとなっているログのログレベルを見直し、PagerDutyへ通知されないようにしました。
フィルター機能の強化
ログレベルの見直しでは解決できないノイズを削減するためにフィルタ機能の強化を行いました。大まかなアーキテクチャとしては以下の図のようになります。これまでERROR文字列を検知してPagerDuty、Datadogに通知していた機能を拡張し、この部分にフィルタ機能をもたせました。
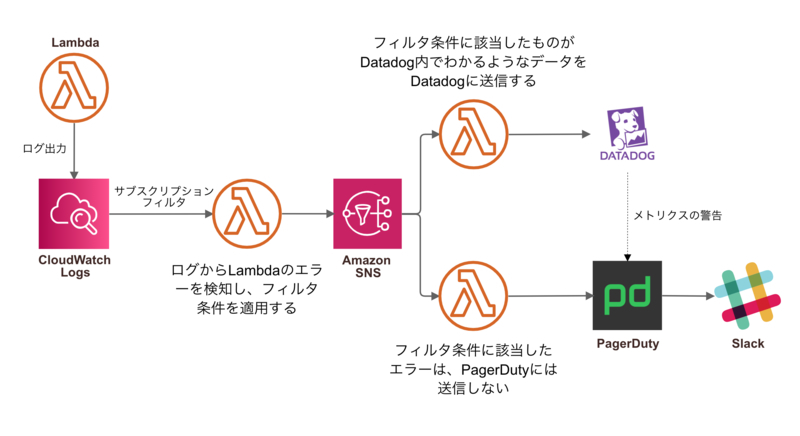
フィルタのためのロジックはPythonで記述しています。当初設定値としてコード外で管理する案もあったのですが、自由度と後述する自動テストを入れるという観点からPythonにてロジックを記述しています。
また、エラーをフィルタするハードルを下げるために、工夫した点が2つあります。
1点目はフィルタのロジックに対して自動テストを書いていることです。フィルタをする際、本来通知されるべきものまでフィルタしてないか不安になります。ロジックの正当性を担保するため、フィルタの追加と共に自動テストも追加しました。
2点目はフィルタした結果が分かるようにしたことです。フィルタを導入した後に想定している件数とのギャップがないかを確認する目的と、フィルタした件数をLambda毎に集計し異常値検出をする目的です。
運用から得た教訓(みんなの安眠のために)
上記のようなアクションをとった結果、最大500件近く起票されていたエラーを少ない日は数件という程度に抑えることができました。
そして、運用をしていく中で以下の教訓を得ることができました。
エラー出力をする前に、なんのために必要なのか考えないといけない
- エラーが発生したが、再実行やリトライによって成功する(成功した)エラー
- 手動でデータ補正等を行う必要があるエラー
- 再実行やリカバリは不要・できないが、見逃せないエラー(バグなど)
- etc.
様々なパターンがありますが、よく自分も陥りがちなのは、「色々な例外がありそうだからとりあえずERROR出力をする」といったパターンです。とりあえず設定したログレベルは、一度リリースされると改修による不具合発生のリスクや、リソースの都合でななかな変更できない事が多いと思います。
本当に検知や対処が必要なものであればERROR出力は必要です。しかし、ERROR通知を受けた後何もしないのであれば、通知する必要はないのかもしれません。実装の時点で、検知したエラーを元に何をしたいのかを考慮した上で適切なログレベルをつける事が大切です。
ノイズは放置しない
ノイズが多いという場合、ほとんどが急に発生したものではなく時間をかけて蓄積されたものです。少ないノイズだからと放置すると、いつの間にかノイズだらけ、という状態になります。
ただ、ノイズとして残っているものがある場合、除去できない理由があるのかもしれません。今回はフィルタを作成する事でノイズを除去する事ができました。
今ノイズとして残っている理由を見極め、効果のあるところから地道に改善していくという事の大切さを実感しました。
これからやっていきたいこと
今回はノイズへの対策をメインに紹介させていただきましたが、これからやりたい事はたくさんあります。
- エラー発生後に自動でリカバリをする仕組みの構築
- インシデントの適切な優先度付け
- SREチームとの連携
上記にあげたような、そもそもエラーとして検知しなくて済む仕組み作りや、検知後の運用がスムーズに回る仕組みなどに注力できればと考えています。
現状監視できていない部分や、そのリスクを把握しながら、逐次改善のアクションへとつなげていきたいです。ちょっとした改善で劇的に変わるものもあれば、なかなか手強い解決できない課題もあります。日々挑戦しながら、改善を進めていきたいと思っています。
さいごに
私たちは、AWSのマネージドサービスをフル活用し、ServerlessなAPIサービスを提供しています。失敗と成功を繰り返して、エンジニアとしてのスキルアップを目指しています。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!